Reconstructing Retinal Visual Images from 3T fMRI Data Enhanced by Unsupervised Learning
2404.05107
0
0

Abstract
The reconstruction of human visual inputs from brain activity, particularly through functional Magnetic Resonance Imaging (fMRI), holds promising avenues for unraveling the mechanisms of the human visual system. Despite the significant strides made by deep learning methods in improving the quality and interpretability of visual reconstruction, there remains a substantial demand for high-quality, long-duration, subject-specific 7-Tesla fMRI experiments. The challenge arises in integrating diverse smaller 3-Tesla datasets or accommodating new subjects with brief and low-quality fMRI scans. In response to these constraints, we propose a novel framework that generates enhanced 3T fMRI data through an unsupervised Generative Adversarial Network (GAN), leveraging unpaired training across two distinct fMRI datasets in 7T and 3T, respectively. This approach aims to overcome the limitations of the scarcity of high-quality 7-Tesla data and the challenges associated with brief and low-quality scans in 3-Tesla experiments. In this paper, we demonstrate the reconstruction capabilities of the enhanced 3T fMRI data, highlighting its proficiency in generating superior input visual images compared to data-intensive methods trained and tested on a single subject.
Create account to get full access
Overview
- This paper proposes a method to reconstruct retinal visual images from 3T functional magnetic resonance imaging (fMRI) data, enhanced by unsupervised learning techniques.
- The researchers developed a deep learning model that can decode and reconstruct visual stimuli from brain activity patterns captured by fMRI.
- The model leverages unsupervised learning to extract relevant features from the fMRI data, improving the quality of the reconstructed images compared to previous approaches.
Plain English Explanation
This paper describes a new way to create images from brain activity scans. The researchers used a type of brain imaging called functional magnetic resonance imaging (fMRI) to measure the brain's response to visual stimuli. link to "Visual decoding & reconstruction via EEG embeddings guided"
They then developed a deep learning model that could analyze the fMRI data and reconstruct the original visual images that the person saw. This is like trying to draw a picture of what someone is imagining, based on the patterns of activity in their brain.
Interestingly, the researchers also used an "unsupervised learning" technique to help the model extract more useful information from the fMRI data. This allowed the reconstructed images to be of higher quality compared to previous methods that didn't use this approach.
Overall, this research represents an important step towards being able to decode and reconstruct visual experiences directly from brain activity. This could have applications in fields like neuroscience, brain-computer interfaces, and medical imaging.
Technical Explanation
The researchers used 3T fMRI data to capture the brain's responses to a set of visual stimuli. They then developed a deep learning model, consisting of an encoder and a decoder, to reconstruct the original visual images from the fMRI data.
The encoder part of the model was designed to extract relevant features from the fMRI data in an unsupervised manner, without any labels or annotations. This allowed the model to identify the most informative patterns in the brain activity that were associated with the visual stimuli.
The decoder part of the model then used these extracted features to generate reconstructions of the original visual images. The researchers compared the performance of their model to previous approaches that did not use unsupervised learning, and found that their method resulted in higher-quality image reconstructions.
Critical Analysis
The researchers acknowledge several limitations of their study. First, the fMRI data was collected at a relatively low resolution (3T), which may have limited the level of detail in the reconstructed images. Higher-resolution fMRI data, or the use of other brain imaging modalities like magnetoencephalography (MEG), could potentially improve the quality of the reconstructions.
Additionally, the study was conducted on a relatively small dataset of visual stimuli, which may not fully capture the complexity of natural visual scenes. Further research is needed to test the model's performance on a wider range of visual inputs.
Finally, the researchers did not provide a detailed analysis of the specific features that the unsupervised learning component was able to extract from the fMRI data, or how these features contributed to the improved reconstruction quality. A more thorough investigation of the model's inner workings could provide valuable insights into the neural mechanisms underlying visual perception and imagination.
