Extending Mean-Field Variational Inference via Entropic Regularization: Theory and Computation
2404.09113
0
0
Abstract
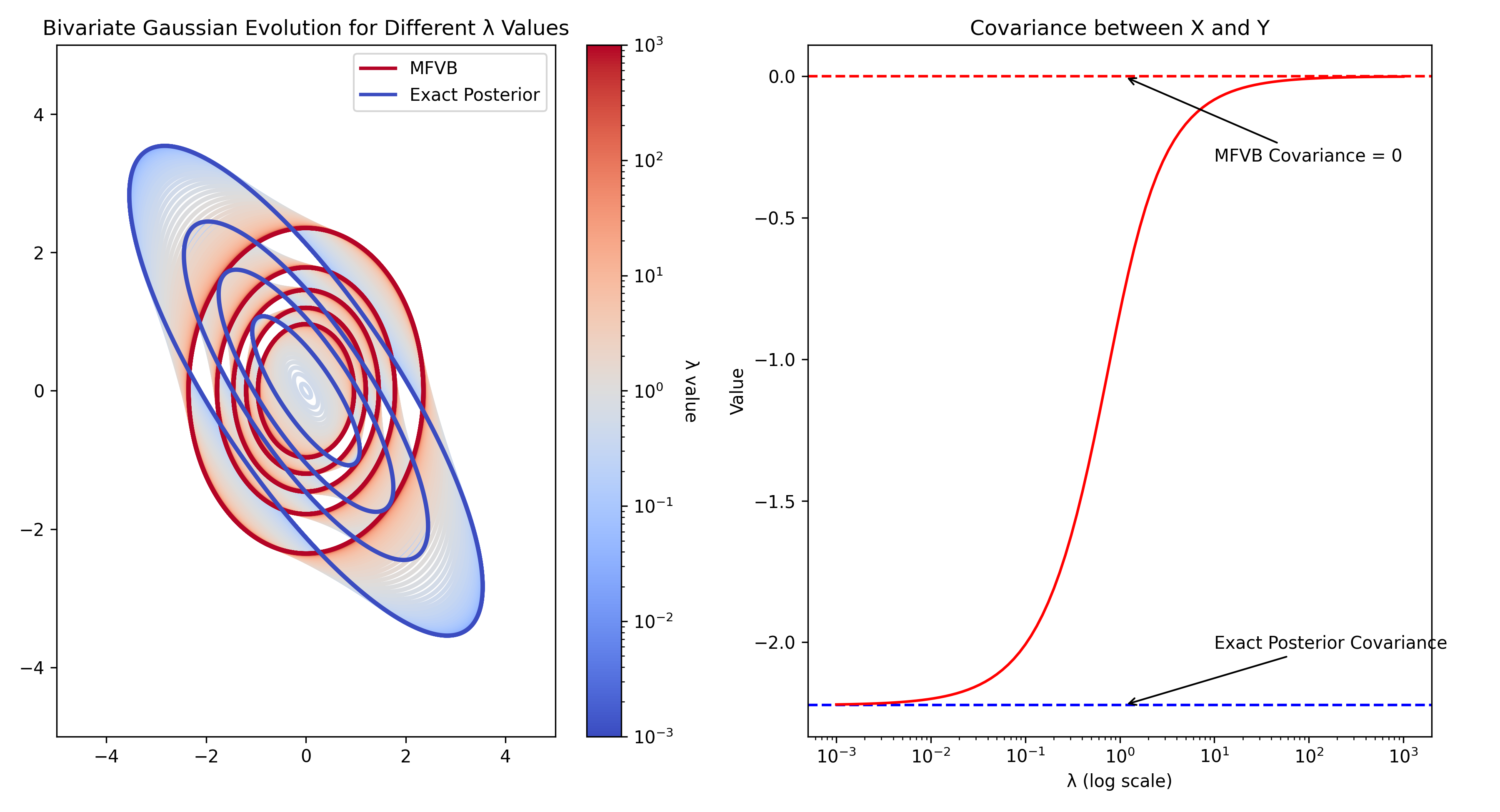
Variational inference (VI) has emerged as a popular method for approximate inference for high-dimensional Bayesian models. In this paper, we propose a novel VI method that extends the naive mean field via entropic regularization, referred to as $Xi$-variational inference ($Xi$-VI). $Xi$-VI has a close connection to the entropic optimal transport problem and benefits from the computationally efficient Sinkhorn algorithm. We show that $Xi$-variational posteriors effectively recover the true posterior dependency, where the dependence is downweighted by the regularization parameter. We analyze the role of dimensionality of the parameter space on the accuracy of $Xi$-variational approximation and how it affects computational considerations, providing a rough characterization of the statistical-computational trade-off in $Xi$-VI. We also investigate the frequentist properties of $Xi$-VI and establish results on consistency, asymptotic normality, high-dimensional asymptotics, and algorithmic stability. We provide sufficient criteria for achieving polynomial-time approximate inference using the method. Finally, we demonstrate the practical advantage of $Xi$-VI over mean-field variational inference on simulated and real data.
