Empirical Studies of Parameter Efficient Methods for Large Language Models of Code and Knowledge Transfer to R
2405.01553
0
0
💬
Abstract
Recently, Large Langauge Models (LLMs) have gained a lot of attention in the Software Engineering (SE) community. LLMs or their variants pre-trained on code are used for many SE tasks. A main approach for adapting LLMs to the downstream task is to fine-tune the models. However, with having billions-parameters-LLMs, fine-tuning the models is not practical. An alternative approach is using Parameter Efficient Fine Tuning (PEFT), in which the model parameters are frozen and only a few added parameters are trained. Though the LLMs are used for programming languages such as Python and Java widely, their capability for low-resource languages is limited. In this work, we empirically study PEFT methods, LoRA and Compacter, on CodeT5 and CodeLlama. We will assess their performance compared to fully fine-tuned models, whether they can be used for knowledge transfer from natural language models to code (using T5 and Llama models), and their ability to adapt the learned knowledge to an unseen language. For the unseen language, we aim to study R, as it has a wide community. The adaptability with less computational costs makes LLMs accessible in scenarios where heavy computational resources are not available. Moreover, studying R opens new opportunities for using LLMs for other languages. We anticipate our findings to showcase the capabilities of PEFT for code LLMs for R and reveal the improvement areas.
Create account to get full access
Overview
- Large Language Models (LLMs) have gained significant attention in the Software Engineering (SE) community for their potential to assist with various programming tasks.
- A common approach to adapt LLMs for specific SE tasks is fine-tuning, where the model parameters are updated on the target task data.
- However, fine-tuning billions-parameter-LLMs is computationally expensive and impractical.
- An alternative approach is Parameter Efficient Fine Tuning (PEFT), where only a few added parameters are trained while the main model parameters are frozen.
- While LLMs have been widely used for programming languages like Python and Java, their capabilities for low-resource languages, such as R, are limited.
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can perform a wide range of tasks, including programming. Researchers have been exploring how to adapt these LLMs to specific software engineering (SE) tasks, such as code generation or code summarization.
One common approach is fine-tuning, where the model's parameters are updated using data from the target task. This allows the model to specialize and improve its performance on the specific task. However, fine-tuning the massive, billions-parameter LLMs can be computationally very expensive and impractical.
An alternative approach is Parameter Efficient Fine Tuning (PEFT). In PEFT, the model's main parameters are kept frozen, and only a small number of additional parameters are trained on the target task data. This makes the fine-tuning process much more efficient and practical, especially for resource-constrained environments.
While LLMs have been widely used for programming languages like Python and Java, their capabilities for low-resource languages, such as the statistical programming language R, are still limited. Researchers want to explore how PEFT methods can be used to adapt LLMs to perform well on R code, which could open up new opportunities for using these powerful models for a wider range of programming tasks.
Technical Explanation
The researchers in this paper empirically study two PEFT methods, LoRA and Compacter, on two code-focused LLMs: CodeT5 and CodeLlama. They assess the performance of these PEFT methods compared to fully fine-tuned models, whether the PEFT methods can be used for knowledge transfer from natural language models (T5 and Llama) to code, and the models' ability to adapt to an unseen programming language, specifically R.
The researchers choose R as the unseen language because it has a wide community and studying its adaptability could reveal new opportunities for using LLMs for other low-resource languages. By using PEFT methods, the researchers aim to make LLMs more accessible in scenarios where computational resources are limited, as the PEFT approach requires much less computational power than full fine-tuning.
Critical Analysis
The researchers acknowledge that while LLMs have shown impressive capabilities for programming tasks in popular languages like Python and Java, their performance on low-resource languages like R is still limited. The PEFT methods explored in this paper could help address this gap by enabling more efficient fine-tuning of LLMs on specialized tasks and datasets.
However, the researchers do not discuss potential limitations or caveats of the PEFT approach, such as the risk of overfitting or the impact of the choice of PEFT method on performance. Additionally, the paper does not provide a detailed analysis of the tradeoffs between the PEFT methods and full fine-tuning, such as the potential loss in performance or the exact computational savings.
Further research could explore the robustness and generalizability of the PEFT methods across a wider range of programming languages and tasks, as well as investigate the impact of different PEFT architectures and hyperparameter choices on the final model performance.