Conclusion
This paper presents a novel approach to reconstructing retinal visual images from 3T fMRI data, leveraging unsupervised learning techniques to enhance the quality of the reconstructions. The findings demonstrate the potential of using brain activity patterns to decode and reconstruct visual experiences, with possible applications in fields such as neuroscience, brain-computer interfaces, and medical imaging. While the study has some limitations, it represents an important step forward in the field of visual decoding and reconstruction from brain signals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Automating the Diagnosis of Human Vision Disorders by Cross-modal 3D Generation
Li Zhang, Yuankun Yang, Ziyang Xie, Zhiyuan Yuan, Jianfeng Feng, Xiatian Zhu, Yu-Gang Jiang
0
0
Understanding the hidden mechanisms behind human's visual perception is a fundamental quest in neuroscience, underpins a wide variety of critical applications, e.g. clinical diagnosis. To that end, investigating into the neural responses of human mind activities, such as functional Magnetic Resonance Imaging (fMRI), has been a significant research vehicle. However, analyzing fMRI signals is challenging, costly, daunting, and demanding for professional training. Despite remarkable progress in artificial intelligence (AI) based fMRI analysis, existing solutions are limited and far away from being clinically meaningful. In this context, we leap forward to demonstrate how AI can go beyond the current state of the art by decoding fMRI into visually plausible 3D visuals, enabling automatic clinical analysis of fMRI data, even without healthcare professionals. Innovationally, we reformulate the task of analyzing fMRI data as a conditional 3D scene reconstruction problem. We design a novel cross-modal 3D scene representation learning method, Brain3D, that takes as input the fMRI data of a subject who was presented with a 2D object image, and yields as output the corresponding 3D object visuals. Importantly, we show that in simulated scenarios our AI agent captures the distinct functionalities of each region of human vision system as well as their intricate interplay relationships, aligning remarkably with the established discoveries of neuroscience. Non-expert diagnosis indicate that Brain3D can successfully identify the disordered brain regions, such as V1, V2, V3, V4, and the medial temporal lobe (MTL) within the human visual system. We also present results in cross-modal 3D visual construction setting, showcasing the perception quality of our 3D scene generation.
5/27/2024

Mind-to-Image: Projecting Visual Mental Imagination of the Brain from fMRI
Hugo Caselles-Dupr'e, Charles Mellerio, Paul H'erent, Aliz'ee Lopez-Persem, Benoit B'eranger, Mathieu Soularue, Pierre Fautrel, Gauthier Vernier, Matthieu Cord
0
0
The reconstruction of images observed by subjects from fMRI data collected during visual stimuli has made strong progress in the past decade, thanks to the availability of extensive fMRI datasets and advancements in generative models for image generation. However, the application of visual reconstruction has remained limited. Reconstructing visual imagination presents a greater challenge, with potentially revolutionary applications ranging from aiding individuals with disabilities to verifying witness accounts in court. The primary hurdles in this field are the absence of data collection protocols for visual imagery and the lack of datasets on the subject. Traditionally, fMRI-to-image relies on data collected from subjects exposed to visual stimuli, which poses issues for generating visual imagery based on the difference of brain activity between visual stimulation and visual imagery. For the first time, we have compiled a substantial dataset (around 6h of scans) on visual imagery along with a proposed data collection protocol. We then train a modified version of an fMRI-to-image model and demonstrate the feasibility of reconstructing images from two modes of imagination: from memory and from pure imagination. The resulting pipeline we call Mind-to-Image marks a step towards creating a technology that allow direct reconstruction of visual imagery.
