Recurrent Distance Filtering for Graph Representation Learning

0

Sign in to get full access
Overview
- This paper introduces Recurrent Distance-Encoding Neural Networks (RDEN), a novel graph neural network architecture that aims to improve the ability to learn long-range dependencies in graphs.
- RDEN uses a recurrent structure and a distance-encoding mechanism to capture the relative positions of nodes in a graph, which helps the model learn global, long-range information.
- The authors demonstrate the effectiveness of RDEN on several graph representation learning tasks, showing that it outperforms state-of-the-art graph neural network models.
Plain English Explanation
The research paper presents a new type of neural network called Recurrent Distance-Encoding Neural Networks (RDEN) that is designed to work well with graph-structured data. Graphs are a way of representing relationships between different things, like the connections between people in a social network or the roads in a transportation system.
One of the challenges with existing graph neural network models is that they have trouble capturing long-range dependencies - information about nodes that are far apart in the graph. <a href="https://aimodels.fyi/papers/arxiv/learning-long-range-dependencies-graphs-via-random">RDEN tries to address this by using a special recurrent structure</a> that allows the model to better understand how nodes are positioned relative to each other in the graph. This "distance-encoding" mechanism helps the model learn global, high-level patterns in the graph data.
The authors test RDEN on several different graph-based tasks, such as predicting the properties of molecules or classifying nodes in a social network. They show that RDEN outperforms other state-of-the-art graph neural network models, demonstrating the benefits of its recurrent structure and distance-encoding approach.
Technical Explanation
The key innovation of RDEN is its use of a recurrent structure combined with a distance-encoding mechanism to better capture long-range dependencies in graph-structured data. <a href="https://aimodels.fyi/papers/arxiv/injecting-hamiltonian-architectural-bias-into-deep-graph">Unlike standard message passing neural networks (MPNNs) that only consider local neighborhoods</a>, RDEN incorporates information about the relative positions of nodes in the graph.
Specifically, RDEN uses a recurrent cell that takes in the current node's features, its neighbors' features, and a distance-encoding vector that represents the node's position relative to all other nodes in the graph. This distance-encoding is learned by the model and helps it understand the global structure of the graph, rather than just the local connectivity.
The authors demonstrate the effectiveness of RDEN on a range of graph representation learning tasks, including molecular property prediction, node classification, and graph classification. <a href="https://aimodels.fyi/papers/arxiv/differentiable-cluster-graph-neural-network">They show that RDEN outperforms state-of-the-art models like Graph Convolutional Networks (GCNs) and Graph Attention Networks (GATs)</a>, which are limited in their ability to capture long-range dependencies.
<a href="https://aimodels.fyi/papers/arxiv/enhancing-graph-transformers-hierarchical-distance-structural-encoding">One interesting aspect of RDEN is its use of a recurrent structure, which is less common in graph neural networks compared to feed-forward architectures</a>. The recurrent design allows RDEN to iteratively refine its understanding of the graph structure, potentially leading to better representations.
Critical Analysis
The authors provide a thorough evaluation of RDEN, demonstrating its strong performance across a variety of graph representation learning tasks. However, there are a few potential limitations and areas for further research that could be explored:
-
Computational complexity: The recurrent structure and distance-encoding mechanism of RDEN may increase the computational cost compared to simpler graph neural network models. The authors should investigate the scalability of RDEN as the graph size increases.
-
Interpretability: As with many deep learning models, it may be challenging to interpret the internal workings of RDEN and understand why it performs well on certain tasks. <a href="https://aimodels.fyi/papers/arxiv/structure-reinforced-transformer-dynamic-graph-representation-learning">Developing more interpretable graph neural network architectures is an important area for future research</a>.
-
Generalization to diverse graph types: The experiments in the paper focus on specific types of graphs, such as molecular graphs and citation networks. It would be valuable to assess how well RDEN generalizes to other graph domains, such as social networks, transportation networks, or biological networks.
Overall, the RDEN architecture represents a promising advancement in graph representation learning, demonstrating the benefits of incorporating relative positional information into graph neural networks. Further research to address the potential limitations could lead to even more powerful and versatile graph neural network models.
Conclusion
The Recurrent Distance-Encoding Neural Network (RDEN) proposed in this paper is a novel graph neural network architecture that aims to improve the learning of long-range dependencies in graph-structured data. By using a recurrent structure and a distance-encoding mechanism, RDEN is able to capture the relative positions of nodes in a graph, which helps the model learn global, high-level patterns.
