Improving Text Embeddings with Large Language Models

33

Sign in to get full access
Overview
- The paper explores techniques for improving text embeddings, which are numerical representations of text that can be used in various natural language processing tasks.
- The researchers propose using large language models, which are powerful AI systems trained on vast amounts of text data, to enhance the quality of text embeddings.
- The paper presents a method for generating synthetic data to fine-tune large language models and improve their text embedding capabilities.
- The researchers also discuss related work in the field of text embedding enhancement and the potential benefits of their approach.
Plain English Explanation
The paper is about a way to make text embeddings better. Text embeddings are numbers that represent words or phrases, and they're used in all kinds of language AI tasks. The researchers found that using big, powerful language models - the kind that can write whole essays - can help improve these text embeddings.
They have a method where they generate fake text data and use it to fine-tune the language models. This helps the models learn even better ways to turn text into useful numbers. The researchers explain how this builds on previous work in this area, and they discuss the potential benefits of their approach.
Technical Explanation
The paper presents a method for improving text embeddings using large language models. Text embeddings are numerical representations of text that capture semantic and syntactic information, and they are a crucial component in many natural language processing tasks.
The researchers propose fine-tuning large language models, such as GPT-2 and BERT, on synthetic data generated using techniques like data augmentation and back-translation. This fine-tuning process allows the language models to learn better representations of text, which can then be used to generate high-quality text embeddings.
The researchers evaluate their approach on several standard text embedding benchmarks and find that it outperforms previous methods, including those that directly fine-tune the language models on downstream tasks.
Critical Analysis
The paper presents a promising approach for improving text embeddings, but it also acknowledges several limitations and areas for further research. One limitation is that the method relies on the availability of large, high-quality language models, which may not be accessible to all researchers and developers.
Additionally, the researchers note that the performance of their approach may be sensitive to the quality and diversity of the synthetic data used for fine-tuning. Generating high-quality synthetic data that is representative of real-world text can be challenging, and this could impact the effectiveness of the method.
Furthermore, the paper does not explore the potential biases or fairness implications of using large language models, which are known to exhibit biases present in their training data. This is an important consideration that should be addressed in future research on this topic.
Conclusion
Overall, the paper presents a novel approach for enhancing text embeddings using large language models and synthetic data generation. The researchers demonstrate promising results and highlight the potential benefits of their method, which could have wide-ranging applications in natural language processing and beyond.
However, the work also raises important questions about the limitations and potential pitfalls of this approach, which should be carefully considered by researchers and practitioners in the field. As with any emerging technology, it is crucial to think critically about the implications and to continue exploring ways to improve the robustness and fairness of text embedding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
33
Improving Text Embeddings with Large Language Models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei
In this paper, we introduce a novel and simple method for obtaining high-quality text embeddings using only synthetic data and less than 1k training steps. Unlike existing methods that often depend on multi-stage intermediate pre-training with billions of weakly-supervised text pairs, followed by fine-tuning with a few labeled datasets, our method does not require building complex training pipelines or relying on manually collected datasets that are often constrained by task diversity and language coverage. We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across 93 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss. Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labeled data. Furthermore, when fine-tuned with a mixture of synthetic and labeled data, our model sets new state-of-the-art results on the BEIR and MTEB benchmarks.
Read more6/3/2024
🚀
0
Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Nicholas Harris, Anand Butani, Syed Hashmy
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
Read more4/19/2024
0
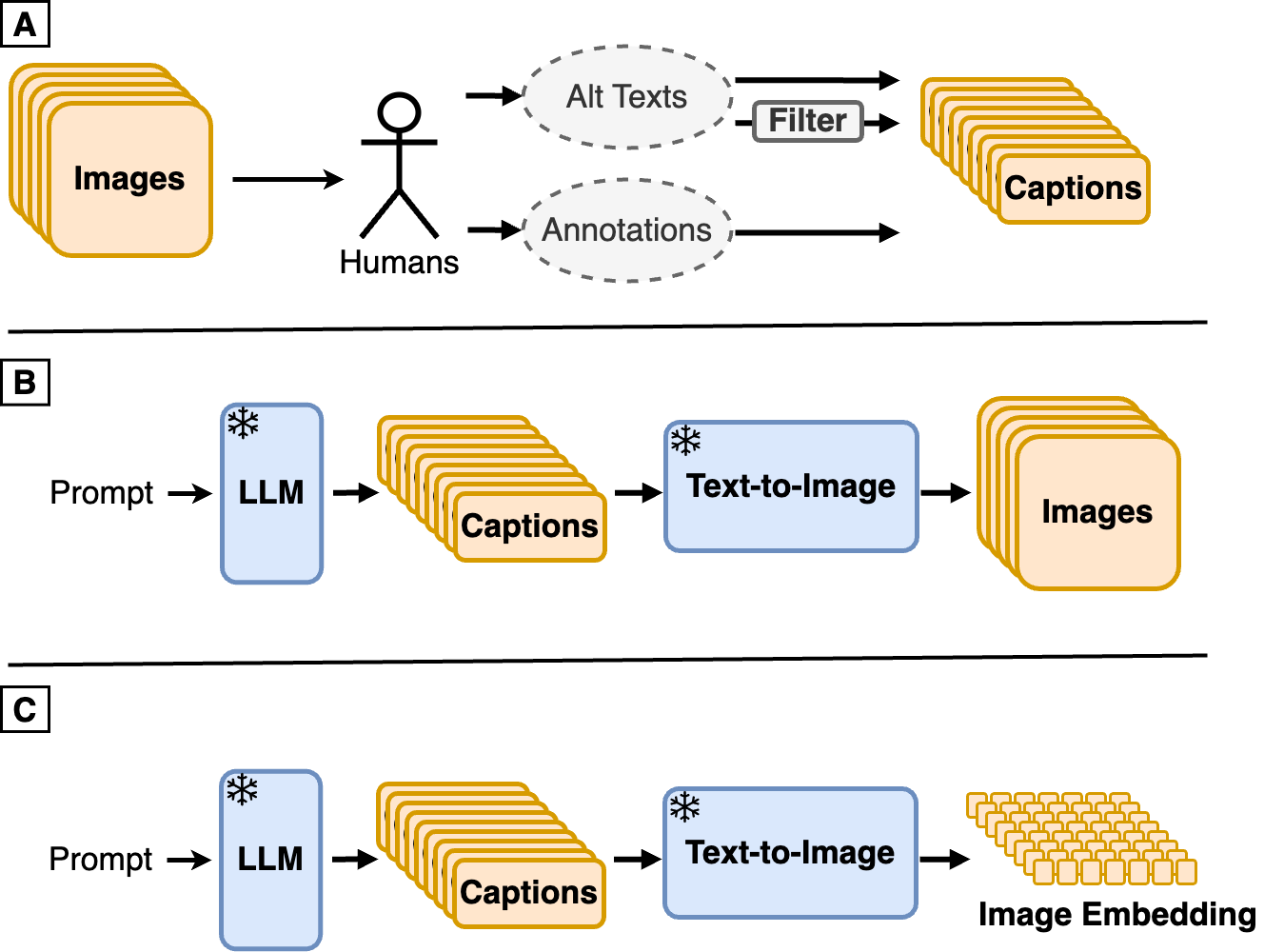
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Read more6/10/2024

0
Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
Hongliu Cao
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
Read more6/21/2024