Reinforcement Learning Approach to Optimizing Profilometric Sensor Trajectories for Surface Inspection

0

Sign in to get full access
Overview
- A reinforcement learning approach to optimizing the trajectories of profilometric sensors for surface inspection
- Designed to improve the efficiency and accuracy of industrial surface inspection tasks
- Focuses on automating the process of determining optimal sensor paths to cover a surface
Plain English Explanation
The research paper proposes a reinforcement learning approach to optimizing the trajectories of profilometric sensors used for surface inspection tasks in industrial settings. The goal is to automate the process of determining the optimal paths for these sensors to efficiently cover a given surface and gather accurate measurements.
The key idea is to use reinforcement learning algorithms to learn the optimal sensor trajectories based on factors like surface geometry, sensor limitations, and the desired coverage and resolution. This allows the system to adaptively plan paths that maximize the information gathered while minimizing factors like travel time and sensor wear.
By automating this traditionally manual process, the approach aims to improve the efficiency, reliability, and accuracy of industrial surface inspection tasks, which are critical for quality control and defect detection in manufacturing.
Technical Explanation
The paper presents a reinforcement learning-based framework for optimizing profilometric sensor trajectories during surface inspection tasks. The system uses a Markov Decision Process (MDP) formulation, where the agent (the sensor system) interacts with the environment (the surface being inspected) and learns the optimal trajectory policies through trial-and-error.
The state of the MDP encodes the sensor's current position and orientation, as well as information about the surface geometry and the desired coverage. The agent can take actions to move the sensor in various directions, with the goal of maximizing a reward function that captures the trade-off between coverage, accuracy, and efficiency.
The authors experiment with different reinforcement learning algorithms, including proximal policy optimization (PPO) and deep Q-learning, to learn the optimal policies. They also incorporate safety constraints to ensure the sensor trajectories do not collide with obstacles or exceed the sensor's physical limitations.
Experiments on simulated and real-world surface inspection tasks demonstrate the effectiveness of the proposed approach in generating efficient and accurate sensor trajectories, outperforming traditional manually-designed paths.
Critical Analysis
The paper presents a promising approach to automating the optimization of sensor trajectories for surface inspection tasks, which can have significant practical applications in industries like manufacturing and quality control.
One potential limitation is the reliance on accurate surface geometry information, which may not always be available or easy to obtain. The authors acknowledge this and suggest that the framework could be extended to handle uncertain or partially known surface models.
Additionally, the paper focuses on a single profilometric sensor, but in many real-world scenarios, multiple sensors or modalities may be used for surface inspection. Extending the approach to handle multi-sensor coordination and fusion could be an interesting direction for future research.
Another area for further exploration is the incorporation of more sophisticated reward functions or constraints, such as those related to sensor wear, energy consumption, or the specific defect detection requirements of the application.
Conclusion
This research paper presents a reinforcement learning-based approach for optimizing profilometric sensor trajectories in surface inspection tasks. By automating the process of determining optimal sensor paths, the proposed framework has the potential to improve the efficiency, reliability, and accuracy of industrial surface inspection, which is crucial for quality control and defect detection.
The technical approach, experimental results, and discussion of potential limitations and future research directions provide a solid foundation for further advancements in this area, with broader implications for the use of reinforcement learning in robotics, automation, and sensor-based inspection and monitoring applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reinforcement Learning Approach to Optimizing Profilometric Sensor Trajectories for Surface Inspection
Sara Roos-Hoefgeest, Mario Roos-Hoefgeest, Ignacio Alvarez, Rafael C. Gonz'alez
High-precision surface defect detection in manufacturing is essential for ensuring quality control. Laser triangulation profilometric sensors are key to this process, providing detailed and accurate surface measurements over a line. To achieve a complete and precise surface scan, accurate relative motion between the sensor and the workpiece is required. It is crucial to control the sensor pose to maintain optimal distance and relative orientation to the surface. It is also important to ensure uniform profile distribution throughout the scanning process. This paper presents a novel Reinforcement Learning (RL) based approach to optimize robot inspection trajectories for profilometric sensors. Building upon the Boustrophedon scanning method, our technique dynamically adjusts the sensor position and tilt to maintain optimal orientation and distance from the surface, while also ensuring a consistent profile distance for uniform and high-quality scanning. Utilizing a simulated environment based on the CAD model of the part, we replicate real-world scanning conditions, including sensor noise and surface irregularities. This simulation-based approach enables offline trajectory planning based on CAD models. Key contributions include the modeling of the state space, action space, and reward function, specifically designed for inspection applications using profilometric sensors. We use Proximal Policy Optimization (PPO) algorithm to efficiently train the RL agent, demonstrating its capability to optimize inspection trajectories with profilometric sensors. To validate our approach, we conducted several experiments where a model trained on a specific training piece was tested on various parts in simulation. Also, we conducted a real-world experiment by executing the optimized trajectory, generated offline from a CAD model, to inspect a part using a UR3e robotic arm model.
Read more9/6/2024
🛠️
0
Trajectory Optimization for Adaptive Informative Path Planning with Multimodal Sensing
Joshua Ott, Edward Balaban, Mykel Kochenderfer
We consider the problem of an autonomous agent equipped with multiple sensors, each with different sensing precision and energy costs. The agent's goal is to explore the environment and gather information subject to its resource constraints in unknown, partially observable environments. The challenge lies in reasoning about the effects of sensing and movement while respecting the agent's resource and dynamic constraints. We formulate the problem as a trajectory optimization problem and solve it using a projection-based trajectory optimization approach where the objective is to reduce the variance of the Gaussian process world belief. Our approach outperforms previous approaches in long horizon trajectories by achieving an overall variance reduction of up to 85% and reducing the root-mean square error in the environment belief by 50%. This approach was developed in support of rover path planning for the NASA VIPER Mission.
Read more4/30/2024

