Reference-Based 3D-Aware Image Editing with Triplane
2404.03632
0
0

Abstract
Generative Adversarial Networks (GANs) have emerged as powerful tools not only for high-quality image generation but also for real image editing through manipulation of their interpretable latent spaces. Recent advancements in GANs include the development of 3D-aware models such as EG3D, characterized by efficient triplane-based architectures enabling the reconstruction of 3D geometry from single images. However, scant attention has been devoted to providing an integrated framework for high-quality reference-based 3D-aware image editing within this domain. This study addresses this gap by exploring and demonstrating the effectiveness of EG3D's triplane space for achieving advanced reference-based edits, presenting a unique perspective on 3D-aware image editing through our novel pipeline. Our approach integrates the encoding of triplane features, spatial disentanglement and automatic localization of features in the triplane domain, and fusion learning for desired image editing. Moreover, our framework demonstrates versatility across domains, extending its effectiveness to animal face edits and partial stylization of cartoon portraits. The method shows significant improvements over relevant 3D-aware latent editing and 2D reference-based editing methods, both qualitatively and quantitatively. Project page: https://three-bee.github.io/triplane_edit
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper proposes a new method called "Triplane" for 3D-aware image editing, which allows users to edit 2D images while considering their 3D structure.
• Triplane leverages a reference-based approach, where the user provides a 3D reference image to guide the editing process.
• The method can handle a wide range of editing tasks, such as changing the pose, expression, or appearance of objects in the image, while preserving their 3D coherence.
Plain English Explanation
Editing photos can be tricky, especially when you want to change something about the 3D structure of the objects in the image. Traditionally, this has required specialized 3D modeling software and skills. However, this new "Triplane" method aims to make 3D-aware image editing much more accessible.
The key idea behind Triplane is to use a reference 3D image to guide the editing process. So, for example, if you want to change the pose of a person in a photo, you would provide a 3D model or image of a person in the desired pose. Triplane would then use this reference to intelligently modify the original 2D photo, adjusting the 3D structure while preserving important details like the person's appearance and expression.
This reference-based approach is powerful because it allows users to leverage existing 3D content, rather than having to create it from scratch. It also means that Triplane can handle a wide range of editing tasks, from changing poses and expressions to even altering the appearance of objects in the image.
Importantly, Triplane is designed to maintain the 3D coherence of the edited image. This means that the edited elements still look and behave as if they are part of a 3D world, rather than simply being pasted on top of the original image. This helps to create more natural and believable results.
Overall, Triplane represents an exciting advance in the field of 3D-aware image editing, making it more accessible and powerful for a wide range of users and applications. By combining 2D and 3D content, it opens up new possibilities for how we can creatively manipulate and enhance our digital images.
Technical Explanation
The core of the Triplane method is a neural network architecture that can take a 2D input image and a 3D reference image, and produce a 3D-aware edited output image. The architecture is built around three key components:
-
Encoder: This module encodes both the input 2D image and the reference 3D image into latent representations.
-
Decoder: The decoder then uses these latent representations to generate the final 3D-aware edited image. This involves predicting the 3D structure of the scene, as well as the appearance of the edited elements.
-
Triplane Representation: A key innovation is the use of a "triplane" representation to encode the 3D structure. This involves predicting three orthogonal 2D planes that together capture the 3D geometry of the scene.
During training, the model is optimized to preserve important attributes of the input image (like the original appearance and expression) while allowing for flexible 3D-aware editing guided by the reference image. The authors show that this approach can handle a wide range of editing tasks, from pose and expression changes to appearance modifications, while maintaining 3D coherence.
Critical Analysis
The Triplane method represents an impressive advance in 3D-aware image editing, with several notable strengths:
- The reference-based approach makes the editing process more intuitive and accessible, as users can leverage existing 3D content rather than having to create it from scratch.
- The triplane representation is a clever way to encode 3D structure without the need for a full 3D reconstruction, which can be computationally intensive.
- The method is demonstrated to be highly versatile, handling a wide range of editing tasks while preserving important attributes of the original image.
However, the paper also acknowledges some limitations and areas for future work:
- The method currently relies on having a suitable 3D reference image available, which may not always be the case.