Create account to get full access
Overview
- This paper introduces a new approach called Ξ-variational inference (Ξ-VI) that extends mean-field variational inference (MFVI) using entropic regularization.
- The authors provide theoretical analysis of Ξ-VI, showing it can improve model fitting and approximate posterior estimation compared to MFVI.
- They also present an efficient computational framework for implementing Ξ-VI, demonstrating its effectiveness on several real-world datasets.
Plain English Explanation
Variational inference is a popular technique in machine learning for approximating complex probability distributions. The basic idea is to find a simpler distribution that closely matches the true, underlying distribution. This is useful when the true distribution is too complicated to work with directly.
Traditional mean-field variational inference (MFVI) makes some simplifying assumptions that can limit its accuracy. This paper proposes a new method called Ξ-variational inference (Ξ-VI) that adds an extra "regularization" term to the optimization.
The key insight is that this regularization can help the approximating distribution better capture the structure of the true distribution, without making overly restrictive assumptions. The authors show that Ξ-VI can lead to more accurate model fitting and better approximation of the true posterior distribution.
Importantly, the paper also provides an efficient computational framework for implementing Ξ-VI in practice. They demonstrate that Ξ-VI outperforms standard MFVI on several real-world datasets, highlighting its potential benefits for a wide range of machine learning applications.
Technical Explanation
The paper introduces a new variational inference framework called Ξ-variational inference (Ξ-VI) that extends mean-field variational inference (MFVI) using entropic regularization.
In standard MFVI, the goal is to find a simpler, factorized distribution q(z) that approximates the true, complex posterior distribution p(z|x). MFVI does this by minimizing the Kullback-Leibler (KL) divergence between q(z) and p(z|x).
Ξ-VI introduces an additional "Ξ-divergence" regularization term to this objective. This Ξ-divergence encourages the approximating distribution q(z) to have higher entropy, i.e., to be more spread out. The authors show this can lead to better model fitting and posterior approximation compared to standard MFVI.
Importantly, the paper provides a detailed computational framework for optimizing the Ξ-VI objective. They derive efficient coordinate ascent updates and show how to leverage variational Fourier features to scale Ξ-VI to high-dimensional problems.
The empirical evaluation demonstrates the benefits of Ξ-VI on several real-world datasets, including topic modeling, matrix factorization, and deep generative modeling tasks. Ξ-VI consistently outperforms standard MFVI in terms of test log-likelihood, held-out perplexity, and other relevant metrics.
Critical Analysis
The paper provides a strong theoretical and empirical case for the benefits of Ξ-variational inference over standard mean-field variational inference. The authors carefully analyze the theoretical properties of Ξ-VI and demonstrate its advantages through extensive experiments.
However, the paper does not address some potential limitations of the approach. For example, the added regularization term in Ξ-VI increases the computational complexity compared to MFVI, which could be a concern for large-scale applications. Scalability and efficiency of the method may require further investigation.
Additionally, the paper focuses on approximating the posterior distribution, but does not discuss the impact of Ξ-VI on downstream task performance, such as prediction accuracy. It would be valuable to see how the improved posterior approximation translates to real-world application outcomes.
Overall, this paper makes a compelling case for Ξ-VI as a promising extension of mean-field variational inference. The theoretical insights and empirical results are quite promising, but further research is needed to fully understand the method's strengths, weaknesses, and practical implications.
Conclusion
This paper introduces a new variational inference framework called Ξ-variational inference (Ξ-VI) that extends mean-field variational inference (MFVI) using entropic regularization. Ξ-VI can lead to more accurate model fitting and better approximation of the true posterior distribution compared to standard MFVI.
The authors provide a detailed theoretical analysis of Ξ-VI and present an efficient computational framework for implementing the method. Empirical results on several real-world datasets demonstrate the benefits of Ξ-VI, suggesting it could be a valuable tool for a wide range of machine learning applications that rely on variational inference.
