Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
2405.16266
0
0
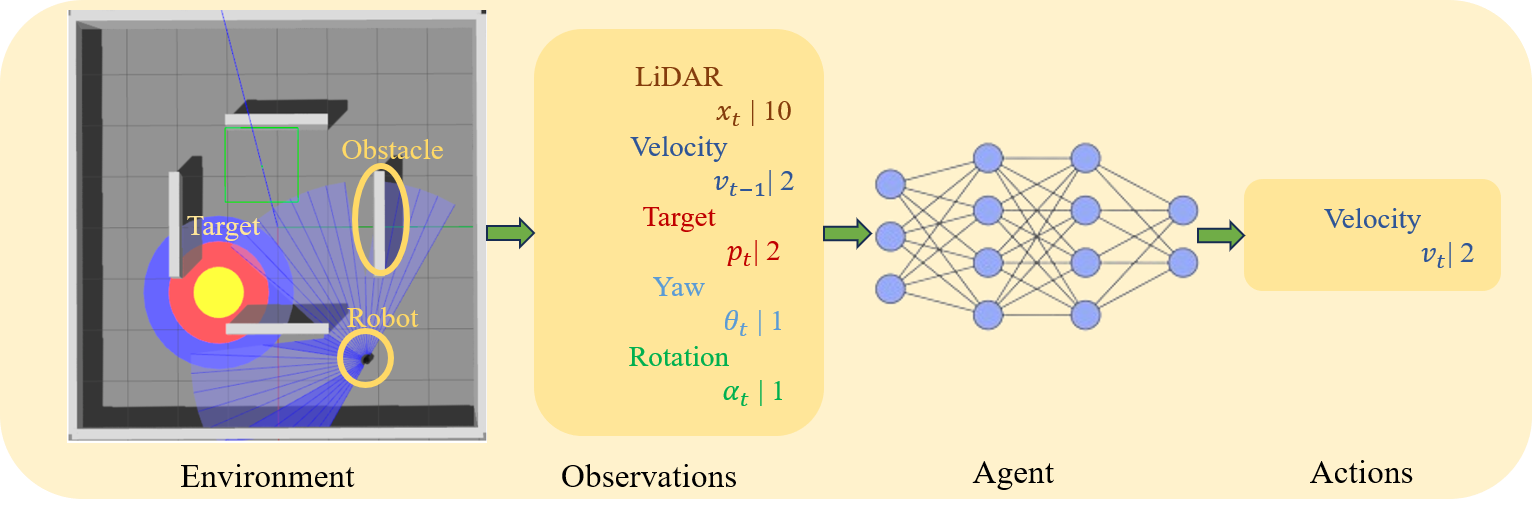
Abstract
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Create account to get full access
Overview
- This paper presents an enhanced version of the Proximal Policy Optimization (PPO) algorithm for deep reinforcement learning to enable safe mobile robot navigation.
- The proposed approach aims to address the challenges of obstacle avoidance and safe path planning in dynamic environments.
- The authors integrate a memory module and a specialized reward function into the PPO framework to improve the robot's decision-making and navigation capabilities.
Plain English Explanation
The paper describes a new way to train robots to navigate safely through their surroundings using deep reinforcement learning. Robots often struggle with avoiding obstacles and finding the best path to their destination, especially in crowded or changing environments. The researchers developed an improved version of a popular deep learning algorithm called Proximal Policy Optimization (PPO) to help robots learn how to navigate more effectively.
The key innovations in this work are the addition of a memory module and a specialized reward function. The memory module allows the robot to better understand its current situation and remember past experiences to inform its decisions. The reward function encourages the robot to not only reach its goal, but to do so in a safe and efficient manner, avoiding collisions and unnecessary movements.
By combining these enhancements with the PPO algorithm, the researchers were able to train robots that could navigate through complex environments while maintaining safety. This could have important real-world applications, such as in autonomous vehicles, search and rescue robots, or industrial automation.
Technical Explanation
The authors propose an enhanced version of the Proximal Policy Optimization (PPO) algorithm, a popular deep reinforcement learning technique, for safe mobile robot navigation. They integrate two key components into the PPO framework:
-
Memory Module: The researchers incorporate a memory module that allows the robot to maintain an internal representation of its surroundings and past experiences. This memory helps the robot make more informed decisions about its actions, improving its ability to navigate safely.
