CtRL-Sim: Reactive and Controllable Driving Agents with Offline Reinforcement Learning
2403.19918
0
0

Abstract
Evaluating autonomous vehicle stacks (AVs) in simulation typically involves replaying driving logs from real-world recorded traffic. However, agents replayed from offline data are not reactive and hard to intuitively control. Existing approaches address these challenges by proposing methods that rely on heuristics or generative models of real-world data but these approaches either lack realism or necessitate costly iterative sampling procedures to control the generated behaviours. In this work, we take an alternative approach and propose CtRL-Sim, a method that leverages return-conditioned offline reinforcement learning to efficiently generate reactive and controllable traffic agents. Specifically, we process real-world driving data through a physics-enhanced Nocturne simulator to generate a diverse offline reinforcement learning dataset, annotated with various reward terms. With this dataset, we train a return-conditioned multi-agent behaviour model that allows for fine-grained manipulation of agent behaviours by modifying the desired returns for the various reward components. This capability enables the generation of a wide range of driving behaviours beyond the scope of the initial dataset, including adversarial behaviours. We demonstrate that CtRL-Sim can generate diverse and realistic safety-critical scenarios while providing fine-grained control over agent behaviours.
Create account to get full access
Introduction
The paper discusses challenges in developing simulations for validating the safety of autonomous vehicles (AVs) in complex driving scenarios. Traditional approaches like log-replay testing, where the behavior of other agents is fixed based on pre-recorded data, do not allow for realistic interactions between the AV and other agents. Rule-based methods for reactive agents often lack realism due to rigid constraints that fail to capture the nuances of human driving behavior. Recently, generative models learned from real-world data have been proposed to enhance the realism of simulated agent behaviors. However, these learned methods either lack controllability or require costly iterative sampling procedures to control agent behaviors. Additionally, these methods often assume simplistic agent kinematics models, limiting their realism.
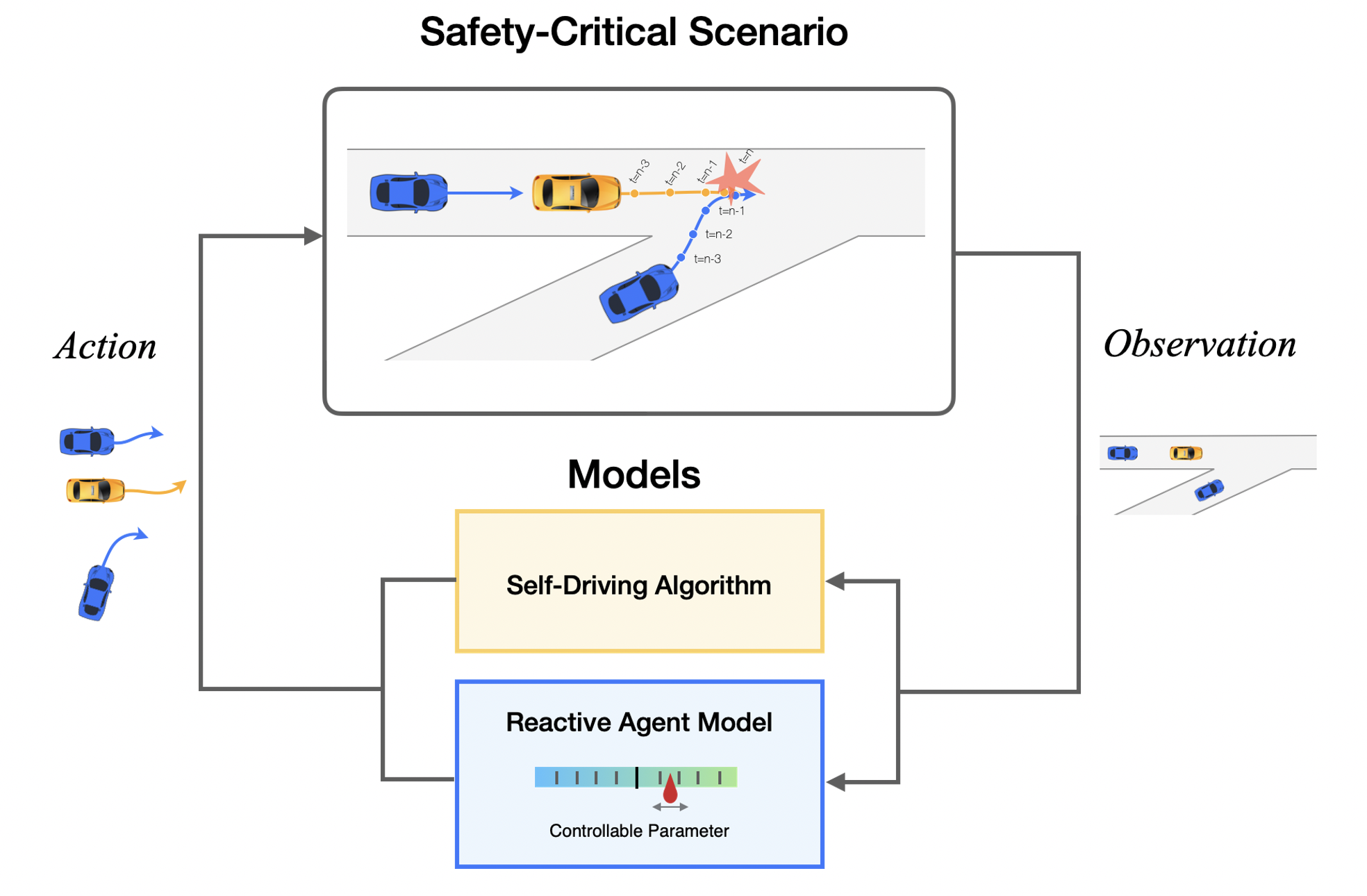
The paper proposes CtRL-Sim, a framework that utilizes return-conditioned offline reinforcement learning (RL) to enable reactive, closed-loop, controllable, and probabilistic behavior simulation within a physics-enhanced environment. The framework processes scenes from the Waymo Open Motion Dataset through the Nocturne simulator to create an offline RL dataset annotated with reward terms like "vehicle-vehicle collision" and "goal achieved."
