On the Regret of Recursive Methods for Discrete-Time Adaptive Control with Matched Uncertainty
2404.02023
0
0
Abstract
Continuous-time adaptive controllers for systems with a matched uncertainty often comprise an online parameter estimator and a corresponding parameterized controller to cancel the uncertainty. However, such methods are often unimplementable, as they depend on an unobserved estimation error. We consider the equivalent discrete-time setting with a causal information structure. We propose a novel, online proximal point method-based adaptive controller, that under a weak persistence of excitation (PE) condition is asymptotically stable and achieves finite regret, scaling only with the time required to fulfill the PE condition. We show the same also for the widely-used recursive least squares with exponential forgetting controller under a stronger PE condition.
Create account to get full access
Overview
- This research paper examines the regret, or performance loss, associated with using recursive methods for discrete-time adaptive control in the presence of matched uncertainty.
- The paper aims to provide theoretical analysis and insights into the regret of these recursive control methods, which are commonly used in adaptive control systems.
- The researchers investigate how the choice of control design, such as the recursive algorithm and the adaptation gain, can impact the regret bound and overall performance of the adaptive control system.
Plain English Explanation
Imagine you have a system that needs to be controlled, like a robot arm or a manufacturing process. The system has some uncertainty or unpredictability built into it, which makes it challenging to control. Adaptive control is a way to address this, where the control system can adjust and learn over time to handle the uncertainty.
One approach to adaptive control is to use recursive methods, which involve repeatedly updating the control strategy based on new information. The researchers in this paper wanted to understand how well these recursive methods perform, particularly in terms of the "regret" - the difference between the performance you actually get and the best possible performance you could have achieved if you knew everything about the system upfront.
The key idea is that by understanding the regret of these recursive control methods, we can make better choices about how to design the control system. For example, the researchers looked at how the specific recursive algorithm used and the adaptation gain (how quickly the system learns) can affect the regret. This can help engineers choose the right control approach for their particular application and achieve better overall performance.
Technical Explanation
The paper focuses on discrete-time adaptive control systems with matched uncertainty, where the uncertainty enters the system in a way that can be "matched" by the control input. The researchers analyze the regret, or performance loss, of using recursive control methods in this setting.
Specifically, they consider two types of recursive control algorithms: a gradient-based method and a least-squares method. They derive regret bounds for each of these algorithms, showing how the regret depends on factors like the adaptation gain, the system dynamics, and the uncertainty bounds.
Through their analysis, the researchers find that the choice of control design, such as the recursive algorithm and the adaptation gain, can have a significant impact on the regret bound and the overall performance of the adaptive control system. They provide guidelines for selecting these design parameters to achieve better regret performance.
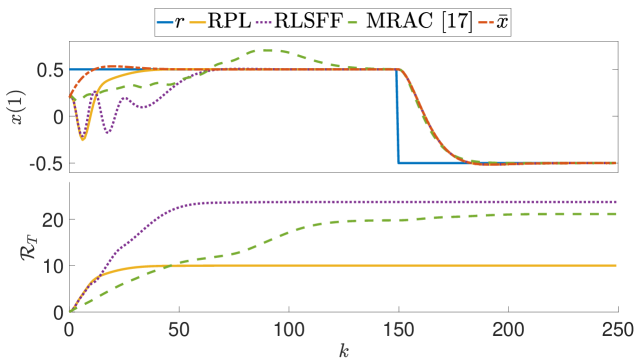
The theoretical analysis is supported by numerical simulations, which demonstrate the practical implications of the regret bounds and the performance tradeoffs involved in choosing different control design approaches.
Critical Analysis
The paper provides a thorough theoretical analysis of the regret associated with recursive adaptive control methods, which is an important consideration for the practical deployment of these techniques. The researchers have carefully derived the regret bounds and highlighted the key design choices that can impact performance.
However, the analysis is limited to the case of matched uncertainty, which may not capture all the complexities of real-world control systems. Additionally, the paper does not address the potential computational and implementation challenges of these recursive methods, which could be an important consideration in practice.
Further research could explore the regret of recursive adaptive control in the presence of other types of uncertainty, such as unmatched uncertainty, as well as investigate the practical trade-offs and challenges in deploying these methods in real-world applications. Experimental validation on physical systems could also provide valuable insights.
Conclusion
This research paper provides valuable insights into the regret, or performance loss, associated with using recursive methods for discrete-time adaptive control in the presence of matched uncertainty. By analyzing the regret bounds for different control design choices, the researchers offer guidance to engineers and control system designers on how to select appropriate algorithms and parameters to achieve better performance in adaptive control applications.
