Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
2406.01607
0
0

Abstract
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
Create account to get full access
Overview
- This paper provides a comprehensive review of the top-performing text embedding methods on the Massive Text Embedding Benchmark (MTEB).
- Text embeddings are numerical representations of text that capture the semantic meaning and relationships between words, sentences, and documents.
- The MTEB benchmark evaluates the performance of text embedding models across a diverse set of tasks, including text classification, similarity, and retrieval.
- The authors examine the latest advancements in text embedding techniques, highlighting the strengths and weaknesses of the top-performing methods.
Plain English Explanation
Text embeddings are a way of representing words, sentences, and documents as numerical values that capture their meaning and relationship to other text. This is a fundamental technique in natural language processing that enables a wide range of applications, from text clustering to language model enhancement.
The Massive Text Embedding Benchmark (MTEB) is a comprehensive evaluation tool that assesses the performance of text embedding models across a diverse set of real-world tasks, such as classifying the sentiment of a piece of text or determining how similar two documents are. By testing the models on this broad range of tasks, the MTEB provides a reliable way to compare the capabilities of different text embedding techniques.
In this paper, the authors review the top-performing text embedding methods on the MTEB, explaining how they work and highlighting their strengths and weaknesses. For example, some models may excel at capturing the nuanced meanings of words, while others are better at understanding the overall context of a piece of text. By understanding the tradeoffs between these different approaches, researchers and practitioners can choose the most appropriate text embedding model for their specific needs.
The authors' comprehensive review of the state-of-the-art in text embedding technology can help guide the development of more advanced language models and benchmarks for other languages, ultimately leading to more powerful and versatile natural language processing systems.
Technical Explanation
The paper presents a thorough evaluation of the top-performing text embedding methods on the Massive Text Embedding Benchmark (MTEB). MTEB is a comprehensive benchmark that assesses the performance of text embedding models across a diverse set of tasks, including text classification, similarity, and retrieval.
The authors first provide an overview of the MTEB benchmark, explaining the various tasks and datasets it covers. They then review the latest advancements in text embedding techniques, such as large language model-based embeddings and specialized embeddings for specific languages.
For each top-performing text embedding method, the authors describe the underlying architecture and training approach, as well as its strengths and weaknesses. They analyze the models' performance on the MTEB tasks, providing insights into the types of text-related problems each model is best suited for.
The paper also discusses the potential of combining different text embedding techniques to leverage their complementary strengths and improve the overall performance of language models.
Critical Analysis
The paper provides a comprehensive and well-structured review of the top-performing text embedding methods on the MTEB benchmark. The authors have done an excellent job of capturing the key characteristics and capabilities of each model, as well as their relative strengths and weaknesses.
One potential limitation of the study is that it focuses solely on the MTEB benchmark, which, while extensive, may not capture all the nuances and real-world applications of text embedding models. It would be interesting to see how the reviewed methods perform on other benchmarks or in more practical, industry-specific tasks.
Additionally, the paper does not delve deeply into the underlying architectures and training approaches of the text embedding models. While the high-level descriptions are informative, a more technical analysis of the models' inner workings could provide deeper insights for researchers and practitioners.
Overall, this paper is a valuable resource for anyone interested in the current state of text embedding technology and the relative performance of the top-performing methods. The authors have done an excellent job of synthesizing a complex and rapidly evolving field into a clear and concise review.
Conclusion
This comprehensive review of the top-performing text embedding methods on the Massive Text Embedding Benchmark (MTEB) provides valuable insights into the latest advancements in this critical area of natural language processing. By examining the strengths and weaknesses of each model, the authors enable researchers and practitioners to make informed decisions about which text embedding techniques are best suited for their specific needs.