CtRL-Sim employs a return-conditioned multi-agent decision Transformer architecture to imitate the driving behaviors in the curated dataset. It leverages exponential tilting of the predicted return distribution as a mechanism to control the simulated agent behaviors, enabling the generation of counterfactual scenes by tilting different reward axes.
The main contributions of the paper are:
- Proposing CtRL-Sim, a framework applying offline RL for controllable and reactive behavior simulation using exponential tilting of factorized reward-to-go.
- An autoregressive discrete, multi-agent Decision Transformer architecture tailored for controllable behavior simulation.
- Extending the Nocturne simulator with a Box2D physics engine for realistic vehicle dynamics and collision interactions.
The paper demonstrates the effectiveness of CtRL-Sim in producing controllable and realistic agent behaviors compared to prior methods. It also shows that fine-tuning the model in the Nocturne simulator with simulated CtRL-Sim scenarios enhances its controllability. CtRL-Sim has the potential to serve as a framework for enhancing the safety and robustness of AV planner policies through simulation-based training and evaluation.

Background
The paper discusses the common offline reinforcement learning setup where a dataset of trajectories is given, consisting of states, actions, and rewards. These trajectories are generated using a suboptimal behavior policy executed in a Markov Decision Process. The objective is to learn policies that perform better than the behavior policy.
The paper then introduces return-conditioned policies (RCPs), which learn the joint distribution of actions and returns, conditioning action sampling on the return distribution. Most RCP methods minimize an objective that decomposes the joint distribution into the action distribution conditioned on state and return, and the return distribution conditioned on state.
The Decision Transformer conditions the learned policy on the maximum observed return in the dataset during inference. Another approach uses the learned return distribution combined with exponential tilting to sample high-return actions while staying close to the empirical distribution.
The paper mentions that the proposed method CtRL-Sim adopts exponential tilting of the predicted return distribution for each agent to control agent behavior, and explicitly models future sequences of states.
