A Recipe for Unbounded Data Augmentation in Visual Reinforcement Learning
2405.17416
0
0

Abstract
$Q$-learning algorithms are appealing for real-world applications due to their data-efficiency, but they are very prone to overfitting and training instabilities when trained from visual observations. Prior work, namely SVEA, finds that selective application of data augmentation can improve the visual generalization of RL agents without destabilizing training. We revisit its recipe for data augmentation, and find an assumption that limits its effectiveness to augmentations of a photometric nature. Addressing these limitations, we propose a generalized recipe, SADA, that works with wider varieties of augmentations. We benchmark its effectiveness on DMC-GB2 -- our proposed extension of the popular DMControl Generalization Benchmark -- as well as tasks from Meta-World and the Distracting Control Suite, and find that our method, SADA, greatly improves training stability and generalization of RL agents across a diverse set of augmentations. Visualizations, code, and benchmark: see https://aalmuzairee.github.io/SADA/
Create account to get full access
Overview
- This paper presents a novel approach for data augmentation in visual reinforcement learning (RL) tasks.
- The proposed method, called AdaAugment, adapts the data augmentation process to the current state of the RL agent's learning, allowing for unbounded and more effective augmentation.
- The authors demonstrate the effectiveness of AdaAugment on several challenging visual RL environments, showing significant performance improvements over standard data augmentation techniques.
Plain English Explanation
In the world of reinforcement learning (RL), where agents learn to perform tasks by interacting with their environment, the quality and quantity of training data can make a big difference in their performance. AdaAugment: Tuning-Free Adaptive Approach to Enhance Data Augmentation introduces a new way to generate more training data through a technique called "data augmentation."
Data augmentation involves creating new, realistic-looking training examples by applying various transformations, such as rotating, scaling, or adding noise to the original data. This can help the RL agent learn more effectively and generalize better to new situations.
However, standard data augmentation techniques often use pre-defined transformations that don't adapt to the agent's current learning progress. AdaAugment addresses this by continuously adjusting the data augmentation process to match the agent's needs, allowing for more effective and "unbounded" augmentation.
The authors demonstrate the power of AdaAugment by applying it to several challenging visual RL environments, such as maze navigation and robotic manipulation tasks. The results show that AdaAugment significantly outperforms traditional data augmentation techniques, helping RL agents learn more effectively and achieve better overall performance.
Technical Explanation
The core idea behind AdaAugment is to adapt the data augmentation process to the current state of the RL agent's learning. Instead of using pre-defined, static transformations, the authors propose a method that dynamically generates new augmented samples based on the agent's performance and the diversity of the current training data.
The key components of AdaAugment are:
-
Diversity Estimation: The authors introduce a novel diversity measure to quantify the variety of the current training data. This allows the system to identify areas of the input space that are underrepresented and need more augmentation.
-
Performance Estimation: The authors also estimate the agent's current performance on the task, which helps determine the appropriate level of augmentation needed to further improve the agent's capabilities.
-
Adaptive Augmentation: Based on the diversity and performance estimates, AdaAugment dynamically generates new augmented samples, adjusting the type and intensity of the transformations to match the agent's current learning state.
The authors evaluate AdaAugment on several challenging visual RL tasks, including Improving Generalization of Game Agents through Data Augmentation and Imitation, Comparative Study on Enhancing Prediction in Social Network Advertisement, GTA: Generative Trajectory Augmentation for Guidance in Offline Reinforcement Learning, and Boosting Model Resilience via Implicit Adversarial Data. The results demonstrate that AdaAugment significantly outperforms standard data augmentation techniques, leading to faster learning and higher final performance for the RL agents.
Critical Analysis
The AdaAugment approach presents a promising solution for improving data augmentation in visual reinforcement learning. By adapting the augmentation process to the agent's current learning state, the method can generate more effective and diverse training data, leading to significant performance gains.
However, the paper does not address the computational cost of the additional diversity and performance estimation modules, which could potentially slow down the overall training process. Additionally, the authors do not explore how AdaAugment might perform in more complex, real-world RL scenarios with partial observability, sparse rewards, or other challenging conditions.