Conclusion
This paper investigates the use of Parameter Efficient Fine Tuning (PEFT) methods to adapt Large Language Models (LLMs) for software engineering tasks, particularly for the low-resource programming language R. The researchers explore the performance of two PEFT methods, LoRA and Compacter, on code-focused LLMs and assess their capability for knowledge transfer and adaptation to an unseen language.
The findings from this study could help make LLMs more accessible for a wider range of programming tasks and languages, especially in resource-constrained environments. By leveraging PEFT, the computational costs of fine-tuning these large models can be significantly reduced, opening up new opportunities for using powerful LLMs in diverse software engineering applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
0
0
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
6/10/2024

Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Tong Su, Xin Peng, Sarubi Thillainathan, David Guzm'an, Surangika Ranathunga, En-Shiun Annie Lee
0
0
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
4/8/2024

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024
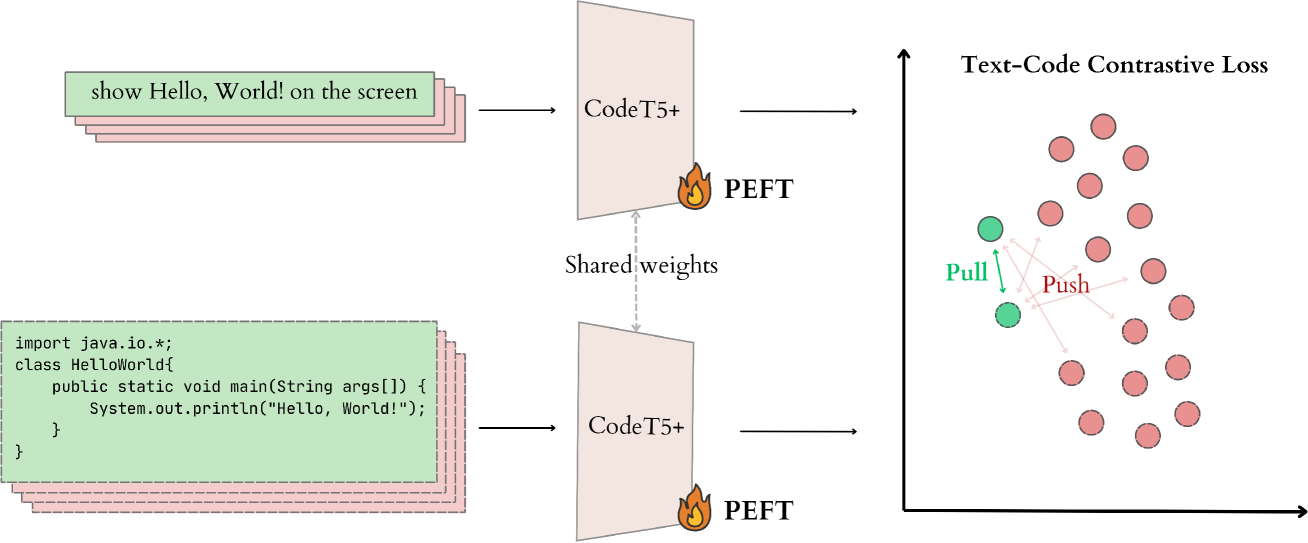
Refining Joint Text and Source Code Embeddings for Retrieval Task with Parameter-Efficient Fine-Tuning
Karim Galliamov, Leila Khaertdinova, Karina Denisova
0
0
The latest developments in Natural Language Processing (NLP) have demonstrated remarkable progress in a code-text retrieval problem. As the Transformer-based models used in this task continue to increase in size, the computational costs and time required for end-to-end fine-tuning become substantial. This poses a significant challenge for adapting and utilizing these models when computational resources are limited. Motivated by these concerns, we propose a fine-tuning framework that leverages Parameter-Efficient Fine-Tuning (PEFT) techniques. Moreover, we adopt contrastive learning objectives to improve the quality of bimodal representations learned by transformer models. Additionally, for PEFT methods we provide extensive benchmarking, the lack of which has been highlighted as a crucial problem in the literature. Based on the thorough experimentation with the CodeT5+ model conducted on two datasets, we demonstrate that the proposed fine-tuning framework has the potential to improve code-text retrieval performance by tuning only 0.4% parameters at most.
5/8/2024