CtRL-Sim
This section presents the proposed CtRL-Sim framework for simulating agent behaviors in driving scenarios. The key points are:
-
It formulates the problem as offline reinforcement learning to learn a policy conditioned on returns-to-go, which allows controlling the generated behaviors at test time by manipulating the sampled returns.
-
The learned policy models the joint distribution over future states, actions, and returns factorized into multiple components (e.g. reaching goal, avoiding collisions). This factorization enables controlling each component separately at test time.
-
It extends the approach to the multi-agent setting by modeling the joint distribution over the trajectories of all agents using an autoregressive transformer architecture.
-
The transformer encoder captures the initial scene context, while the decoder autoregressively generates the future trajectories, actions, and returns for all agents.
-
It integrates a physics engine into the simulator to enable realistic vehicle dynamics and collisions, allowing simulation of complex scenarios.
The framework aims to provide controllable simulation of diverse driving behaviors for evaluating autonomous vehicle planning systems in a closed-loop fashion without requiring costly real-world data collection.
Experiments
The provided text describes the experimental setup and results for evaluating the proposed CtRL-Sim model, which is a behavior simulation model for multi-agent autonomous driving scenarios.
For the experimental setup, an offline reinforcement learning dataset was curated from the Waymo Open Motion dataset by running the scenes through a physics simulator to obtain per-timestep actions and factored rewards. The model is evaluated on imitation performance, where it aims to replicate the driving behaviors from the Waymo dataset, and controllability, where it generates counterfactual scenes with specified behavior characteristics controlled by tilting coefficients.
The results show that CtRL-Sim achieves good performance on imitation metrics like displacement error, goal success rate, and distributional realism compared to baselines. It also demonstrates controllability by generating desired behaviors like collisions or off-road driving by adjusting the tilting coefficients for different reward components. Finetuning CtRL-Sim on simulated long-tail scenarios further improves its ability to generate safety-critical behaviors like collisions and off-road driving.
Qualitative examples illustrate how positive and negative tilting coefficients change the behavior of the CtRL-Sim-controlled agent, enabling the generation of realistic vehicle-vehicle and vehicle-edge collision scenarios. The authors compare CtRL-Sim's ability to generate collision scenarios with a Decision Transformer baseline, showing CtRL-Sim's effectiveness in this task.
Related Work
The text discusses agent behavior simulation, which involves modeling the behavior of other agents, such as vehicles and pedestrians, to enable diverse and realistic interactions with autonomous vehicles (AVs). It categorizes agent behavior simulation methods into rule-based and data-driven methods.
Rule-based methods rely on human-specified rules to produce plausible agent behaviors, such as adhering to the center of the lane and maintaining a safe following distance. However, these methods often yield unrealistic behaviors because they rigidly adhere to rules and fail to capture the full spectrum of human driving behaviors.
To address these limitations, prior work has proposed learning generative models that aim to replicate agent behaviors found in real-world driving trajectory datasets. Some approaches have used adversarial imitation learning or reinforcement learning to improve the realism of learned behaviors and traffic rule compliance.
More recent work has proposed controllable behavior simulation models by learning conditional models that enable conditioning on high-level latent variables, route information, or differentiable constraints. However, these methods either lack interpretable control over the generated behaviors or require costly test-time optimization procedures.
CtRL-Sim takes an alternative approach by learning a conditional multi-agent behavior model that conditions on interpretable factorized returns. By exponentially tilting the predicted return distribution at test time, CtRL-Sim enables efficient, interpretable, and fine-grained control over agent behaviors while being grounded in real-world data.
Conclusions
The paper presents CtRL-Sim, a novel framework that applies offline reinforcement learning (RL) to simulate controllable and reactive agent behaviors. The proposed multi-agent behavior Transformer architecture allows CtRL-Sim to use exponential tilting during testing to simulate a wide range of interesting agent behaviors.
Experiments demonstrate CtRL-Sim's effectiveness in producing controllable and reactive behaviors while maintaining competitive performance on imitation tasks compared to baselines. The authors suggest exploring CtRL-Sim further to handle additional reward function components, such as driving comfort and traffic signal compliance, and investigating its application in domains beyond autonomous driving.
