Reinforcement Learning in Agent-Based Market Simulation: Unveiling Realistic Stylized Facts and Behavior
2403.19781
0
0
🏅
Abstract
Investors and regulators can greatly benefit from a realistic market simulator that enables them to anticipate the consequences of their decisions in real markets. However, traditional rule-based market simulators often fall short in accurately capturing the dynamic behavior of market participants, particularly in response to external market impact events or changes in the behavior of other participants. In this study, we explore an agent-based simulation framework employing reinforcement learning (RL) agents. We present the implementation details of these RL agents and demonstrate that the simulated market exhibits realistic stylized facts observed in real-world markets. Furthermore, we investigate the behavior of RL agents when confronted with external market impacts, such as a flash crash. Our findings shed light on the effectiveness and adaptability of RL-based agents within the simulation, offering insights into their response to significant market events.
Create account to get full access
Introduction
The paper discusses the importance of understanding how financial markets react to various events and proposes a simulation framework using reinforcement learning (RL) agents to model market behavior. Traditional agent-based market simulators use rule-based agents, which fail to capture realistic market dynamics due to their rigid, hard-coded nature. In contrast, RL agents can learn and adapt to changing market conditions, mirroring the behavior of real-world investors and enhancing the realism of the simulation.
The paper highlights successful applications of machine learning techniques in financial problems and presents RL as a suitable approach for simulating financial markets. While previous works have utilized RL agents for simplified investment problems or dealer markets, the proposed framework aims to simulate a complete continuous double auction stock market using complex RL-based agents.
The study employs a small group of representative RL agents and compares the simulation results with a system composed of rule-based zero-intelligence agents and real market data. The results obtained using the RL agents' system are comparable to real data, and the system demonstrates the ability to adapt to changing market conditions.
Important Concepts
The paper section covers two key concepts:
Reinforcement Learning (RL) Agents:
- RL agents solve problems modeled as Markov Decision Processes (MDPs)
- An MDP consists of states, actions, rewards, transition probabilities, and a discount factor
- The agent's goal is to find an optimal policy to maximize expected cumulative discounted rewards
- The Proximal Policy Optimization (PPO) method is used to optimize the RL agents
Limit Order Books (LOBs) in Continuous Double Auction (CDA) Markets:
- Traditional financial exchanges use the CDA market model
- The CDA maintains two LOBs, one for buy orders and one for sell orders
- Traders place limit orders specifying desired price ranges for buying/selling assets
- Market orders execute immediately against available limit orders in the LOBs
- Limit orders remain in the LOBs until matched with a market order
System and Agents
The system contains a machine engine that organizes limit order books and settles trades, as well as a brokerage center that tracks each agent's account, including their buying power and assets. All agents place market and limit orders to the matching engine which runs a continuous double auction market model.
There are two types of agents: liquidity-taking (LT) agents and market-making (MM) agents. Each agent is formulated as a reinforcement learning agent, observing the system independently, selecting actions (orders), receiving feedback (rewards), and optimizing its strategy.
For MM agents, the observation space includes mid-prices, order book levels, liquidity provision percentage, inventory, and buying power. Their action space determines the size and prices of limit orders placed on both sides of the order book. The reward function incentivizes increasing profit and loss (PnL) while penalizing PnL fluctuations from inventory and price oscillations, and minimizing the difference between actual and target liquidity provision.
For LT agents, the observation space is similar without the liquidity provision percentage. Their action space allows placing market orders of a fixed size or skipping. The reward function incentivizes increasing PnL while penalizing inventory risk, and minimizing the difference between actual and target order frequencies.
The simulation details include initializing agents with random parameters, running them in parallel threads, collecting experiences independently, and training using proximal policy optimization. The simulation is implemented within a real-time trading platform, introducing realistic network latency.
Experiment Design
The paper outlines a study to evaluate if reinforcement learning (RL) agents can simulate realistic financial markets. Two key aspects are analyzed: statistical characteristics and market responsiveness.
Statistical Characteristics: The study examines if the RL agent simulations exhibit well-known stylized facts observed in real financial markets, such as heavy-tailed return distributions, absence of autocorrelation in returns, volatility clustering, etc. The agents' inventory evolution and profit sources are also examined.
Market Responsiveness: The study introduces external impacts like large sell orders (flash sales) and periods of directional trading to observe price impacts and changes in market makers' strategies, such as widening spreads. This tests if the RL agents respond similarly to real markets.
Continual Learning: Three agent groups are compared - one with continual training during simulation, one without further training, and an untrained group. This evaluates if continual learning improves adaptability to changing markets.
The RL agent simulations are compared to a baseline Zero-Intelligence agent model and real data to assess how realistic the generated markets are across different statistical properties and responsiveness scenarios.