5/29/2024
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
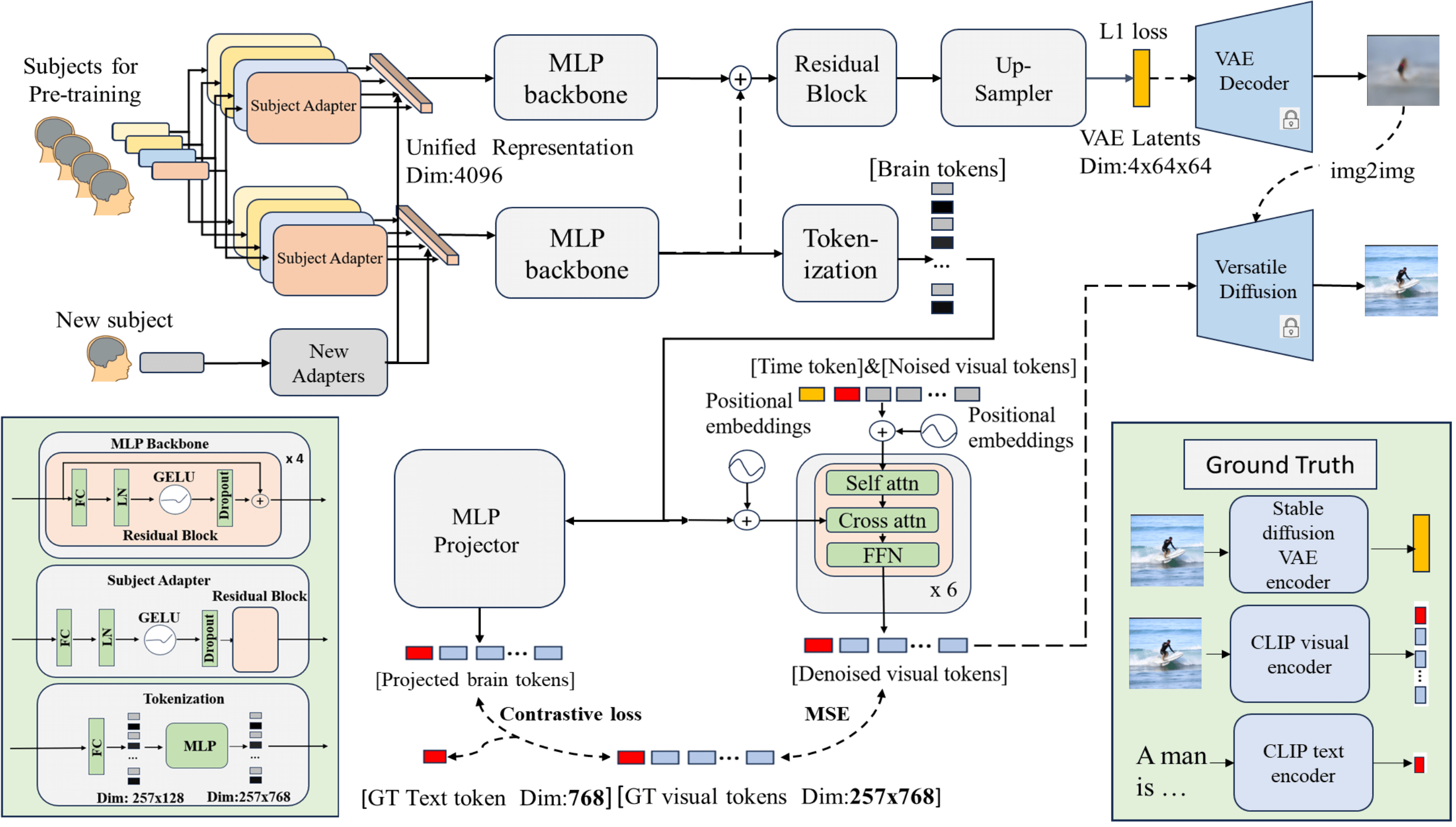
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024
Brainformer: Mimic Human Visual Brain Functions to Machine Vision Models via fMRI
Xuan-Bac Nguyen, Xin Li, Pawan Sinha, Samee U. Khan, Khoa Luu
0
0
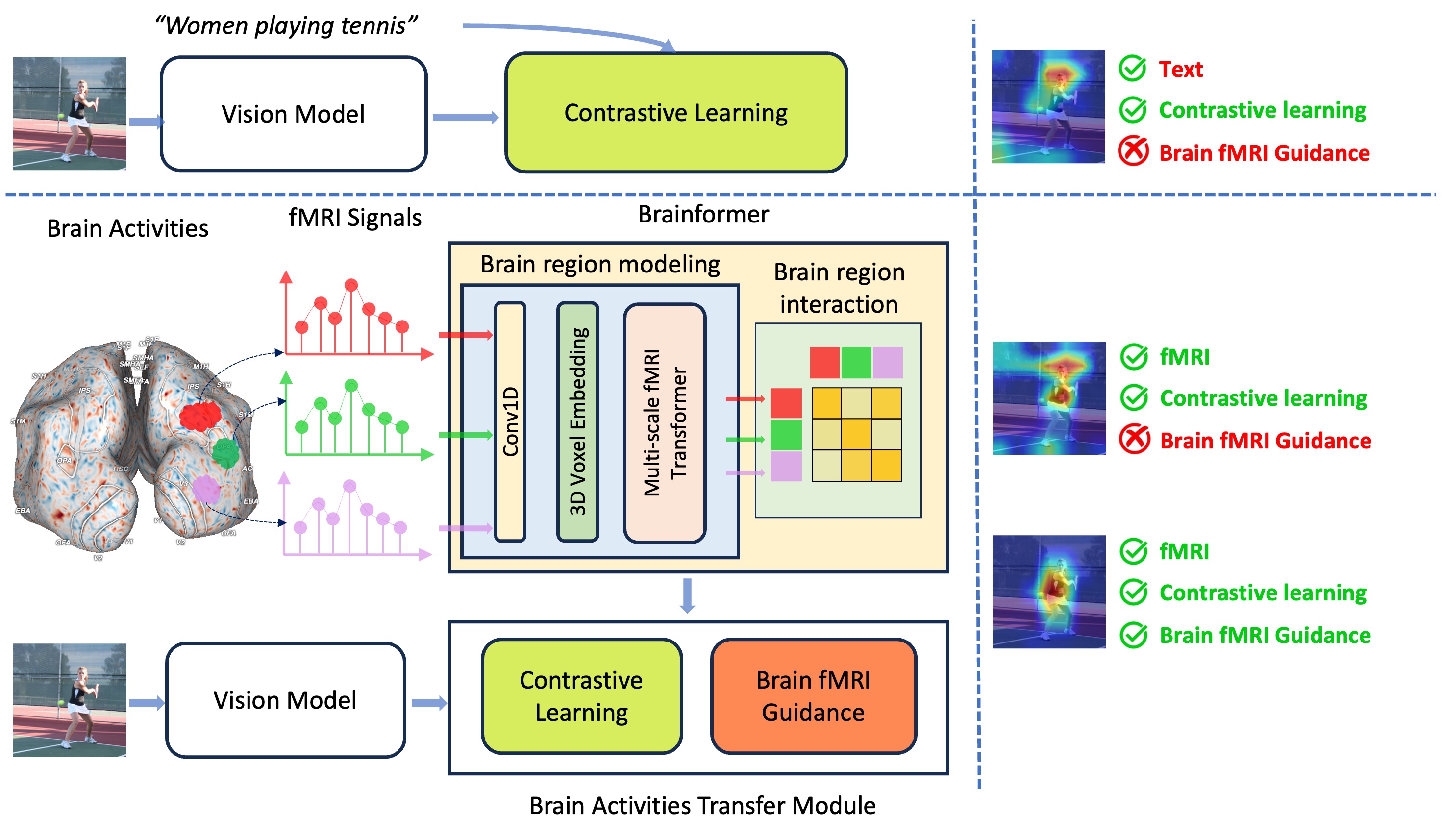
Human perception plays a vital role in forming beliefs and understanding reality. A deeper understanding of brain functionality will lead to the development of novel deep neural networks. In this work, we introduce a novel framework named Brainformer, a straightforward yet effective Transformer-based framework, to analyze Functional Magnetic Resonance Imaging (fMRI) patterns in the human perception system from a machine-learning perspective. Specifically, we present the Multi-scale fMRI Transformer to explore brain activity patterns through fMRI signals. This architecture includes a simple yet efficient module for high-dimensional fMRI signal encoding and incorporates a novel embedding technique called 3D Voxels Embedding. Secondly, drawing inspiration from the functionality of the brain's Region of Interest, we introduce a novel loss function called Brain fMRI Guidance Loss. This loss function mimics brain activity patterns from these regions in the deep neural network using fMRI data. This work introduces a prospective approach to transfer knowledge from human perception to neural networks. Our experiments demonstrate that leveraging fMRI information allows the machine vision model to achieve results comparable to State-of-the-Art methods in various image recognition tasks.
5/30/2024