The authors show that RDEN outperforms state-of-the-art graph neural network models on several representation learning tasks, highlighting the benefits of its unique design. While there are some potential limitations to address, such as computational complexity and interpretability, RDEN represents an important step forward in developing more powerful and versatile graph neural network models. Further research in this direction could lead to significant advancements in our ability to understand and make predictions from complex graph-structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Recurrent Distance Filtering for Graph Representation Learning
Yuhui Ding, Antonio Orvieto, Bobby He, Thomas Hofmann
Graph neural networks based on iterative one-hop message passing have been shown to struggle in harnessing the information from distant nodes effectively. Conversely, graph transformers allow each node to attend to all other nodes directly, but lack graph inductive bias and have to rely on ad-hoc positional encoding. In this paper, we propose a new architecture to reconcile these challenges. Our approach stems from the recent breakthroughs in long-range modeling provided by deep state-space models: for a given target node, our model aggregates other nodes by their shortest distances to the target and uses a linear RNN to encode the sequence of hop representations. The linear RNN is parameterized in a particular diagonal form for stable long-range signal propagation and is theoretically expressive enough to encode the neighborhood hierarchy. With no need for positional encoding, we empirically show that the performance of our model is comparable to or better than that of state-of-the-art graph transformers on various benchmarks, with a significantly reduced computational cost. Our code is open-source at https://github.com/skeletondyh/GRED.
Read more6/6/2024
0
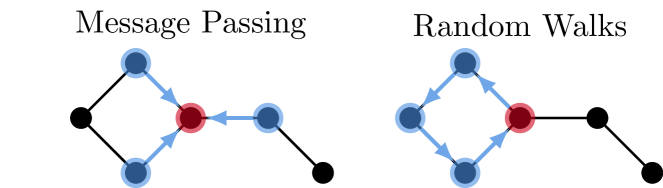
Learning Long Range Dependencies on Graphs via Random Walks
Dexiong Chen, Till Hendrik Schulz, Karsten Borgwardt
Message-passing graph neural networks (GNNs), while excelling at capturing local relationships, often struggle with long-range dependencies on graphs. Conversely, graph transformers (GTs) enable information exchange between all nodes but oversimplify the graph structure by treating them as a set of fixed-length vectors. This work proposes a novel architecture, NeuralWalker, that overcomes the limitations of both methods by combining random walks with message passing. NeuralWalker achieves this by treating random walks as sequences, allowing for the application of recent advances in sequence models in order to capture long-range dependencies within these walks. Based on this concept, we propose a framework that offers (1) more expressive graph representations through random walk sequences, (2) the ability to utilize any sequence model for capturing long-range dependencies, and (3) the flexibility by integrating various GNN and GT architectures. Our experimental evaluations demonstrate that NeuralWalker achieves significant performance improvements on 19 graph and node benchmark datasets, notably outperforming existing methods by up to 13% on the PascalVoc-SP and COCO-SP datasets. Code is available at https://github.com/BorgwardtLab/NeuralWalker.
