Simulation-Based Benchmarking of Reinforcement Learning Agents for Personalized Retail Promotions

0
Sign in to get full access
Overview
- This paper explores the use of reinforcement learning (RL) agents to personalize retail promotions in a simulated environment.
- The researchers developed a simulation framework that models customer behavior and responses to various promotional strategies.
- They benchmarked the performance of different RL agents in this simulated environment to identify the most effective approaches for personalizing retail promotions.
Plain English Explanation
In this research, the scientists created a virtual world that mimics a retail setting, including virtual customers with different preferences and behaviors. They then tested various reinforcement learning agents, which are AI systems that learn from trial and error, to see which ones could best personalize promotional offers for these virtual customers.
The goal was to find the most effective RL agents for real-world retail settings, where companies need to tailor their promotions to individual customers to maximize sales and customer satisfaction. By running these experiments in a simulated environment, the researchers could quickly test and compare different RL approaches without the risks and costs of experimenting in the real world.
Technical Explanation
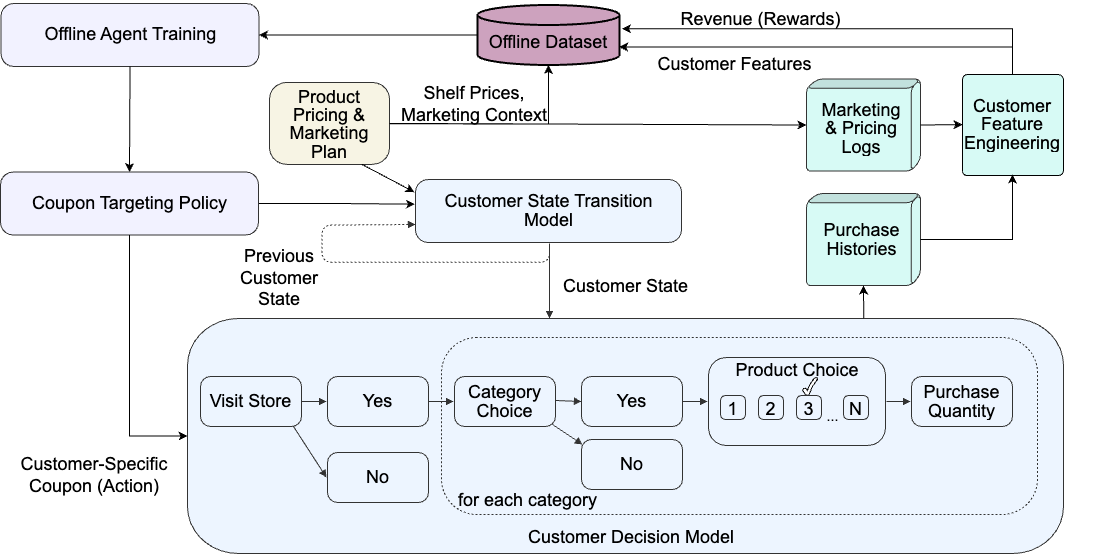
The researchers developed a simulation environment that models the interactions between virtual customers and a retail business. The simulation includes factors like customer demographics, product preferences, and responses to different promotional strategies. This allowed the researchers to create a controlled setting to test the performance of various reinforcement learning agents in personalizing retail promotions.
The researchers benchmarked the performance of several RL agents, including those based on model-based and model-free approaches. They evaluated metrics such as revenue, customer satisfaction, and the ability to learn customer preferences over time. This allowed them to identify the most effective RL agents for personalizing retail promotions in the simulated environment.
Critical Analysis
The paper provides a robust simulation framework for testing RL agents in retail promotion scenarios, which is a valuable contribution to the field. However, the researchers acknowledge that the simulation may not fully capture the complexities of real-world retail environments, such as the impact of external factors or the potential for customer behavior to change over time.
Additionally, the paper does not provide detailed information on the specific RL algorithms or architectures tested, making it difficult to assess the novelty or generalizability of the findings. Further research may be needed to validate the results in real-world retail settings and explore the potential limitations of the simulation-based approach.
Conclusion
This research demonstrates the potential of using reinforcement learning to personalize retail promotions in a simulated environment. By benchmarking the performance of different RL agents, the researchers were able to identify promising approaches for optimizing promotional strategies and enhancing customer experiences in the retail sector. The insights from this work could inform the development of more effective personalization and recommendation systems for retailers, ultimately improving their competitiveness and profitability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Simulation-Based Benchmarking of Reinforcement Learning Agents for Personalized Retail Promotions
Yu Xia, Sriram Narayanamoorthy, Zhengyuan Zhou, Joshua Mabry
The development of open benchmarking platforms could greatly accelerate the adoption of AI agents in retail. This paper presents comprehensive simulations of customer shopping behaviors for the purpose of benchmarking reinforcement learning (RL) agents that optimize coupon targeting. The difficulty of this learning problem is largely driven by the sparsity of customer purchase events. We trained agents using offline batch data comprising summarized customer purchase histories to help mitigate this effect. Our experiments revealed that contextual bandit and deep RL methods that are less prone to over-fitting the sparse reward distributions significantly outperform static policies. This study offers a practical framework for simulating AI agents that optimize the entire retail customer journey. It aims to inspire the further development of simulation tools for retail AI systems.
Read more5/20/2024

