Learning to Generate Conditional Tri-plane for 3D-aware Expression Controllable Portrait Animation
2404.00636
0
0
Abstract
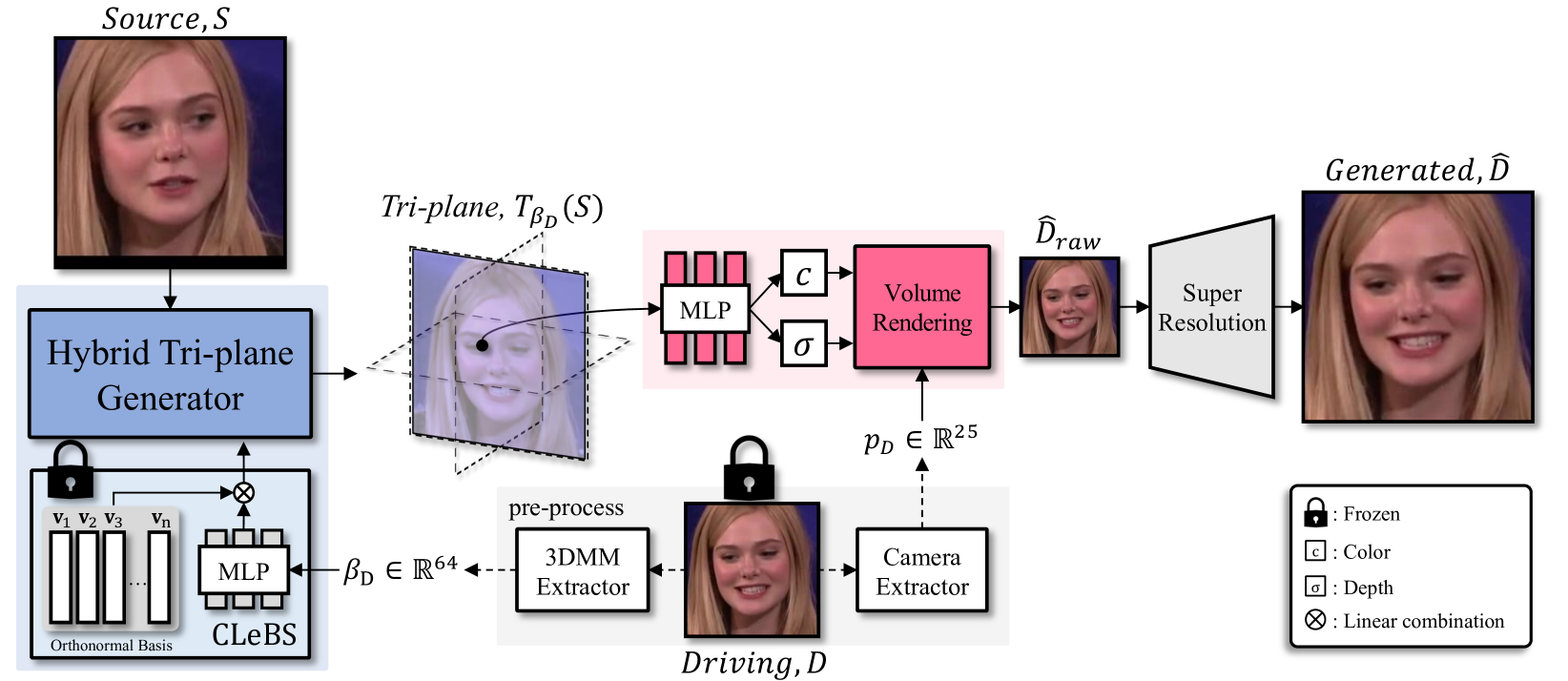
In this paper, we present Export3D, a one-shot 3D-aware portrait animation method that is able to control the facial expression and camera view of a given portrait image. To achieve this, we introduce a tri-plane generator that directly generates a tri-plane of 3D prior by transferring the expression parameter of 3DMM into the source image. The tri-plane is then decoded into the image of different view through a differentiable volume rendering. Existing portrait animation methods heavily rely on image warping to transfer the expression in the motion space, challenging on disentanglement of appearance and expression. In contrast, we propose a contrastive pre-training framework for appearance-free expression parameter, eliminating undesirable appearance swap when transferring a cross-identity expression. Extensive experiments show that our pre-training framework can learn the appearance-free expression representation hidden in 3DMM, and our model can generate 3D-aware expression controllable portrait image without appearance swap in the cross-identity manner.