Experiment Results
The paper section analyzes the statistical characteristics of simulated asset prices generated by reinforcement learning (RL) agents and compares them to real market data. Key findings include:
Heavy tails and kurtosis decay: The simulated prices from RL agents exhibit heavy-tailed return distributions similar to real data, with kurtosis decreasing as sampling frequency reduces, matching empirical observations.
Absence of autocorrelations: The simulated returns show a strong negative autocorrelation at the first lag, decaying to zero for larger lags, consistent with the real data bounce between bid and ask prices.
Slow decay of autocorrelation for absolute returns: The autocorrelation of absolute returns decays slowly with time lags in both real data and simulations, indicating long-range time dependency in return magnitudes.
Volatility clustering: The simulations capture the volatility clustering effect observed in real markets through decaying autocorrelations of squared returns.
Market making behavior: The RL market making agents control inventory well and profit from providing liquidity rather than holding positions, demonstrating realistic market making strategies.
The section also analyzes market responsiveness to external events like flash sales and informed trading through experiments. The continuously trained RL agents adapt order placement strategies according to market conditions like order book imbalance and price trends, exhibiting behavior consistent with financial literature.
Conclusion
The paper modifies the formulation of reinforcement learning (RL) agents and implements a highly realistic simulation platform. The simulation results are compared against real data and a market simulated using zero intelligence traders. The results show realistic market characteristics and responsiveness to external factors. The authors find that continual learning RL agents produce the most realistic market simulation and can adapt to changing market conditions. However, calibrating an agent-based system remains a challenging problem, as the system is non-stationary and runs in real-time. The authors mention previous work on calibrating RL-based multi-agent systems but note that applying those algorithms to their system is challenging. They plan to address this and other issues in future work.
Appendix
The provided text presents additional simulation results and configuration details from the research study.
7.1 Additional Simulation Results:
- Figure 1 shows a quantile-quantile plot comparing the return distributions of simulations against real data for all agent groups.
- Figures 2 and 3 display autocorrelation plots for price returns and absolute returns, respectively, comparing the testing and untrained agent groups.
- Figure 4 presents volatility clustering analysis for the testing and untrained groups.
- Table 1 provides the kurtosis and inventory risk values for the continual training, testing, and untrained agent groups.
7.2 Simulation Configuration:
- Table 2 lists the agent configurations (parameter values) used for the training, testing, and untrained groups.
- Table 3 describes special setups for flash sale and informed long-term (LT) trader simulations.
- Table 4 shows how market characteristics like spread, depth, volume, and profit/loss (PNL) change when agents' hyperparameters are manipulated.
- Table 5 outlines the specific hyperparameter setups used for examining PNL and market share under different conditions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
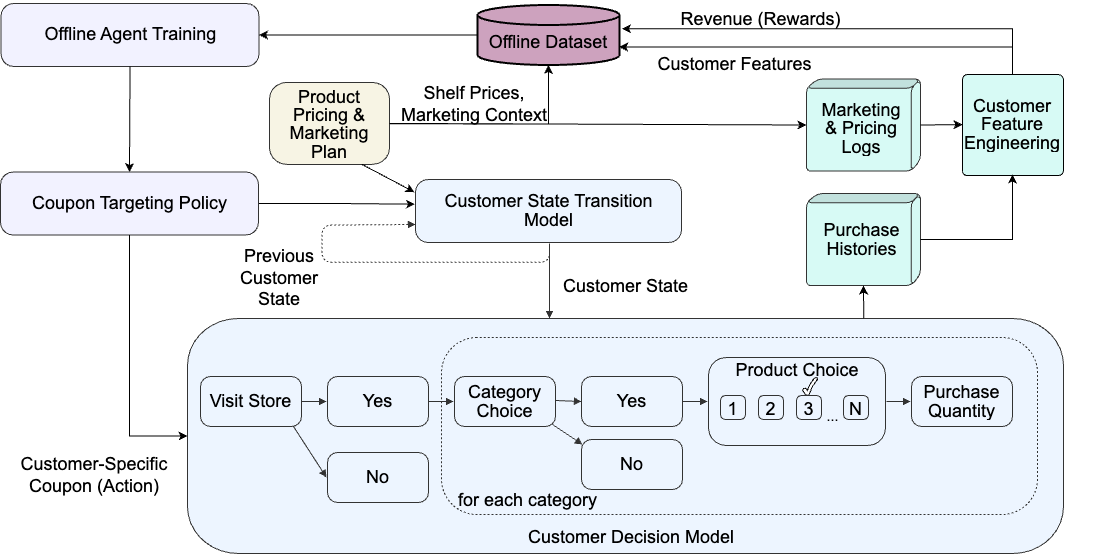
Simulation-Based Benchmarking of Reinforcement Learning Agents for Personalized Retail Promotions
Yu Xia, Sriram Narayanamoorthy, Zhengyuan Zhou, Joshua Mabry
0
0
The development of open benchmarking platforms could greatly accelerate the adoption of AI agents in retail. This paper presents comprehensive simulations of customer shopping behaviors for the purpose of benchmarking reinforcement learning (RL) agents that optimize coupon targeting. The difficulty of this learning problem is largely driven by the sparsity of customer purchase events. We trained agents using offline batch data comprising summarized customer purchase histories to help mitigate this effect. Our experiments revealed that contextual bandit and deep RL methods that are less prone to over-fitting the sparse reward distributions significantly outperform static policies. This study offers a practical framework for simulating AI agents that optimize the entire retail customer journey. It aims to inspire the further development of simulation tools for retail AI systems.