0
An Extremely Data-efficient and Generative LLM-based Reinforcement Learning Agent for Recommenders
Shuang Feng, Grace Feng
Recent advancements in large language models (LLMs) have enabled understanding webpage contexts, product details, and human instructions. Utilizing LLMs as the foundational architecture for either reward models or policies in reinforcement learning has gained popularity -- a notable achievement is the success of InstructGPT. RL algorithms have been instrumental in maximizing long-term customer satisfaction and avoiding short-term, myopic goals in industrial recommender systems, which often rely on deep learning models to predict immediate clicks or purchases. In this project, several RL methods are implemented and evaluated using the WebShop benchmark environment, data, simulator, and pre-trained model checkpoints. The goal is to train an RL agent to maximize the purchase reward given a detailed human instruction describing a desired product. The RL agents are developed by fine-tuning a pre-trained BERT model with various objectives, learning from preferences without a reward model, and employing contemporary training techniques such as Proximal Policy Optimization (PPO) as used in InstructGPT, and Direct Preference Optimization (DPO). This report also evaluates the RL agents trained using generative trajectories. Evaluations were conducted using Thompson sampling in the WebShop simulator environment. The simulated online experiments demonstrate that agents trained on generated trajectories exhibited comparable task performance to those trained using human trajectories. This has demonstrated an example of an extremely low-cost data-efficient way of training reinforcement learning agents. Also, with limited training time (<2hours), without utilizing any images, a DPO agent achieved a 19% success rate after approximately 3000 steps or 30 minutes of training on T4 GPUs, compared to a PPO agent, which reached a 15% success rate.
Read more8/30/2024

0
Benchmarks for Reinforcement Learning with Biased Offline Data and Imperfect Simulators
Ori Linial, Guy Tennenholtz, Uri Shalit
In many reinforcement learning (RL) applications one cannot easily let the agent act in the world; this is true for autonomous vehicles, healthcare applications, and even some recommender systems, to name a few examples. Offline RL provides a way to train agents without real-world exploration, but is often faced with biases due to data distribution shifts, limited coverage, and incomplete representation of the environment. To address these issues, practical applications have tried to combine simulators with grounded offline data, using so-called hybrid methods. However, constructing a reliable simulator is in itself often challenging due to intricate system complexities as well as missing or incomplete information. In this work, we outline four principal challenges for combining offline data with imperfect simulators in RL: simulator modeling error, partial observability, state and action discrepancies, and hidden confounding. To help drive the RL community to pursue these problems, we construct ``Benchmarks for Mechanistic Offline Reinforcement Learning'' (B4MRL), which provide dataset-simulator benchmarks for the aforementioned challenges. Our results suggest the key necessity of such benchmarks for future research.
Read more7/2/2024
🏅
0
Reinforcement Learning in Agent-Based Market Simulation: Unveiling Realistic Stylized Facts and Behavior
Zhiyuan Yao, Zheng Li, Matthew Thomas, Ionut Florescu
Investors and regulators can greatly benefit from a realistic market simulator that enables them to anticipate the consequences of their decisions in real markets. However, traditional rule-based market simulators often fall short in accurately capturing the dynamic behavior of market participants, particularly in response to external market impact events or changes in the behavior of other participants. In this study, we explore an agent-based simulation framework employing reinforcement learning (RL) agents. We present the implementation details of these RL agents and demonstrate that the simulated market exhibits realistic stylized facts observed in real-world markets. Furthermore, we investigate the behavior of RL agents when confronted with external market impacts, such as a flash crash. Our findings shed light on the effectiveness and adaptability of RL-based agents within the simulation, offering insights into their response to significant market events.
Read more4/1/2024