Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks
2406.04317
0
0

Abstract
Bayesian neural networks (BNN) promise to combine the predictive performance of neural networks with principled uncertainty modeling important for safety-critical systems and decision making. However, posterior uncertainty estimates depend on the choice of prior, and finding informative priors in weight-space has proven difficult. This has motivated variational inference (VI) methods that pose priors directly on the function generated by the BNN rather than on weights. In this paper, we address a fundamental issue with such function-space VI approaches pointed out by Burt et al. (2020), who showed that the objective function (ELBO) is negative infinite for most priors of interest. Our solution builds on generalized VI (Knoblauch et al., 2019) with the regularized KL divergence (Quang, 2019) and is, to the best of our knowledge, the first well-defined variational objective for function-space inference in BNNs with Gaussian process (GP) priors. Experiments show that our method incorporates the properties specified by the GP prior on synthetic and small real-world data sets, and provides competitive uncertainty estimates for regression, classification and out-of-distribution detection compared to BNN baselines with both function and weight-space priors.
Create account to get full access
Overview
- This paper proposes a new approach for performing variational inference in Bayesian neural networks, known as Regularized KL-Divergence (RegKL).
- The key idea is to regularize the KL divergence term in the variational objective to ensure the variational distribution is well-defined in function space.
- This addresses issues with existing variational inference methods, which can lead to pathological behavior and undefined function distributions.
- The authors demonstrate the effectiveness of RegKL on several benchmark tasks, showing improved performance and stability compared to standard variational inference.
Plain English Explanation
Bayesian neural networks are a powerful machine learning technique that can capture uncertainty in the model's predictions. However, performing variational inference - a key step in training these models - can be challenging. Existing methods can sometimes lead to mathematical issues, resulting in the model not being well-defined in the space of functions.
The Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks paper proposes a new approach called Regularized KL-Divergence (RegKL) to address this problem. The key idea is to add a regularization term to the standard variational objective, which ensures the variational distribution (the model's uncertainty) remains well-defined mathematically.
By doing this, the authors show that RegKL can improve the performance and stability of Bayesian neural networks compared to existing variational inference methods. The paper demonstrates the benefits of RegKL on several benchmark tasks, highlighting its potential to advance the state-of-the-art in Bayesian deep learning.
Technical Explanation
The Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks paper presents a new approach to performing variational inference in Bayesian neural networks, called Regularized KL-Divergence (RegKL).
The key technical insight is that standard variational inference methods, such as mean-field variational inference, can lead to pathological behavior and undefined function distributions in the function space of Bayesian neural networks. To address this, the authors propose regularizing the KL divergence term in the variational objective, which ensures the variational distribution remains well-defined.
Specifically, the authors introduce an additional regularization term that penalizes deviations of the variational distribution from a pre-specified reference distribution. They show that this regularization leads to a well-defined variational distribution in function space, addressing the issues with existing methods.
The authors evaluate RegKL on several benchmark tasks, including image classification and regression problems. The results demonstrate that RegKL outperforms standard variational inference techniques in terms of performance and stability, highlighting its potential to advance the state-of-the-art in Bayesian deep learning.
Critical Analysis
The Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks paper presents a novel and well-motivated approach to addressing the challenges of performing variational inference in Bayesian neural networks. The authors clearly identify the limitations of existing methods and provide a principled solution to the problem.
One potential limitation of the proposed RegKL approach is the choice of the reference distribution used for regularization. The authors suggest using a Gaussian distribution, but it is unclear how sensitive the method is to this choice or how to optimally select the reference distribution for a given problem. Further investigation into the impact of the reference distribution and potential extensions to more flexible choices could be a valuable area for future research.
Additionally, while the authors demonstrate the effectiveness of RegKL on several benchmark tasks, it would be interesting to see how the method performs on larger-scale, real-world problems that are more representative of the challenges faced in practical applications of Bayesian deep learning. Exploring the scalability and robustness of RegKL in these more complex settings could provide valuable insights.
Overall, the Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks paper presents a promising approach to addressing an important problem in Bayesian neural networks. The authors' technical contributions and empirical results suggest that RegKL is a valuable addition to the toolbox of Bayesian deep learning researchers and practitioners.
Conclusion
The Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks paper introduces a novel approach called Regularized KL-Divergence (RegKL) to perform variational inference in Bayesian neural networks. The key idea is to regularize the KL divergence term in the variational objective, ensuring the variational distribution remains well-defined in function space.