However, the learned policies produced by CtRL-Sim in its current form can be prohibitively slow for online RL research as they require a forward pass through a Transformer decoder at every simulation timestep. The authors leave the exploration of employing more lightweight policies through distillation methods for future work.
Acknowledgements
The provided text states that the LP and CP projects are financially supported by two organizations in Canada. Specifically, the Canada CIFAR AI Chair program provides funding, as does the Discovery Grants program under NSERC (Natural Sciences and Engineering Research Council of Canada). There are no additional details provided about the nature or focus of these projects.
Appendix A Offline RL Approaches
The paper discusses various approaches for learning policies in offline reinforcement learning and how these methods can select actions that maximize returns during the test or deployment phase. Table 3 likely outlines and compares these different offline RL techniques and their action sampling strategies for achieving optimal performance.
Appendix B Action Sampling Algorithm
Here is a summary of the provided section in clear, easy-to-understand terms:
The paper presents an algorithm for sampling actions to generate controllable behaviors in AI agents. This action sampling procedure utilizes a technique called factorized exponential tilting. The algorithm adjusts the probabilities of taking certain actions based on desired behavioral traits or goals. It factorizes the adjustments into separate components for different behavioral attributes. This allows controlling multiple traits simultaneously in a principled manner. The probabilities are exponentially tilted towards the desired behaviors in a computationally efficient way. Precise implementation details are provided in the algorithm description.
Appendix C Nocturne Simulator
The passage describes the representation of a scene in Nocturne, a simulator used for developing reinforcement learning (RL) driving policies. A scene comprises dynamic objects like vehicles, pedestrians, and cyclists, along with map context such as lane boundaries, lane markings, traffic signs, and crosswalks. Each dynamic object has a prescribed goal state, defined as the final waypoint in the ground-truth trajectory from the Waymo Open Motion Dataset. If there are missing timesteps, the goal is redefined as the waypoint preceding the first missing timestep. By default, dynamic objects track their 9-second trajectory from the dataset at 10 Hz. The Nocturne Simulator is designed for RL driving policy development, where the first 10 simulation steps (1 second) of context are provided, and the RL agent must reach the prescribed goal within the next 80 simulation steps (8 seconds).
Appendix D Offline Reinforcement Learning Dataset
The provided text describes the approach for collecting offline reinforcement learning trajectory data and defining the reward function used in the research. Here are the key points:
For each agent, the acceleration and steering values are computed using an inverse bicycle model based on the agent's current state and the ground-truth next state from the driving log. These values are clipped to reasonable ranges and then executed using a proposed forward physics dynamics model to obtain the agent's updated state. This process is repeated until the full rollout is completed, aiming to reconstruct the ground-truth driving trajectories.
The reward function consists of three components: a goal position reward, a vehicle-vehicle collision reward, and a vehicle-road-edge collision reward. The goal position reward is a binary indicator of whether the goal is achieved or not. The vehicle-vehicle collision reward penalizes collisions with other vehicles and rewards maintaining a safe distance from the nearest vehicle. The vehicle-road-edge collision reward similarly penalizes collisions with road edges and rewards maintaining a safe distance from the nearest road edge.
Appendix E Evaluation Metrics
The provided text describes various metrics used to evaluate the performance of agents in simulated environments. The key metrics discussed are:
Goal success rate: The proportion of agents that get within 1 meter of the ground-truth goal position during trajectory rollout.
Displacement errors: The final and average displacement errors of agents across test scenes.
Collision and offroad rates: The proportion of agents that collide with other agents or go off the road, respectively, averaged across test scenes.
Jensen Shannon Distance (JSD): A measure of the similarity between feature distributions (linear speed, angular speed, acceleration, nearest distance) of real and simulated rollouts. The square root of the JSD is computed to avoid values being too close to 0.
The text provides specific details on how the JSD is calculated, including the formula used and the number of bins for the histograms of different features. The JSD quantifies the difference between the feature distributions of real and simulated rollouts.
Appendix F Individual JSD Results
The paper discusses the Jensen-Shannon Divergence (JSD) results for different features, as shown in Table 4 and related to Table 1. The JSD is a measure used to quantify the similarity between two probability distributions. By analyzing the per-feature JSD values, the researchers aimed to understand which features contributed the most to the divergence between the compared distributions. However, the specific details about the features or the analysis methodology are not provided in the given text.