Read more6/6/2024
0
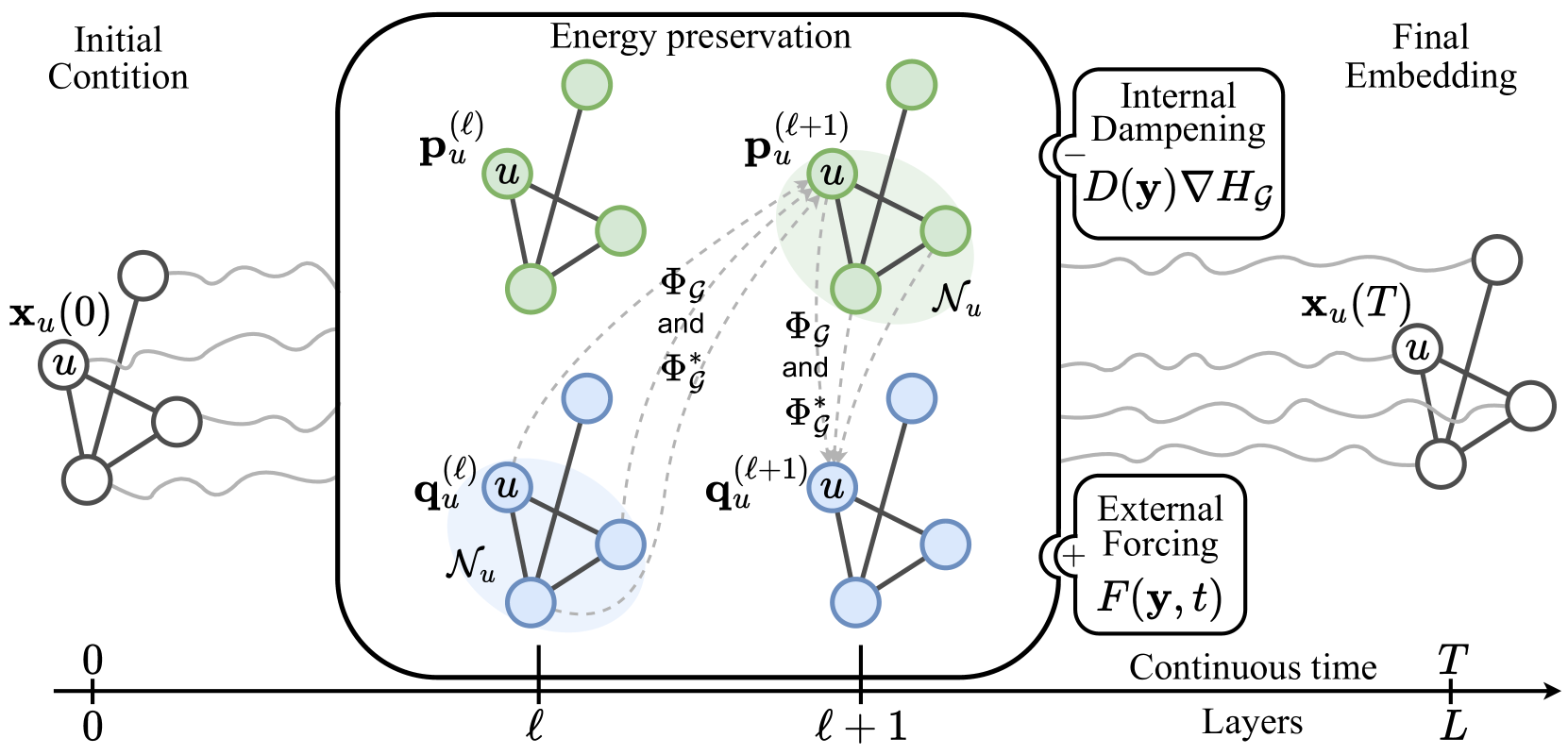
Injecting Hamiltonian Architectural Bias into Deep Graph Networks for Long-Range Propagation
Simon Heilig, Alessio Gravina, Alessandro Trenta, Claudio Gallicchio, Davide Bacciu
The dynamics of information diffusion within graphs is a critical open issue that heavily influences graph representation learning, especially when considering long-range propagation. This calls for principled approaches that control and regulate the degree of propagation and dissipation of information throughout the neural flow. Motivated by this, we introduce (port-)Hamiltonian Deep Graph Networks, a novel framework that models neural information flow in graphs by building on the laws of conservation of Hamiltonian dynamical systems. We reconcile under a single theoretical and practical framework both non-dissipative long-range propagation and non-conservative behaviors, introducing tools from mechanical systems to gauge the equilibrium between the two components. Our approach can be applied to general message-passing architectures, and it provides theoretical guarantees on information conservation in time. Empirical results prove the effectiveness of our port-Hamiltonian scheme in pushing simple graph convolutional architectures to state-of-the-art performance in long-range benchmarks.
Read more5/28/2024
🖼️
0
Enhancing Graph Transformers with Hierarchical Distance Structural Encoding
Yuankai Luo, Hongkang Li, Lei Shi, Xiao-Ming Wu
Graph transformers need strong inductive biases to derive meaningful attention scores. Yet, current methods often fall short in capturing longer ranges, hierarchical structures, or community structures, which are common in various graphs such as molecules, social networks, and citation networks. This paper presents a Hierarchical Distance Structural Encoding (HDSE) method to model node distances in a graph, focusing on its multi-level, hierarchical nature. We introduce a novel framework to seamlessly integrate HDSE into the attention mechanism of existing graph transformers, allowing for simultaneous application with other positional encodings. To apply graph transformers with HDSE to large-scale graphs, we further propose a high-level HDSE that effectively biases the linear transformers towards graph hierarchies. We theoretically prove the superiority of HDSE over shortest path distances in terms of expressivity and generalization. Empirically, we demonstrate that graph transformers with HDSE excel in graph classification, regression on 7 graph-level datasets, and node classification on 11 large-scale graphs, including those with up to a billion nodes.
Read more5/28/2024