Create account to get full access
Overview
- This paper presents a method for generating 3D-aware, expression-controllable portrait animations.
- The approach involves learning a conditional tri-plane representation that can be used to synthesize portrait images with fine-grained control over facial expressions.
- The model leverages a novel hybrid architecture combining 2D and 3D components to enable high-fidelity, 3D-aware portrait animation.
Plain English Explanation
The researchers have developed a new way to create animated portraits where you can control the person's facial expressions. Typically, creating realistic portrait animations that change the person's face in a natural way is very challenging. This paper introduces a technique that learns a special 3D representation of the portrait, called a "tri-plane," which allows for fine-grained control over the facial expressions.
The key idea is to combine 2D and 3D components in the model architecture. This hybrid approach enables generating high-quality, 3D-aware portrait animations that can smoothly transition between different expressions. For example, you could make the person in the portrait smile, frown, or make other facial movements in a life-like manner.
This technology could be useful for applications like virtual avatars, special effects in films, and user interfaces that involve expressive face animations. By modeling the 3D structure of the face, the method can produce more natural and convincing results compared to previous 2D-based approaches.
Technical Explanation
The paper proposes a novel conditional tri-plane generation framework for 3D-aware, expression-controllable portrait animation. The model takes as input a portrait image and a target expression, and outputs a new portrait image with the desired expression.
The key technical contributions are:
-
A hybrid 2D-3D architecture that combines a 2D image generator with a 3D tri-plane representation. The tri-plane encodes the 3D structure of the face, which enables better modeling of complex facial deformations.
-
A conditional tri-plane generation module that learns to synthesize the 3D tri-plane representation conditioned on the target expression. This allows fine-grained control over the facial animation.
-
A multi-scale tri-plane reconstruction loss that enforces both local and global consistency in the generated tri-plane, leading to higher-fidelity 3D-aware portrait synthesis.
The proposed model is extensively evaluated on multiple portrait datasets, demonstrating state-of-the-art performance in terms of expression control, 3D consistency, and visual quality compared to prior 2D and 3D animation methods.
Critical Analysis
The paper makes a compelling technical contribution by presenting a novel hybrid 2D-3D architecture for expression-controllable portrait animation. The tri-plane representation and conditional generation approach are well-motivated and the experimental results are promising.
However, the paper does not discuss several important limitations and potential issues. For example, the model may struggle with extreme or less common facial expressions that are not well represented in the training data. Additionally, the computational and memory requirements of the tri-plane representation could limit the scalability of the approach, especially for real-time applications.
The authors also do not address potential ethical concerns around the use of this technology, such as the creation of manipulated or synthetic portrait media. Further research is needed to understand the societal implications of such expression control capabilities.
Conclusion
Overall, this paper presents an intriguing approach for 3D-aware, expression-controllable portrait animation. The hybrid 2D-3D architecture and tri-plane representation enable fine-grained control over facial expressions while maintaining high visual quality. While the technical contributions are significant, the authors should consider addressing the limitations and potential issues to further strengthen the impact of this work. This research represents an important step towards more realistic and expressive portrait animation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Coherent 3D Portrait Video Reconstruction via Triplane Fusion
Shengze Wang, Xueting Li, Chao Liu, Matthew Chan, Michael Stengel, Josef Spjut, Henry Fuchs, Shalini De Mello, Koki Nagano
0
0
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, potentially democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a personalized 3D prior, but fail to faithfully reconstruct the user's per-frame appearance (e.g., facial expressions and lighting). In this work, we recognize the need to maintain both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that fuses a personalized 3D subject prior with per-frame information, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearances. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction accuracy and temporal consistency on in-studio and in-the-wild datasets.