Appendix G CtRL-Sim Training Details
The CtRL-Sim behavior simulation model trains on randomly subsampled sequences with a length determined by specific parameters (H=32, N=24). The model encodes agents and map context in a global frame, centering and rotating the scene around a random agent during training. It selects the 200 closest lane segments within 100 meters and up to 24 closest agents within 60 meters as map and social context, respectively. For each lane segment, 100 points are subsampled.
The model architecture uses a hidden dimension size of 256, with 2 Transformer encoder blocks and 4 Transformer decoder blocks. A specific loss function weight (α=1/100) is employed. The model supervises only the trajectories of moving agents, with a 10% goal dropout to prevent over-reliance on goal information.
The state, return, and action embeddings for missing timesteps are set to 0. The model trains for 200k steps using the AdamW optimizer, a linear decaying learning rate from 5e-4, and a batch size of 64. During inference, actions are sampled with a temperature of 1.5.
The CtRL-Sim architecture comprises 8.3 million parameters, trained in 20 hours using 4 NVIDIA A100 GPUs.
Appendix H CtRL-Sim Inference Details
The paper discusses how CtRL-Sim handles scenes with multiple agents during inference. When the number of agents exceeds the training limit of 24, the system iteratively selects subsets of 24 agents at each timestep for processing. It randomly selects a CtRL-Sim-controlled agent, normalizes the scene to that agent, and chooses the 23 closest agents as context. This process continues until all agents have been included in a 24-agent subset. If an agent belongs to multiple subsets, the model's first prediction is used.
During inference, the context length is set to the training context length of 32 timesteps. At each timestep, the 32 most recent timesteps are selected as context, and the scene is centered and rotated on the agent at the oldest timestep in the context.
For the first 10 timesteps (1 second) of the simulated rollout, the states and actions are fixed to the ground-truth data from the offline RL dataset. The return-to-go is predicted at every timestep of the simulated rollout.
Appendix I CtRL-Sim Finetuning
The paper describes a method to finetune the CtRL-Sim model to generate safety-critical scenarios involving vehicle-vehicle collisions or off-road infractions. A simulated dataset is created by running the negatively tilted base CtRL-Sim model and saving scenarios that result in collisions or road-edge collisions. Negative tilt values for vehicle-vehicle collisions, vehicle-road-edge collisions, and goal parameters are uniformly sampled from -25 to 0. This grants flexibility in generating traffic violations as agents are not trying to reach prescribed goals.
5000 scenarios of each violation type are collected from the training set to form the simulated safety-critical dataset. A continual pre-training strategy is adopted, randomly sampling 90% real training scenarios and 10% simulated scenarios in each epoch during finetuning. The learning rate is warmed up and then decayed linearly over 20 epochs.
The finetuned CtRL-Sim model is expected to better generate long-tail, safety-critical scenarios due to increased exposure during finetuning. No justification for specific parameter values is provided.
Appendix J Additional Qualitative Results

The provided text discusses qualitative examples showcasing the effects of positive exponential tilting on the three reward components in the CtRL-Sim system. Figure 7 demonstrates that without tilting, collisions occur between vehicles or with edges. With positive vehicle-vehicle tilting, the controlled agent moves further to the side, avoiding collisions with other vehicles. Positive vehicle-edge tilting leads the agent to maintain a safer distance from curbs. Positive goal tilting enables the agent to reach the goal faster while nearly avoiding collisions with turning vehicles. Figure 8 shows two examples of adversarial collision scenarios generated with negative vehicle-vehicle tilting. The paper refers readers to supplementary materials for more example videos.