The findings from this paper can help drive the development of more advanced language models and expanded benchmarks for other languages, ultimately leading to more powerful and versatile natural language processing systems. The authors' insights into the potential of combining different text embedding techniques and improving the overall performance of language models are particularly promising for the future of the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Nicholas Harris, Anand Butani, Syed Hashmy
0
0
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
4/19/2024

Improving Text Embeddings with Large Language Models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei
0
0
In this paper, we introduce a novel and simple method for obtaining high-quality text embeddings using only synthetic data and less than 1k training steps. Unlike existing methods that often depend on multi-stage intermediate pre-training with billions of weakly-supervised text pairs, followed by fine-tuning with a few labeled datasets, our method does not require building complex training pipelines or relying on manually collected datasets that are often constrained by task diversity and language coverage. We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across 93 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss. Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labeled data. Furthermore, when fine-tuned with a mixture of synthetic and labeled data, our model sets new state-of-the-art results on the BEIR and MTEB benchmarks.
6/3/2024
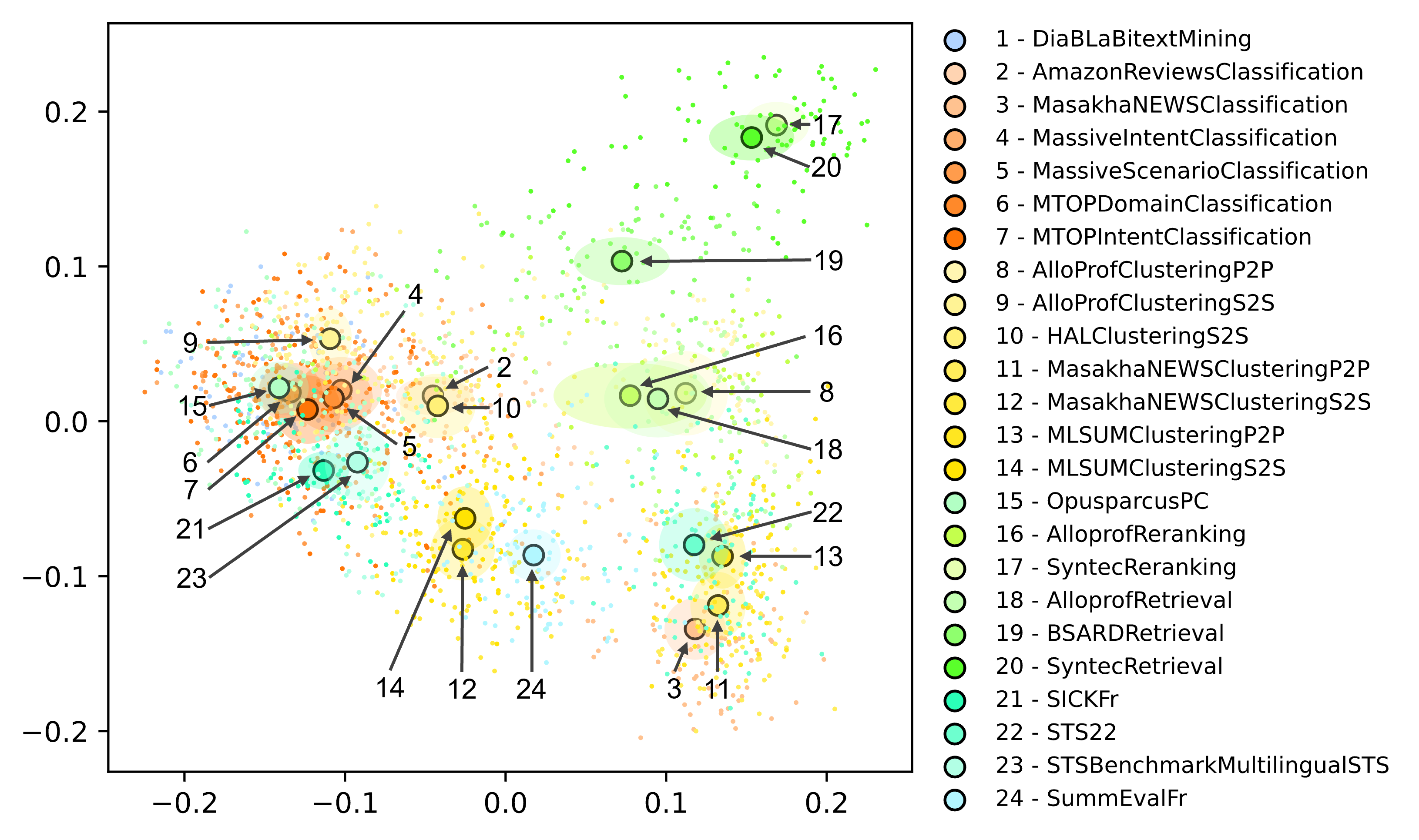
Extending the Massive Text Embedding Benchmark to French
Mathieu Ciancone, Imene Kerboua, Marion Schaeffer, Wissam Siblini
0
0
Recently, numerous embedding models have been made available and widely used for various NLP tasks. The Massive Text Embedding Benchmark (MTEB) has primarily simplified the process of choosing a model that performs well for several tasks in English, but extensions to other languages remain challenging. This is why we expand MTEB to propose the first massive benchmark of sentence embeddings for French. We gather 15 existing datasets in an easy-to-use interface and create three new French datasets for a global evaluation of 8 task categories. We compare 51 carefully selected embedding models on a large scale, conduct comprehensive statistical tests, and analyze the correlation between model performance and many of their characteristics. We find out that even if no model is the best on all tasks, large multilingual models pre-trained on sentence similarity perform exceptionally well. Our work comes with open-source code, new datasets and a public leaderboard.