5/3/2024
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
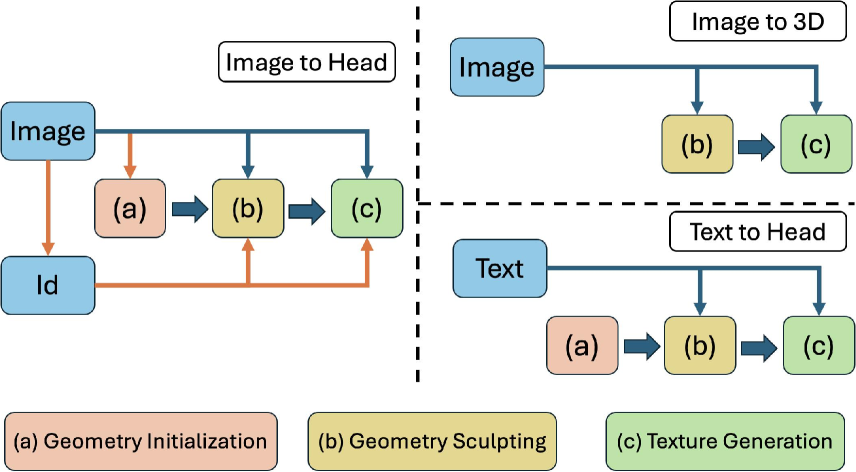
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024

Real-time 3D-aware Portrait Editing from a Single Image
Qingyan Bai, Zifan Shi, Yinghao Xu, Hao Ouyang, Qiuyu Wang, Ceyuan Yang, Xuan Wang, Gordon Wetzstein, Yujun Shen, Qifeng Chen
0
0
This work presents 3DPE, a practical method that can efficiently edit a face image following given prompts, like reference images or text descriptions, in a 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and superior editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified customized types of editing during inference (e.g., with ~5min fine-tuning per style). The code, the model, and the interface will be made publicly available to facilitate future research.
4/3/2024

Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
Yiqian Wu, Hao Xu, Xiangjun Tang, Xien Chen, Siyu Tang, Zhebin Zhang, Chen Li, Xiaogang Jin
0
0
Existing neural rendering-based text-to-3D-portrait generation methods typically make use of human geometry prior and diffusion models to obtain guidance. However, relying solely on geometry information introduces issues such as the Janus problem, over-saturation, and over-smoothing. We present Portrait3D, a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation that overcomes the aforementioned issues. To accomplish this, we train a 3D portrait generator, 3DPortraitGAN-Pyramid, as a robust prior. This generator is capable of producing 360{deg} canonical 3D portraits, serving as a starting point for the subsequent diffusion-based generation process. To mitigate the grid-like artifact caused by the high-frequency information in the feature-map-based 3D representation commonly used by most 3D-aware GANs, we integrate a novel pyramid tri-grid 3D representation into 3DPortraitGAN-Pyramid. To generate 3D portraits from text, we first project a randomly generated image aligned with the given prompt into the pre-trained 3DPortraitGAN-Pyramid's latent space. The resulting latent code is then used to synthesize a pyramid tri-grid. Beginning with the obtained pyramid tri-grid, we use score distillation sampling to distill the diffusion model's knowledge into the pyramid tri-grid. Following that, we utilize the diffusion model to refine the rendered images of the 3D portrait and then use these refined images as training data to further optimize the pyramid tri-grid, effectively eliminating issues with unrealistic color and unnatural artifacts. Our experimental results show that Portrait3D can produce realistic, high-quality, and canonical 3D portraits that align with the prompt.
4/17/2024