Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion

0
🔄
Sign in to get full access
Overview
- Recent years have seen significant advancements in video generation and editing approaches.
- While many techniques focus on editing appearance, few address motion.
- Current methods using text, trajectories, or bounding boxes are limited to simple motions.
- This research proposes a new approach using a single motion reference video to specify complex motions.
- The approach leverages a pre-trained image-to-video model to preserve appearance and disentangle it from motion.
Plain English Explanation
The researchers have developed a new way to edit and generate videos that focuses on controlling the motion of objects or people in the video. Previous approaches have been limited to simple motions, using things like text, trajectories, or bounding boxes to try to specify the motion.
Instead, the researchers use a single reference video to show the kind of motion they want to apply. This reference video could be of a person walking, a car driving, or any other type of motion. The key is that it provides a real-world example of the specific motion they want to recreate.
The researchers then use a pre-trained image-to-video model, rather than a text-to-video model. This allows them to preserve the exact appearance and position of the objects or people in the target video, while just changing the motion. It "disentangles" the appearance from the motion.
The researchers call their approach "motion-textual inversion." The core idea is that the image-to-video model extracts the appearance mainly from the image input, while the text/image embedding (which connects the image to language) controls the motion. By optimizing this text/image embedding on the reference motion video, they can then apply it to different target images to generate new videos with similar motions.
This approach has several advantages. It doesn't require the target image and reference video to be spatially aligned, it can be applied across different domains (like full-body reenactment, face reenactment, or controlling inanimate objects), and it outperforms previous methods for transferring semantic video motion.
Technical Explanation
The key technical innovation in this research is the motion-textual inversion approach. The researchers observe that image-to-video models extract appearance mainly from the (latent) image input, while the text/image embedding injected via cross-attention predominantly controls the motion.
To leverage this, the researchers represent motion using the text/image embedding tokens. By operating on an "inflated" motion-text embedding containing multiple text/image embedding tokens per frame, they achieve a high temporal motion granularity.
Once this motion-text embedding is optimized on the reference motion video, it can be applied to various target images to generate videos with semantically similar motions. This approach does not require spatial alignment between the motion reference video and target image, and it can be applied across diverse domains.
The researchers evaluate their method on the semantic video motion transfer task, and show that it significantly outperforms existing approaches in this context.
Critical Analysis
The researchers acknowledge that their approach has some limitations. For example, it may struggle with complex interactions between multiple objects or people, as the motion-text embedding primarily controls the motion of a single target.
Additionally, the quality and realism of the generated videos, while impressive, may not yet be at the level required for certain professional applications. Further research and refinement of the image-to-video model could help address this.
Another potential concern is the ethical implications of tools that can manipulate video content so easily. The researchers do not address this issue, but it is an important consideration as these technologies become more widespread.
Overall, the motion-textual inversion approach represents a significant advance in video editing and generation, with the potential to enable new creative applications. However, as with any powerful technology, it will be important to consider the broader societal impacts and continue improving the quality and robustness of the underlying models.
Conclusion
This research presents a novel approach for controlling the motion of objects and people in generated videos, using a single reference motion video and a pre-trained image-to-video model. By disentangling appearance from motion and representing motion using text/image embeddings, the researchers have developed a flexible and powerful technique for semantic video motion transfer.