The authors demonstrate that RegKL can lead to improved performance and stability compared to standard variational inference methods, which can suffer from pathological behavior and undefined function distributions. This work represents an important step forward in addressing the challenges of Bayesian deep learning and could have significant implications for a wide range of applications that can benefit from the uncertainty quantification capabilities of Bayesian neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Variational inference, Mixture of Gaussians, Bayesian Machine Learning
Tom Huix, Anna Korba, Alain Durmus, Eric Moulines
0
0
Variational inference (VI) is a popular approach in Bayesian inference, that looks for the best approximation of the posterior distribution within a parametric family, minimizing a loss that is typically the (reverse) Kullback-Leibler (KL) divergence. Despite its empirical success, the theoretical properties of VI have only received attention recently, and mostly when the parametric family is the one of Gaussians. This work aims to contribute to the theoretical study of VI in the non-Gaussian case by investigating the setting of Mixture of Gaussians with fixed covariance and constant weights. In this view, VI over this specific family can be casted as the minimization of a Mollified relative entropy, i.e. the KL between the convolution (with respect to a Gaussian kernel) of an atomic measure supported on Diracs, and the target distribution. The support of the atomic measure corresponds to the localization of the Gaussian components. Hence, solving variational inference becomes equivalent to optimizing the positions of the Diracs (the particles), which can be done through gradient descent and takes the form of an interacting particle system. We study two sources of error of variational inference in this context when optimizing the mollified relative entropy. The first one is an optimization result, that is a descent lemma establishing that the algorithm decreases the objective at each iteration. The second one is an approximation error, that upper bounds the objective between an optimal finite mixture and the target distribution.
6/11/2024
🤯
Posterior and variational inference for deep neural networks with heavy-tailed weights
Ismael Castillo, Paul Egels
0
0
We consider deep neural networks in a Bayesian framework with a prior distribution sampling the network weights at random. Following a recent idea of Agapiou and Castillo (2023), who show that heavy-tailed prior distributions achieve automatic adaptation to smoothness, we introduce a simple Bayesian deep learning prior based on heavy-tailed weights and ReLU activation. We show that the corresponding posterior distribution achieves near-optimal minimax contraction rates, simultaneously adaptive to both intrinsic dimension and smoothness of the underlying function, in a variety of contexts including nonparametric regression, geometric data and Besov spaces. While most works so far need a form of model selection built-in within the prior distribution, a key aspect of our approach is that it does not require to sample hyperparameters to learn the architecture of the network. We also provide variational Bayes counterparts of the results, that show that mean-field variational approximations still benefit from near-optimal theoretical support.
6/6/2024
How to train your VAE
Mariano Rivera
0
0
Variational Autoencoders (VAEs) have become a cornerstone in generative modeling and representation learning within machine learning. This paper explores a nuanced aspect of VAEs, focusing on interpreting the Kullback-Leibler (KL) Divergence, a critical component within the Evidence Lower Bound (ELBO) that governs the trade-off between reconstruction accuracy and regularization. Meanwhile, the KL Divergence enforces alignment between latent variable distributions and a prior imposing a structure on the overall latent space but leaves individual variable distributions unconstrained. The proposed method redefines the ELBO with a mixture of Gaussians for the posterior probability, introduces a regularization term to prevent variance collapse, and employs a PatchGAN discriminator to enhance texture realism. Implementation details involve ResNetV2 architectures for both the Encoder and Decoder. The experiments demonstrate the ability to generate realistic faces, offering a promising solution for enhancing VAE-based generative models.