0
Reinforcement Learning Meets Visual Odometry
Nico Messikommer, Giovanni Cioffi, Mathias Gehrig, Davide Scaramuzza
Visual Odometry (VO) is essential to downstream mobile robotics and augmented/virtual reality tasks. Despite recent advances, existing VO methods still rely on heuristic design choices that require several weeks of hyperparameter tuning by human experts, hindering generalizability and robustness. We address these challenges by reframing VO as a sequential decision-making task and applying Reinforcement Learning (RL) to adapt the VO process dynamically. Our approach introduces a neural network, operating as an agent within the VO pipeline, to make decisions such as keyframe and grid-size selection based on real-time conditions. Our method minimizes reliance on heuristic choices using a reward function based on pose error, runtime, and other metrics to guide the system. Our RL framework treats the VO system and the image sequence as an environment, with the agent receiving observations from keypoints, map statistics, and prior poses. Experimental results using classical VO methods and public benchmarks demonstrate improvements in accuracy and robustness, validating the generalizability of our RL-enhanced VO approach to different scenarios. We believe this paradigm shift advances VO technology by eliminating the need for time-intensive parameter tuning of heuristics.
Read more7/23/2024
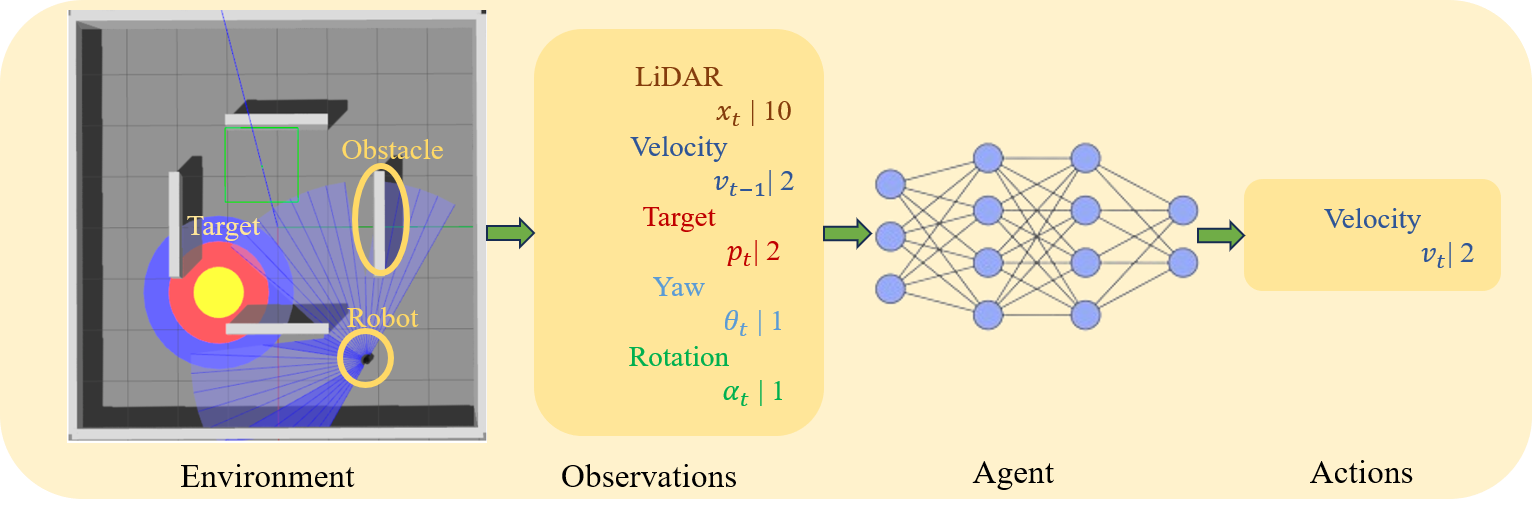
0
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini, Mohammad Ali Nekoui
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Read more8/9/2024