-
Specialized Reward Function: The authors design a reward function that incentivizes the robot to not only reach its goal, but to do so in a safe and efficient manner. This reward function encourages the robot to avoid collisions, minimize unnecessary movements, and maintain a smooth trajectory.
By combining these enhancements with the PPO algorithm, the researchers demonstrate improved performance in terms of navigation accuracy, collision avoidance, and overall safety. The authors evaluate their approach in simulation and compare it to other deep reinforcement learning methods for mobile robot navigation, such as MESA-DRL, Adaptive Speed Planning, and Collision Avoidance for Quadrotor Swarms.
Critical Analysis
The paper presents a promising approach to improving the safety and reliability of mobile robot navigation using deep reinforcement learning. The incorporation of a memory module and a specialized reward function are meaningful contributions that address key challenges in this domain.
However, the authors acknowledge several limitations and areas for future work. For example, the simulation-based evaluation may not fully capture the complexities of real-world environments, and the performance of the algorithm in physical robot experiments is not reported. Additionally, the authors suggest that further research is needed to address the challenge of integrating deep reinforcement learning with robust low-level control for safer and more reliable robot navigation.
It would also be important to explore the scalability of the proposed approach, as well as its performance in more diverse and dynamic environments. Broader testing and validation would help strengthen the claims and establish the broader applicability of the enhanced PPO algorithm for safe mobile robot navigation.
Conclusion
The paper presents an enhanced version of the Proximal Policy Optimization (PPO) algorithm for deep reinforcement learning, which aims to enable safer and more reliable mobile robot navigation. By incorporating a memory module and a specialized reward function, the researchers demonstrate improved performance in terms of collision avoidance, navigation accuracy, and overall safety.
This work represents an important step forward in the field of deep reinforcement learning for mobile robotics, with potential applications in autonomous vehicles, search and rescue operations, and industrial automation. The critical analysis highlights the need for further research to address the limitations and expand the capabilities of the proposed approach, but the overall contribution is a valuable addition to the growing body of work on safe and efficient robot navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Deep Reinforcement Learning for Mobile Robot Path Planning
Hao Liu, Yi Shen, Shuangjiang Yu, Zijun Gao, Tong Wu
0
0
Path planning is an important problem with the the applications in many aspects, such as video games, robotics etc. This paper proposes a novel method to address the problem of Deep Reinforcement Learning (DRL) based path planning for a mobile robot. We design DRL-based algorithms, including reward functions, and parameter optimization, to avoid time-consuming work in a 2D environment. We also designed an Two-way search hybrid A* algorithm to improve the quality of local path planning. We transferred the designed algorithm to a simple embedded environment to test the computational load of the algorithm when running on a mobile robot. Experiments show that when deployed on a robot platform, the DRL-based algorithm in this article can achieve better planning results and consume less computing resources.