- While the triplane representation is efficient, it may not capture all the nuances of 3D structure, potentially limiting the fidelity of the edited results.
- The authors note that the model can sometimes introduce artifacts or distortions, especially for complex scenes or editing tasks.
Additionally, it would be interesting to see further analysis of the model's robustness and generalization capabilities, as well as its performance compared to other state-of-the-art 3D-aware editing approaches.
Conclusion
Overall, the Triplane method represents an exciting development in the field of 3D-aware image editing. By leveraging a reference-based approach and a novel triplane representation, it enables users to flexibly edit 2D images while preserving their 3D structure and coherence. This opens up new creative possibilities for photo manipulation and enhancement, and could have significant implications for a wide range of applications, from visual effects to digital content creation.
As the authors continue to refine and expand the capabilities of Triplane, it will be interesting to see how the method evolves and what further advancements it inspires in the broader field of 3D-aware image processing and editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Real-time 3D-aware Portrait Editing from a Single Image
Qingyan Bai, Zifan Shi, Yinghao Xu, Hao Ouyang, Qiuyu Wang, Ceyuan Yang, Xuan Wang, Gordon Wetzstein, Yujun Shen, Qifeng Chen
0
0
This work presents 3DPE, a practical method that can efficiently edit a face image following given prompts, like reference images or text descriptions, in a 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and superior editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified customized types of editing during inference (e.g., with ~5min fine-tuning per style). The code, the model, and the interface will be made publicly available to facilitate future research.
4/3/2024

SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation
Heyuan Li, Ce Chen, Tianhao Shi, Yuda Qiu, Sizhe An, Guanying Chen, Xiaoguang Han
0
0
While recent advances in 3D-aware Generative Adversarial Networks (GANs) have aided the development of near-frontal view human face synthesis, the challenge of comprehensively synthesizing a full 3D head viewable from all angles still persists. Although PanoHead proves the possibilities of using a large-scale dataset with images of both frontal and back views for full-head synthesis, it often causes artifacts for back views. Based on our in-depth analysis, we found the reasons are mainly twofold. First, from network architecture perspective, we found each plane in the utilized tri-plane/tri-grid representation space tends to confuse the features from both sides, causing mirroring artifacts (e.g., the glasses appear in the back). Second, from data supervision aspect, we found that existing discriminator training in 3D GANs mainly focuses on the quality of the rendered image itself, and does not care much about its plausibility with the perspective from which it was rendered. This makes it possible to generate face in non-frontal views, due to its easiness to fool the discriminator. In response, we propose SphereHead, a novel tri-plane representation in the spherical coordinate system that fits the human head's geometric characteristics and efficiently mitigates many of the generated artifacts. We further introduce a view-image consistency loss for the discriminator to emphasize the correspondence of the camera parameters and the images. The combination of these efforts results in visually superior outcomes with significantly fewer artifacts. Our code and dataset are publicly available at https://lhyfst.github.io/spherehead.