6/26/2024
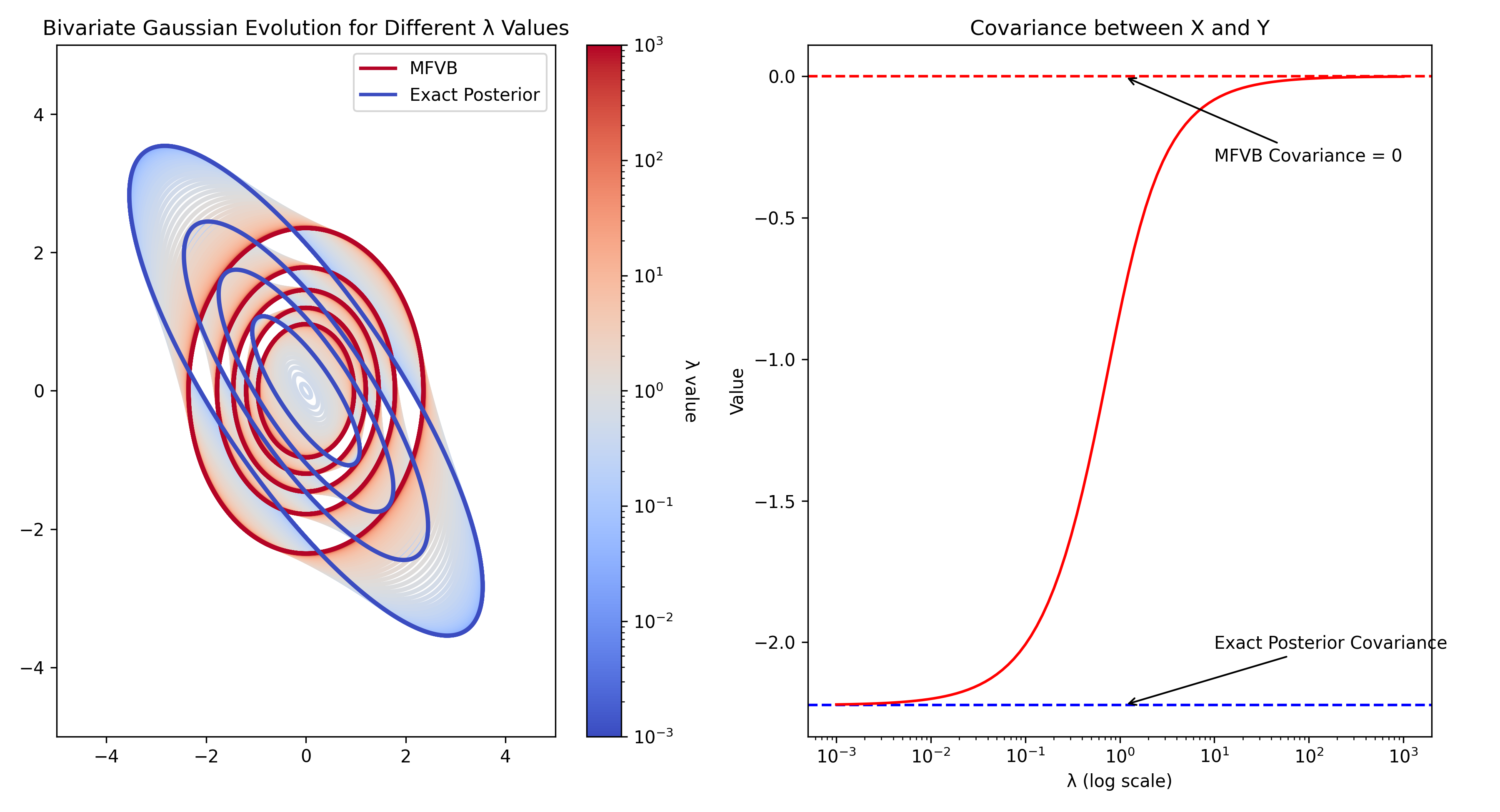
Extending Mean-Field Variational Inference via Entropic Regularization: Theory and Computation
Bohan Wu, David Blei
0
0
Variational inference (VI) has emerged as a popular method for approximate inference for high-dimensional Bayesian models. In this paper, we propose a novel VI method that extends the naive mean field via entropic regularization, referred to as $Xi$-variational inference ($Xi$-VI). $Xi$-VI has a close connection to the entropic optimal transport problem and benefits from the computationally efficient Sinkhorn algorithm. We show that $Xi$-variational posteriors effectively recover the true posterior dependency, where the dependence is downweighted by the regularization parameter. We analyze the role of dimensionality of the parameter space on the accuracy of $Xi$-variational approximation and how it affects computational considerations, providing a rough characterization of the statistical-computational trade-off in $Xi$-VI. We also investigate the frequentist properties of $Xi$-VI and establish results on consistency, asymptotic normality, high-dimensional asymptotics, and algorithmic stability. We provide sufficient criteria for achieving polynomial-time approximate inference using the method. Finally, we demonstrate the practical advantage of $Xi$-VI over mean-field variational inference on simulated and real data.
4/16/2024