While the method has some limitations, it represents an important step forward in video editing and generation capabilities. As these technologies continue to advance, it will be crucial to consider the ethical implications and work towards ensuring they are used responsibly and for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion
Manuel Kansy, Jacek Naruniec, Christopher Schroers, Markus Gross, Romann M. Weber
Recent years have seen a tremendous improvement in the quality of video generation and editing approaches. While several techniques focus on editing appearance, few address motion. Current approaches using text, trajectories, or bounding boxes are limited to simple motions, so we specify motions with a single motion reference video instead. We further propose to use a pre-trained image-to-video model rather than a text-to-video model. This approach allows us to preserve the exact appearance and position of a target object or scene and helps disentangle appearance from motion. Our method, called motion-textual inversion, leverages our observation that image-to-video models extract appearance mainly from the (latent) image input, while the text/image embedding injected via cross-attention predominantly controls motion. We thus represent motion using text/image embedding tokens. By operating on an inflated motion-text embedding containing multiple text/image embedding tokens per frame, we achieve a high temporal motion granularity. Once optimized on the motion reference video, this embedding can be applied to various target images to generate videos with semantically similar motions. Our approach does not require spatial alignment between the motion reference video and target image, generalizes across various domains, and can be applied to various tasks such as full-body and face reenactment, as well as controlling the motion of inanimate objects and the camera. We empirically demonstrate the effectiveness of our method in the semantic video motion transfer task, significantly outperforming existing methods in this context.
Read more8/2/2024

0
Diving Deep into the Motion Representation of Video-Text Models
Chinmaya Devaraj, Cornelia Fermuller, Yiannis Aloimonos
Videos are more informative than images because they capture the dynamics of the scene. By representing motion in videos, we can capture dynamic activities. In this work, we introduce GPT-4 generated motion descriptions that capture fine-grained motion descriptions of activities and apply them to three action datasets. We evaluated several video-text models on the task of retrieval of motion descriptions. We found that they fall far behind human expert performance on two action datasets, raising the question of whether video-text models understand motion in videos. To address it, we introduce a method of improving motion understanding in video-text models by utilizing motion descriptions. This method proves to be effective on two action datasets for the motion description retrieval task. The results draw attention to the need for quality captions involving fine-grained motion information in existing datasets and demonstrate the effectiveness of the proposed pipeline in understanding fine-grained motion during video-text retrieval.
Read more6/10/2024

0
MotionClone: Training-Free Motion Cloning for Controllable Video Generation
Pengyang Ling, Jiazi Bu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Tong Wu, Huaian Chen, Jiaqi Wang, Yi Jin
Motion-based controllable text-to-video generation involves motions to control the video generation. Previous methods typically require the training of models to encode motion cues or the fine-tuning of video diffusion models. However, these approaches often result in suboptimal motion generation when applied outside the trained domain. In this work, we propose MotionClone, a training-free framework that enables motion cloning from a reference video to control text-to-video generation. We employ temporal attention in video inversion to represent the motions in the reference video and introduce primary temporal-attention guidance to mitigate the influence of noisy or very subtle motions within the attention weights. Furthermore, to assist the generation model in synthesizing reasonable spatial relationships and enhance its prompt-following capability, we propose a location-aware semantic guidance mechanism that leverages the coarse location of the foreground from the reference video and original classifier-free guidance features to guide the video generation. Extensive experiments demonstrate that MotionClone exhibits proficiency in both global camera motion and local object motion, with notable superiority in terms of motion fidelity, textual alignment, and temporal consistency.