This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SAFE-SIM: Safety-Critical Closed-Loop Traffic Simulation with Controllable Adversaries
Wei-Jer Chang, Francesco Pittaluga, Masayoshi Tomizuka, Wei Zhan, Manmohan Chandraker
0
0
Evaluating the performance of autonomous vehicle planning algorithms necessitates simulating long-tail safety-critical traffic scenarios. However, traditional methods for generating such scenarios often fall short in terms of controllability and realism and neglect the dynamics of agent interactions. To mitigate these limitations, we introduce SAFE-SIM, a novel diffusion-based controllable closed-loop safety-critical simulation framework. Our approach yields two distinct advantages: 1) the generation of realistic long-tail safety-critical scenarios that closely emulate real-world conditions, and 2) enhanced controllability, enabling more comprehensive and interactive evaluations. We develop a novel approach to simulate safety-critical scenarios through an adversarial term in the denoising process, which allows an adversarial agent to challenge a planner with plausible maneuvers while all agents in the scene exhibit reactive and realistic behaviors. Furthermore, we propose novel guidance objectives and a partial diffusion process that enables a user to control key aspects of the generated scenarios, such as the collision type and aggressiveness of the adversarial driver, while maintaining the realism of the behavior. We validate our framework empirically using the NuScenes dataset, demonstrating improvements in both realism and controllability. These findings affirm that diffusion models provide a robust and versatile foundation for safety-critical, interactive traffic simulation, extending their utility across the broader landscape of autonomous driving. For supplementary videos, visit our project at https://safe-sim.github.io/.
6/18/2024
🏅
Simulation-based reinforcement learning for real-world autonomous driving
B{l}a.zej Osi'nski, Adam Jakubowski, Piotr Mi{l}o's, Pawe{l} Zik{e}cina, Christopher Galias, Silviu Homoceanu, Henryk Michalewski
0
0
We use reinforcement learning in simulation to obtain a driving system controlling a full-size real-world vehicle. The driving policy takes RGB images from a single camera and their semantic segmentation as input. We use mostly synthetic data, with labelled real-world data appearing only in the training of the segmentation network. Using reinforcement learning in simulation and synthetic data is motivated by lowering costs and engineering effort. In real-world experiments we confirm that we achieved successful sim-to-real policy transfer. Based on the extensive evaluation, we analyze how design decisions about perception, control, and training impact the real-world performance.
4/4/2024

CIMRL: Combining IMitiation and Reinforcement Learning for Safe Autonomous Driving
Jonathan Booher, Khashayar Rohanimanesh, Junhong Xu, Vladislav Isenbaev, Ashwin Balakrishna, Ishan Gupta, Wei Liu, Aleksandr Petiushko
0
0
Modern approaches to autonomous driving rely heavily on learned components trained with large amounts of human driving data via imitation learning. However, these methods require large amounts of expensive data collection and even then face challenges with safely handling long-tail scenarios and compounding errors over time. At the same time, pure Reinforcement Learning (RL) methods can fail to learn performant policies in sparse, constrained, and challenging-to-define reward settings like driving. Both of these challenges make deploying purely cloned policies in safety critical applications like autonomous vehicles challenging. In this paper we propose Combining IMitation and Reinforcement Learning (CIMRL) approach - a framework that enables training driving policies in simulation through leveraging imitative motion priors and safety constraints. CIMRL does not require extensive reward specification and improves on the closed loop behavior of pure cloning methods. By combining RL and imitation, we demonstrate that our method achieves state-of-the-art results in closed loop simulation driving benchmarks.
6/27/2024
🤿
A Platform-Agnostic Deep Reinforcement Learning Framework for Effective Sim2Real Transfer in Autonomous Driving
Dianzhao Li, Ostap Okhrin
0
0
Deep Reinforcement Learning (DRL) has shown remarkable success in solving complex tasks across various research fields. However, transferring DRL agents to the real world is still challenging due to the significant discrepancies between simulation and reality. To address this issue, we propose a robust DRL framework that leverages platform-dependent perception modules to extract task-relevant information and train a lane-following and overtaking agent in simulation. This framework facilitates the seamless transfer of the DRL agent to new simulated environments and the real world with minimal effort. We evaluate the performance of the agent in various driving scenarios in both simulation and the real world, and compare it to human players and the PID baseline in simulation. Our proposed framework significantly reduces the gaps between different platforms and the Sim2Real gap, enabling the trained agent to achieve similar performance in both simulation and the real world, driving the vehicle effectively.
5/1/2024