4/11/2024
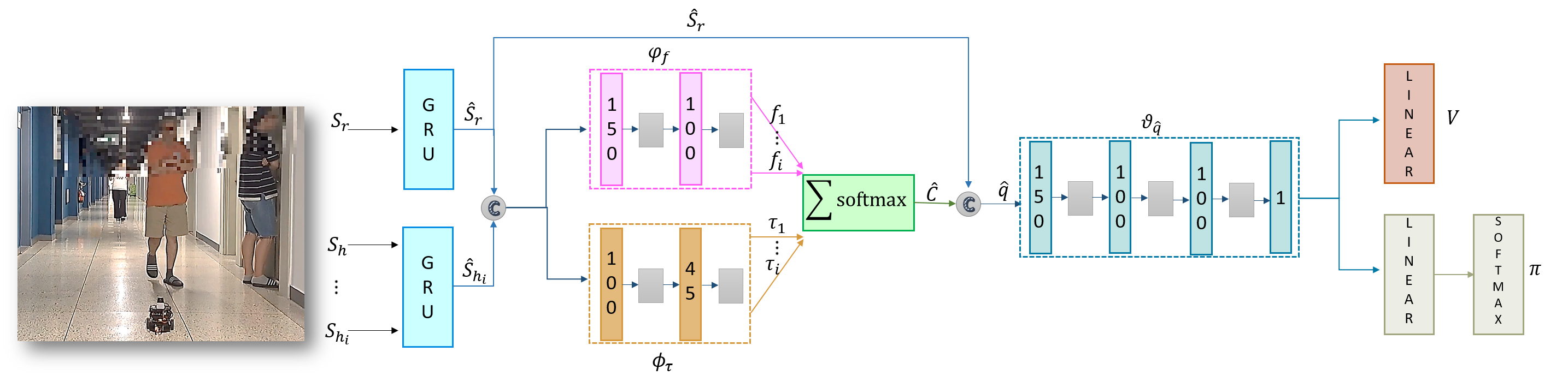
MeSA-DRL: Memory-Enhanced Deep Reinforcement Learning for Advanced Socially Aware Robot Navigation in Crowded Environments
Mannan Saeed Muhammad, Estrella Montero
0
0
Autonomous navigation capabilities play a critical role in service robots operating in environments where human interactions are pivotal, due to the dynamic and unpredictable nature of these environments. However, the variability in human behavior presents a substantial challenge for robots in predicting and anticipating movements, particularly in crowded scenarios. To address this issue, a memory-enabled deep reinforcement learning framework is proposed for autonomous robot navigation in diverse pedestrian scenarios. The proposed framework leverages long-term memory to retain essential information about the surroundings and model sequential dependencies effectively. The importance of human-robot interactions is also encoded to assign higher attention to these interactions. A global planning mechanism is incorporated into the memory-enabled architecture. Additionally, a multi-term reward system is designed to prioritize and encourage long-sighted robot behaviors by incorporating dynamic warning zones. Simultaneously, it promotes smooth trajectories and minimizes the time taken to reach the robot's desired goal. Extensive simulation experiments show that the suggested approach outperforms representative state-of-the-art methods, showcasing its ability to a navigation efficiency and safety in real-world scenarios.
4/9/2024
🤿
Adaptive speed planning for Unmanned Vehicle Based on Deep Reinforcement Learning
Hao Liu, Yi Shen, Wenjing Zhou, Yuelin Zou, Chang Zhou, Shuyao He
0
0
In order to solve the problem of frequent deceleration of unmanned vehicles when approaching obstacles, this article uses a Deep Q-Network (DQN) and its extension, the Double Deep Q-Network (DDQN), to develop a local navigation system that adapts to obstacles while maintaining optimal speed planning. By integrating improved reward functions and obstacle angle determination methods, the system demonstrates significant enhancements in maneuvering capabilities without frequent decelerations. Experiments conducted in simulated environments with varying obstacle densities confirm the effectiveness of the proposed method in achieving more stable and efficient path planning.
4/29/2024
🤿
Quantum Deep Reinforcement Learning for Robot Navigation Tasks
Hans Hohenfeld, Dirk Heimann, Felix Wiebe, Frank Kirchner
0
0
We utilize hybrid quantum deep reinforcement learning to learn navigation tasks for a simple, wheeled robot in simulated environments of increasing complexity. For this, we train parameterized quantum circuits (PQCs) with two different encoding strategies in a hybrid quantum-classical setup as well as a classical neural network baseline with the double deep Q network (DDQN) reinforcement learning algorithm. Quantum deep reinforcement learning (QDRL) has previously been studied in several relatively simple benchmark environments, mainly from the OpenAI gym suite. However, scaling behavior and applicability of QDRL to more demanding tasks closer to real-world problems e. g., from the robotics domain, have not been studied previously. Here, we show that quantum circuits in hybrid quantum-classic reinforcement learning setups are capable of learning optimal policies in multiple robotic navigation scenarios with notably fewer trainable parameters compared to a classical baseline. Across a large number of experimental configurations, we find that the employed quantum circuits outperform the classical neural network baselines when equating for the number of trainable parameters. Yet, the classical neural network consistently showed better results concerning training times and stability, with at least one order of magnitude of trainable parameters more than the best-performing quantum circuits. However, validating the robustness of the learning methods in a large and dynamic environment, we find that the classical baseline produces more stable and better performing policies overall.
6/26/2024