Read more7/2/2024
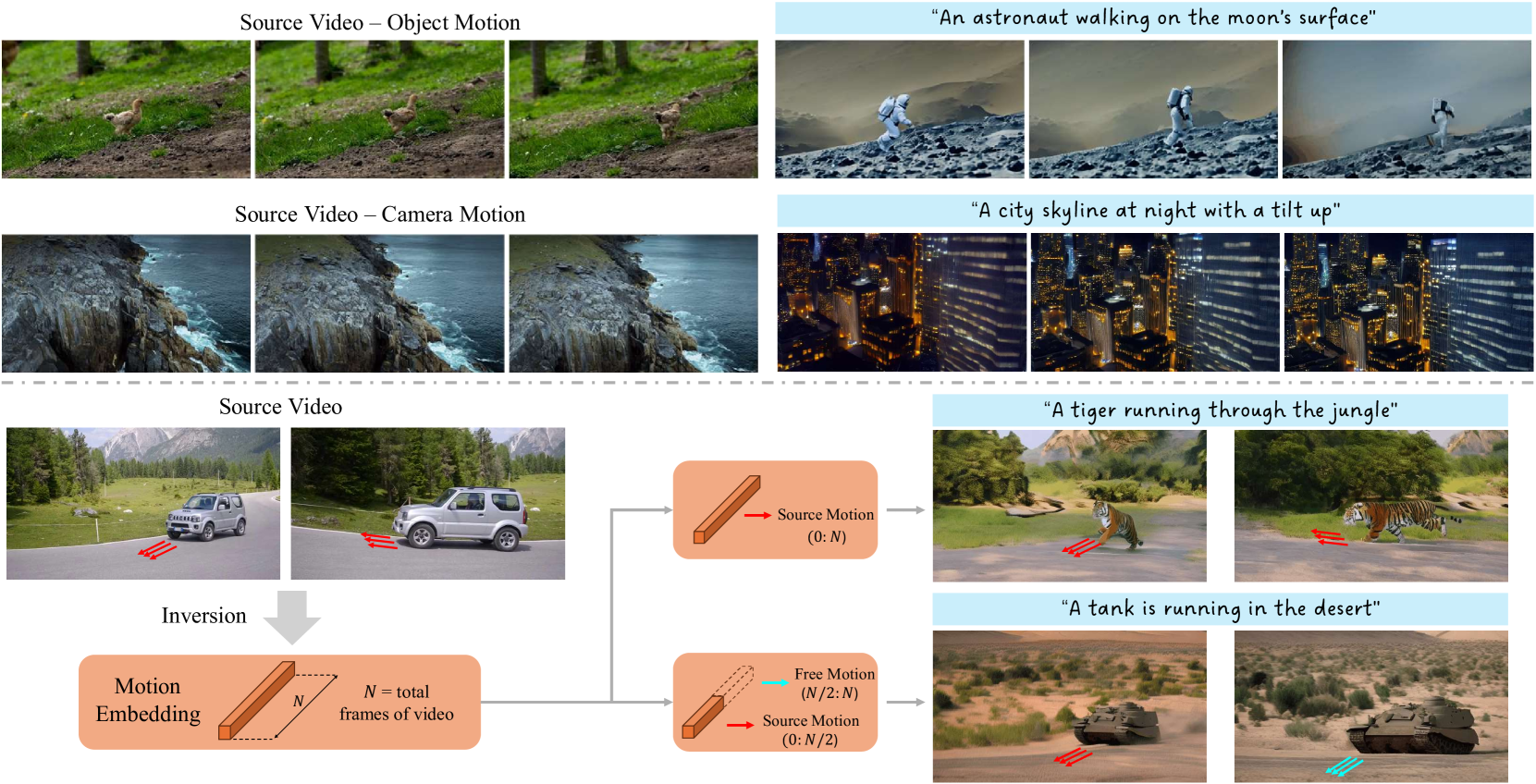
0
Motion Inversion for Video Customization
Luozhou Wang, Guibao Shen, Yixun Liang, Xin Tao, Pengfei Wan, Di Zhang, Yijun Li, Yingcong Chen
In this research, we present a novel approach to motion customization in video generation, addressing the widespread gap in the thorough exploration of motion representation within video generative models. Recognizing the unique challenges posed by video's spatiotemporal nature, our method introduces Motion Embeddings, a set of explicit, temporally coherent one-dimensional embeddings derived from a given video. These embeddings are designed to integrate seamlessly with the temporal transformer modules of video diffusion models, modulating self-attention computations across frames without compromising spatial integrity. Our approach offers a compact and efficient solution to motion representation and enables complex manipulations of motion characteristics through vector arithmetic in the embedding space. Furthermore, we identify the Temporal Discrepancy in video generative models, which refers to variations in how different motion modules process temporal relationships between frames. We leverage this understanding to optimize the integration of our motion embeddings. Our contributions include the introduction of a tailored motion embedding for customization tasks, insights into the temporal processing differences in video models, and a demonstration of the practical advantages and effectiveness of our method through extensive experiments.
Read more4/1/2024