While the paper makes a strong case for Ξ-VI, further research is needed to fully understand its strengths, weaknesses, and practical implications, particularly in terms of scalability and downstream task performance. Overall, this work represents an exciting advancement in the field of variational inference and probabilistic modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Variational inference, Mixture of Gaussians, Bayesian Machine Learning
Tom Huix, Anna Korba, Alain Durmus, Eric Moulines
0
0
Variational inference (VI) is a popular approach in Bayesian inference, that looks for the best approximation of the posterior distribution within a parametric family, minimizing a loss that is typically the (reverse) Kullback-Leibler (KL) divergence. Despite its empirical success, the theoretical properties of VI have only received attention recently, and mostly when the parametric family is the one of Gaussians. This work aims to contribute to the theoretical study of VI in the non-Gaussian case by investigating the setting of Mixture of Gaussians with fixed covariance and constant weights. In this view, VI over this specific family can be casted as the minimization of a Mollified relative entropy, i.e. the KL between the convolution (with respect to a Gaussian kernel) of an atomic measure supported on Diracs, and the target distribution. The support of the atomic measure corresponds to the localization of the Gaussian components. Hence, solving variational inference becomes equivalent to optimizing the positions of the Diracs (the particles), which can be done through gradient descent and takes the form of an interacting particle system. We study two sources of error of variational inference in this context when optimizing the mollified relative entropy. The first one is an optimization result, that is a descent lemma establishing that the algorithm decreases the objective at each iteration. The second one is an approximation error, that upper bounds the objective between an optimal finite mixture and the target distribution.
6/11/2024

New!Particle Semi-Implicit Variational Inference
Jen Ning Lim, Adam M. Johansen
0
0
Semi-implicit variational inference (SIVI) enriches the expressiveness of variational families by utilizing a kernel and a mixing distribution to hierarchically define the variational distribution. Existing SIVI methods parameterize the mixing distribution using implicit distributions, leading to intractable variational densities. As a result, directly maximizing the evidence lower bound (ELBO) is not possible and so, they resort to either: optimizing bounds on the ELBO, employing costly inner-loop Markov chain Monte Carlo runs, or solving minimax objectives. In this paper, we propose a novel method for SIVI called Particle Variational Inference (PVI) which employs empirical measures to approximate the optimal mixing distributions characterized as the minimizer of a natural free energy functional via a particle approximation of an Euclidean--Wasserstein gradient flow. This approach means that, unlike prior works, PVI can directly optimize the ELBO; furthermore, it makes no parametric assumption about the mixing distribution. Our empirical results demonstrate that PVI performs favourably against other SIVI methods across various tasks. Moreover, we provide a theoretical analysis of the behaviour of the gradient flow of a related free energy functional: establishing the existence and uniqueness of solutions as well as propagation of chaos results.
7/2/2024
🤯
Convergence of coordinate ascent variational inference for log-concave measures via optimal transport
Manuel Arnese, Daniel Lacker
0
0
Mean field variational inference (VI) is the problem of finding the closest product (factorized) measure, in the sense of relative entropy, to a given high-dimensional probability measure $rho$. The well known Coordinate Ascent Variational Inference (CAVI) algorithm aims to approximate this product measure by iteratively optimizing over one coordinate (factor) at a time, which can be done explicitly. Despite its popularity, the convergence of CAVI remains poorly understood. In this paper, we prove the convergence of CAVI for log-concave densities $rho$. If additionally $log rho$ has Lipschitz gradient, we find a linear rate of convergence, and if also $rho$ is strongly log-concave, we find an exponential rate. Our analysis starts from the observation that mean field VI, while notoriously non-convex in the usual sense, is in fact displacement convex in the sense of optimal transport when $rho$ is log-concave. This allows us to adapt techniques from the optimization literature on coordinate descent algorithms in Euclidean space.
4/16/2024

Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks
Tristan Cinquin, Robert Bamler
0
0
Bayesian neural networks (BNN) promise to combine the predictive performance of neural networks with principled uncertainty modeling important for safety-critical systems and decision making. However, posterior uncertainty estimates depend on the choice of prior, and finding informative priors in weight-space has proven difficult. This has motivated variational inference (VI) methods that pose priors directly on the function generated by the BNN rather than on weights. In this paper, we address a fundamental issue with such function-space VI approaches pointed out by Burt et al. (2020), who showed that the objective function (ELBO) is negative infinite for most priors of interest. Our solution builds on generalized VI (Knoblauch et al., 2019) with the regularized KL divergence (Quang, 2019) and is, to the best of our knowledge, the first well-defined variational objective for function-space inference in BNNs with Gaussian process (GP) priors. Experiments show that our method incorporates the properties specified by the GP prior on synthetic and small real-world data sets, and provides competitive uncertainty estimates for regression, classification and out-of-distribution detection compared to BNN baselines with both function and weight-space priors.
6/7/2024