4/9/2024
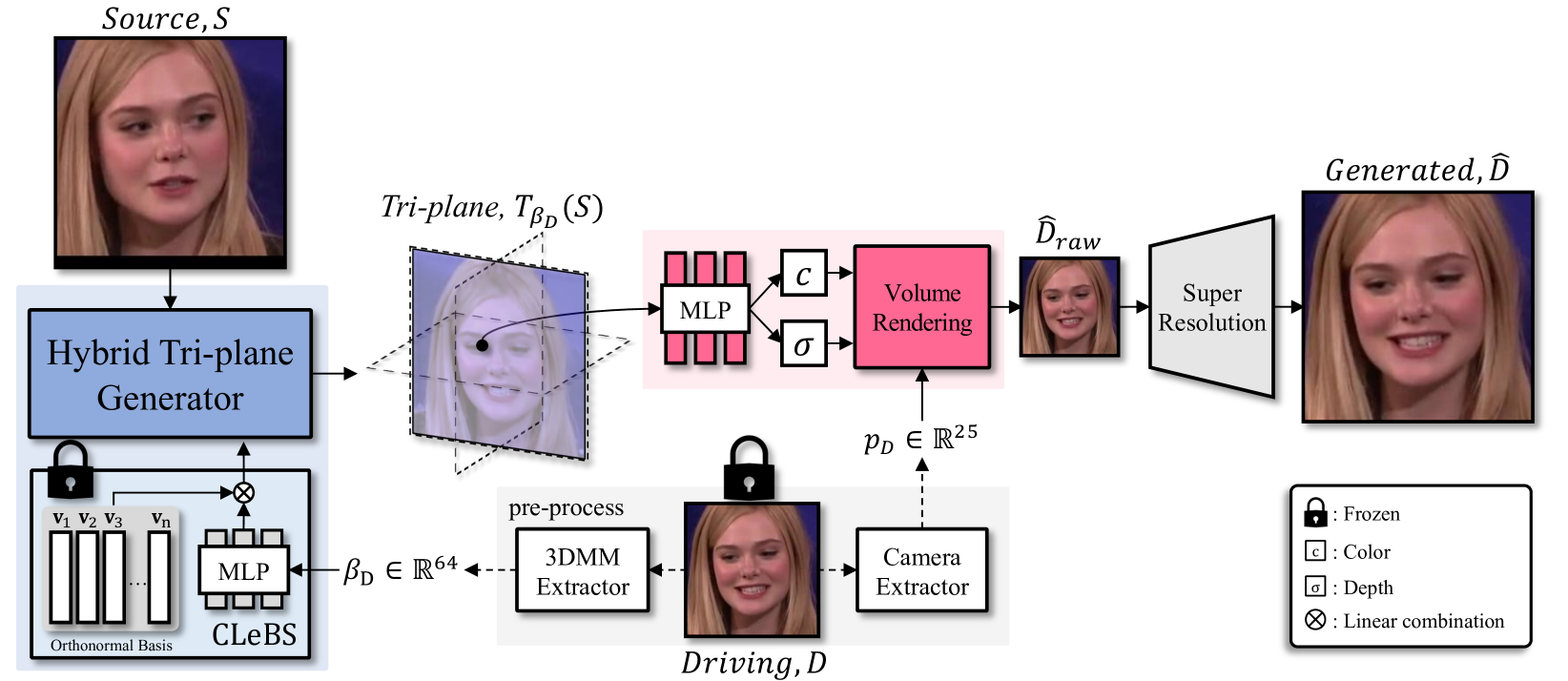
Learning to Generate Conditional Tri-plane for 3D-aware Expression Controllable Portrait Animation
Taekyung Ki, Dongchan Min, Gyeongsu Chae
0
0
In this paper, we present Export3D, a one-shot 3D-aware portrait animation method that is able to control the facial expression and camera view of a given portrait image. To achieve this, we introduce a tri-plane generator that directly generates a tri-plane of 3D prior by transferring the expression parameter of 3DMM into the source image. The tri-plane is then decoded into the image of different view through a differentiable volume rendering. Existing portrait animation methods heavily rely on image warping to transfer the expression in the motion space, challenging on disentanglement of appearance and expression. In contrast, we propose a contrastive pre-training framework for appearance-free expression parameter, eliminating undesirable appearance swap when transferring a cross-identity expression. Extensive experiments show that our pre-training framework can learn the appearance-free expression representation hidden in 3DMM, and our model can generate 3D-aware expression controllable portrait image without appearance swap in the cross-identity manner.
4/3/2024
🧠
Lightplane: Highly-Scalable Components for Neural 3D Fields
Ang Cao, Justin Johnson, Andrea Vedaldi, David Novotny
0
0
Contemporary 3D research, particularly in reconstruction and generation, heavily relies on 2D images for inputs or supervision. However, current designs for these 2D-3D mapping are memory-intensive, posing a significant bottleneck for existing methods and hindering new applications. In response, we propose a pair of highly scalable components for 3D neural fields: Lightplane Render and Splatter, which significantly reduce memory usage in 2D-3D mapping. These innovations enable the processing of vastly more and higher resolution images with small memory and computational costs. We demonstrate their utility in various applications, from benefiting single-scene optimization with image-level losses to realizing a versatile pipeline for dramatically scaling 3D reconstruction and generation. Code: url{https://github.com/facebookresearch/lightplane}.
5/1/2024