Further research could investigate ways to optimize the computational efficiency of AdaAugment and explore its applicability to a broader range of RL tasks and environments. Comparisons with other advanced data augmentation techniques, such as Improving Generalization of Game Agents through Data Augmentation and Imitation or Boosting Model Resilience via Implicit Adversarial Data, would also help to further understand the strengths and limitations of the AdaAugment approach.
Conclusion
AdaAugment introduces a novel and effective approach for data augmentation in visual reinforcement learning, where the augmentation process is dynamically adjusted to match the agent's current learning state. By continuously adapting the transformations applied to the training data, AdaAugment can generate more diverse and useful augmented samples, leading to significant performance improvements in challenging RL environments.
The paper's insights on the importance of adapting data augmentation techniques to the agent's learning progress could have broader implications for other areas of machine learning, where the ability to generate diverse and tailored training data can be a key factor in achieving high-performing models. As the field of reinforcement learning continues to advance, methods like AdaAugment will likely play an increasingly important role in pushing the boundaries of what's possible in areas like robotics, game AI, and decision-making systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AdaAugment: A Tuning-Free and Adaptive Approach to Enhance Data Augmentation
Suorong Yang, Peijia Li, Xin Xiong, Furao Shen, Jian Zhao
0
0
Data augmentation (DA) is widely employed to improve the generalization performance of deep models. However, most existing DA methods use augmentation operations with random magnitudes throughout training. While this fosters diversity, it can also inevitably introduce uncontrolled variability in augmented data, which may cause misalignment with the evolving training status of the target models. Both theoretical and empirical findings suggest that this misalignment increases the risks of underfitting and overfitting. To address these limitations, we propose AdaAugment, an innovative and tuning-free Adaptive Augmentation method that utilizes reinforcement learning to dynamically adjust augmentation magnitudes for individual training samples based on real-time feedback from the target network. Specifically, AdaAugment features a dual-model architecture consisting of a policy network and a target network, which are jointly optimized to effectively adapt augmentation magnitudes. The policy network optimizes the variability within the augmented data, while the target network utilizes the adaptively augmented samples for training. Extensive experiments across benchmark datasets and deep architectures demonstrate that AdaAugment consistently outperforms other state-of-the-art DA methods in effectiveness while maintaining remarkable efficiency.
5/24/2024
📊
Improving Generalization in Game Agents with Data Augmentation in Imitation Learning
Derek Yadgaroff, Alessandro Sestini, Konrad Tollmar, Ayca Ozcelikkale, Linus Gissl'en
0
0
Imitation learning is an effective approach for training game-playing agents and, consequently, for efficient game production. However, generalization - the ability to perform well in related but unseen scenarios - is an essential requirement that remains an unsolved challenge for game AI. Generalization is difficult for imitation learning agents because it requires the algorithm to take meaningful actions outside of the training distribution. In this paper we propose a solution to this challenge. Inspired by the success of data augmentation in supervised learning, we augment the training data so the distribution of states and actions in the dataset better represents the real state-action distribution. This study evaluates methods for combining and applying data augmentations to observations, to improve generalization of imitation learning agents. It also provides a performance benchmark of these augmentations across several 3D environments. These results demonstrate that data augmentation is a promising framework for improving generalization in imitation learning agents.