The theoretical analysis and numerical simulations presented in the paper contribute to a deeper understanding of the trade-offs involved in designing robust and effective adaptive control systems. While the scope is limited to the case of matched uncertainty, the findings have the potential to inform the development of more advanced adaptive control techniques that can better handle the complexities of real-world systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Adaptive Robust Controller for handling Unknown Uncertainty of Robotic Manipulators
Mohamed Abdelwahab, Giulio Giacomuzzo, Alberto Dalla Libera, Ruggero Carli
0
0
The ability to achieve precise and smooth trajectory tracking is crucial for ensuring the successful execution of various tasks involving robotic manipulators. State-of-the-art techniques require accurate mathematical models of the robot dynamics, and robustness to model uncertainties is achieved by relying on precise bounds on the model mismatch. In this paper, we propose a novel adaptive robust feedback linearization scheme able to compensate for model uncertainties without any a-priori knowledge on them, and we provide a theoretical proof of convergence under mild assumptions. We evaluate the method on a simulated RR robot. First, we consider a nominal model with known model mismatch, which allows us to compare our strategy with state-of-the-art uncertainty-aware methods. Second, we implement the proposed control law in combination with a learned model, for which uncertainty bounds are not available. Results show that our method leads to performance comparable to uncertainty-aware methods while requiring less prior knowledge.
6/21/2024
🔍
Fully Adaptive Regret-Guaranteed Algorithm for Control of Linear Quadratic Systems
Jafar Abbaszadeh Chekan, Cedric Langbort
0
0
The first algorithm for the Linear Quadratic (LQ) control problem with an unknown system model, featuring a regret of $mathcal{O}(sqrt{T})$, was introduced by Abbasi-Yadkori and Szepesv'ari (2011). Recognizing the computational complexity of this algorithm, subsequent efforts (see Cohen et al. (2019), Mania et al. (2019), Faradonbeh et al. (2020a), and Kargin et al.(2022)) have been dedicated to proposing algorithms that are computationally tractable while preserving this order of regret. Although successful, the existing works in the literature lack a fully adaptive exploration-exploitation trade-off adjustment and require a user-defined value, which can lead to overall regret bound growth with some factors. In this work, noticing this gap, we propose the first fully adaptive algorithm that controls the number of policy updates (i.e., tunes the exploration-exploitation trade-off) and optimizes the upper-bound of regret adaptively. Our proposed algorithm builds on the SDP-based approach of Cohen et al. (2019) and relaxes its need for a horizon-dependant warm-up phase by appropriately tuning the regularization parameter and adding an adaptive input perturbation. We further show that through careful exploration-exploitation trade-off adjustment there is no need to commit to the widely-used notion of strong sequential stability, which is restrictive and can introduce complexities in initialization.
6/13/2024
🤷
Learning Decentralized Linear Quadratic Regulator with $sqrt{T}$ Regret
Lintao Ye, Ming Chi, Ruiquan Liao, Vijay Gupta
0
0
We propose an online learning algorithm that adaptively designs a decentralized linear quadratic regulator when the system model is unknown a priori and new data samples from a single system trajectory become progressively available. The algorithm uses a disturbance-feedback representation of state-feedback controllers coupled with online convex optimization with memory and delayed feedback. Under the assumption that the system is stable or given a known stabilizing controller, we show that our controller enjoys an expected regret that scales as $sqrt{T}$ with the time horizon $T$ for the case of partially nested information pattern. For more general information patterns, the optimal controller is unknown even if the system model is known. In this case, the regret of our controller is shown with respect to a linear sub-optimal controller. We validate our theoretical findings using numerical experiments.
4/16/2024
🤿
Robust Adaptive MPC Using Uncertainty Compensation
Ran Tao, Pan Zhao, Ilya Kolmanovsky, Naira Hovakimyan
0
0
This paper presents an uncertainty compensation-based robust adaptive model predictive control (MPC) framework for linear systems with both matched and unmatched nonlinear uncertainties subject to both state and input constraints. In particular, the proposed control framework leverages an L1 adaptive controller (L1AC) to compensate for the matched uncertainties and to provide guaranteed uniform bounds on the error between the states and control inputs of the actual system and those of a nominal i.e., uncertainty-free, system. The performance bounds provided by the L1AC are then used to tighten the state and control constraints of the actual system, and a model predictive controller is designed for the nominal system with the tightened constraints. The proposed control framework, which we denote as uncertainty compensation-based MPC (UC-MPC), guarantees constraint satisfaction and achieves improved performance compared with existing methods. Simulation results on a flight control example demonstrate the benefits of the proposed framework.
4/4/2024