5/20/2024

CtRL-Sim: Reactive and Controllable Driving Agents with Offline Reinforcement Learning
Luke Rowe, Roger Girgis, Anthony Gosselin, Bruno Carrez, Florian Golemo, Felix Heide, Liam Paull, Christopher Pal
0
0
Evaluating autonomous vehicle stacks (AVs) in simulation typically involves replaying driving logs from real-world recorded traffic. However, agents replayed from offline data are not reactive and hard to intuitively control. Existing approaches address these challenges by proposing methods that rely on heuristics or generative models of real-world data but these approaches either lack realism or necessitate costly iterative sampling procedures to control the generated behaviours. In this work, we take an alternative approach and propose CtRL-Sim, a method that leverages return-conditioned offline reinforcement learning to efficiently generate reactive and controllable traffic agents. Specifically, we process real-world driving data through a physics-enhanced Nocturne simulator to generate a diverse offline reinforcement learning dataset, annotated with various reward terms. With this dataset, we train a return-conditioned multi-agent behaviour model that allows for fine-grained manipulation of agent behaviours by modifying the desired returns for the various reward components. This capability enables the generation of a wide range of driving behaviours beyond the scope of the initial dataset, including adversarial behaviours. We demonstrate that CtRL-Sim can generate diverse and realistic safety-critical scenarios while providing fine-grained control over agent behaviours.
6/18/2024

What Teaches Robots to Walk, Teaches Them to Trade too -- Regime Adaptive Execution using Informed Data and LLMs
Raeid Saqur
0
0
Machine learning techniques applied to the problem of financial market forecasting struggle with dynamic regime switching, or underlying correlation and covariance shifts in true (hidden) market variables. Drawing inspiration from the success of reinforcement learning in robotics, particularly in agile locomotion adaptation of quadruped robots to unseen terrains, we introduce an innovative approach that leverages world knowledge of pretrained LLMs (aka. 'privileged information' in robotics) and dynamically adapts them using intrinsic, natural market rewards using LLM alignment technique we dub as Reinforcement Learning from Market Feedback (**RLMF**). Strong empirical results demonstrate the efficacy of our method in adapting to regime shifts in financial markets, a challenge that has long plagued predictive models in this domain. The proposed algorithmic framework outperforms best-performing SOTA LLM models on the existing (FLARE) benchmark stock-movement (SM) tasks by more than 15% improved accuracy. On the recently proposed NIFTY SM task, our adaptive policy outperforms the SOTA best performing trillion parameter models like GPT-4. The paper details the dual-phase, teacher-student architecture and implementation of our model, the empirical results obtained, and an analysis of the role of language embeddings in terms of Information Gain.
6/26/2024

Scaling Population-Based Reinforcement Learning with GPU Accelerated Simulation
Asad Ali Shahid, Yashraj Narang, Vincenzo Petrone, Enrico Ferrentino, Ankur Handa, Dieter Fox, Marco Pavone, Loris Roveda
0
0
In recent years, deep reinforcement learning (RL) has shown its effectiveness in solving complex continuous control tasks like locomotion and dexterous manipulation. However, this comes at the cost of an enormous amount of experience required for training, exacerbated by the sensitivity of learning efficiency and the policy performance to hyperparameter selection, which often requires numerous trials of time-consuming experiments. This work introduces a Population-Based Reinforcement Learning (PBRL) approach that exploits a GPU-accelerated physics simulator to enhance the exploration capabilities of RL by concurrently training multiple policies in parallel. The PBRL framework is applied to three state-of-the-art RL algorithms - PPO, SAC, and DDPG - dynamically adjusting hyperparameters based on the performance of learning agents. The experiments are performed on four challenging tasks in Isaac Gym - Anymal Terrain, Shadow Hand, Humanoid, Franka Nut Pick - by analyzing the effect of population size and mutation mechanisms for hyperparameters. The results demonstrate that PBRL agents outperform non-evolutionary baseline agents across tasks essential for humanoid robots, such as bipedal locomotion, manipulation, and grasping in unstructured environments. The trained agents are finally deployed in the real world for the Franka Nut Pick manipulation task. To our knowledge, this is the first sim-to-real attempt for successfully deploying PBRL agents on real hardware. Code and videos of the learned policies are available on our project website (https://sites.google.com/view/pbrl).
6/26/2024