4/9/2024
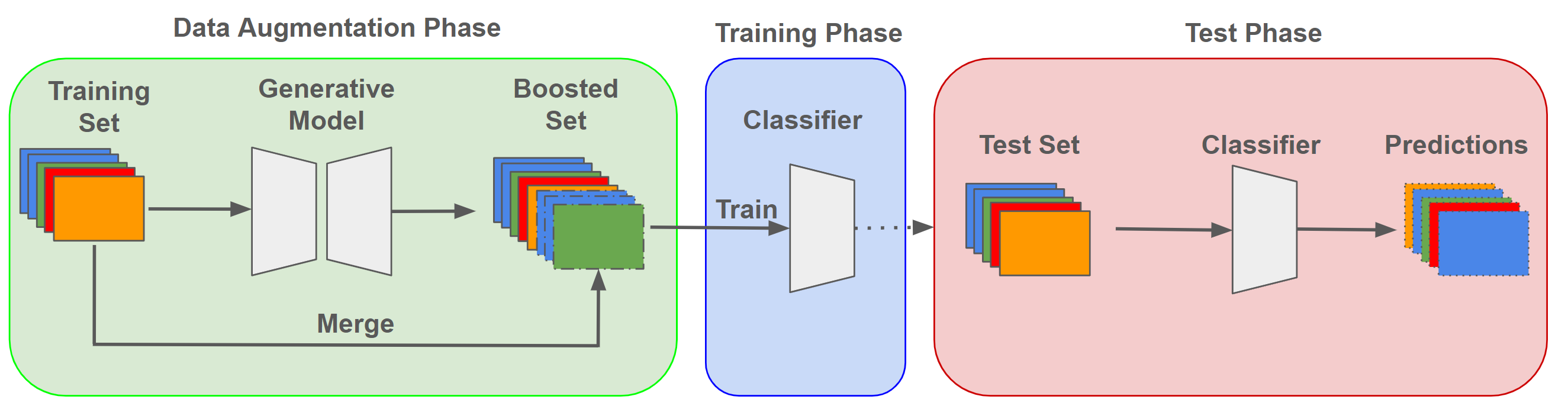
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Qikai Yang, Panfeng Li, Xinhe Xu, Zhicheng Ding, Wenjing Zhou, Yi Nian
0
0
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
4/30/2024
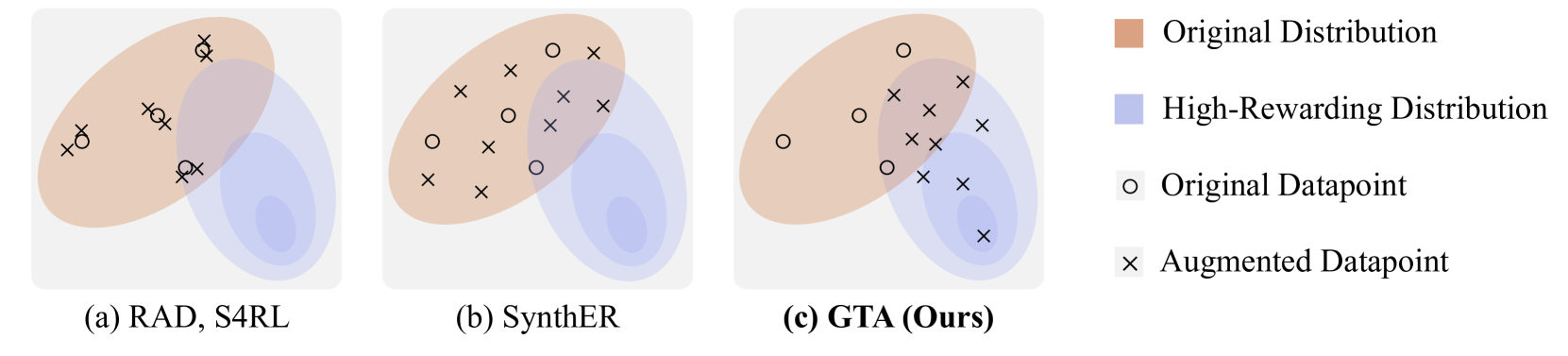
GTA: Generative Trajectory Augmentation with Guidance for Offline Reinforcement Learning
Jaewoo Lee, Sujin Yun, Taeyoung Yun, Jinkyoo Park
0
0
Offline Reinforcement Learning (Offline RL) presents challenges of learning effective decision-making policies from static datasets without any online interactions. Data augmentation techniques, such as noise injection and data synthesizing, aim to improve Q-function approximation by smoothing the learned state-action region. However, these methods often fall short of directly improving the quality of offline datasets, leading to suboptimal results. In response, we introduce textbf{GTA}, Generative Trajectory Augmentation, a novel generative data augmentation approach designed to enrich offline data by augmenting trajectories to be both high-rewarding and dynamically plausible. GTA applies a diffusion model within the data augmentation framework. GTA partially noises original trajectories and then denoises them with classifier-free guidance via conditioning on amplified return value. Our results show that GTA, as a general data augmentation strategy, enhances the performance of widely used offline RL algorithms in both dense and sparse reward settings. Furthermore, we conduct a quality analysis of data augmented by GTA and demonstrate that GTA improves the quality of the data. Our code is available at https://github.com/Jaewoopudding/GTA
6/13/2024