6/18/2024
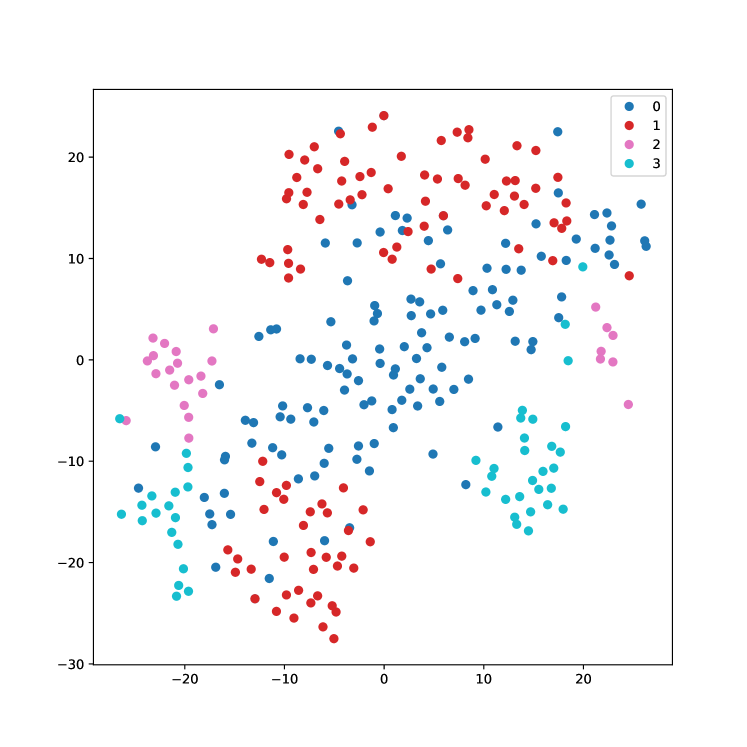
Text clustering with LLM embeddings
Alina Petukhova, Jo~ao P. Matos-Carvalho, Nuno Fachada
0
0
Text clustering is an important approach for organising the growing amount of digital content, helping to structure and find hidden patterns in uncategorised data. However, the effectiveness of text clustering heavily relies on the choice of textual embeddings and clustering algorithms. We argue that recent advances in large language models (LLMs) can potentially improve this task. In this research, we investigated how different textual embeddings -- particularly those used in LLMs -- and clustering algorithms affect how text datasets are clustered. A series of experiments were conducted to assess how embeddings influence clustering results, the role played by dimensionality reduction through summarisation, and model size adjustment. Findings reveal that LLM embeddings excel at capturing subtleties in structured language, while BERT leads the lightweight options in performance. In addition, we observe that increasing model dimensionality and employing summarization techniques do not consistently lead to improvements in clustering efficiency, suggesting that these strategies require careful analysis to use in real-life models. These results highlight a complex balance between the need for refined text representation and computational feasibility in text clustering applications. This study extends traditional text clustering frameworks by incorporating embeddings from LLMs, providing a path for improved methodologies, while informing new avenues for future research in various types of textual analysis.
5/31/2024