Reinforcement Learning for Sociohydrology
2405.20772
0
0
🏅
Abstract
In this study, we discuss how reinforcement learning (RL) provides an effective and efficient framework for solving sociohydrology problems. The efficacy of RL for these types of problems is evident because of its ability to update policies in an iterative manner - something that is also foundational to sociohydrology, where we are interested in representing the co-evolution of human-water interactions. We present a simple case study to demonstrate the implementation of RL in a problem of runoff reduction through management decisions related to changes in land-use land-cover (LULC). We then discuss the benefits of RL for these types of problems and share our perspectives on the future research directions in this area.
Create account to get full access
Overview
- This study explores how reinforcement learning (RL) can provide an effective and efficient framework for solving sociohydrology problems.
- The authors present a case study demonstrating the implementation of RL to address a problem of runoff reduction through land-use land-cover (LULC) management decisions.
- The paper discusses the benefits of RL for these types of problems and suggests future research directions in this area.
Plain English Explanation
Reinforcement learning (RL) is a type of machine learning that helps computers learn by interacting with their environment and receiving feedback. The authors of this study believe RL can be particularly useful for solving problems related to the interactions between humans and water resources, known as sociohydrology.
The key idea is that RL allows policies, or decision-making strategies, to be updated iteratively. This aligns well with the way sociohydrology problems evolve over time, as human-water interactions continually change. The authors demonstrate this by using RL to tackle a problem of reducing runoff through changes in land use and land cover (LULC).
By using RL, the system can learn from its experiences and gradually improve its decisions about how to manage the land in a way that reduces runoff. This could be helpful for promoting sustainable human-water interactions and reducing risks associated with water management.
Technical Explanation
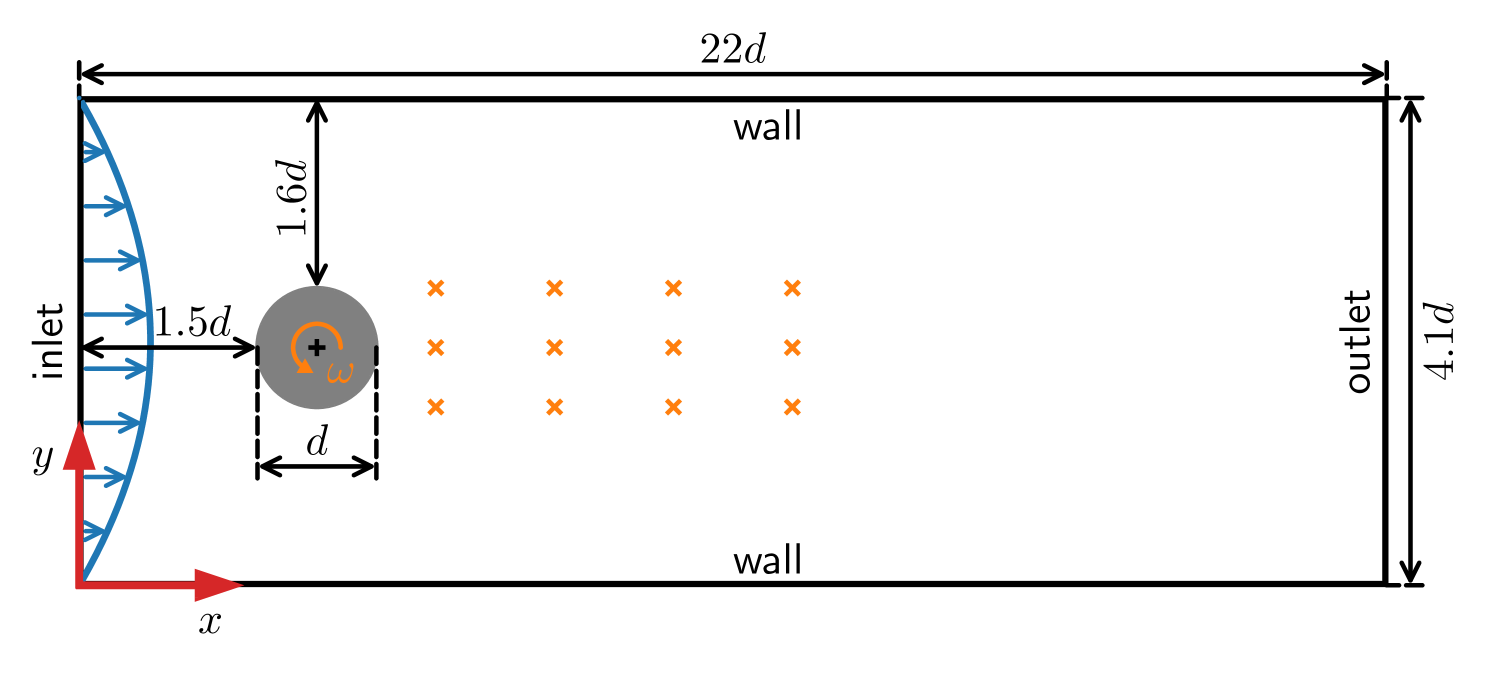
The authors present a case study demonstrating the use of RL to address a problem of runoff reduction through LULC management decisions. They describe an RL agent that interacts with a simulated environment, receiving rewards for actions that reduce runoff. Over time, the agent learns an optimal policy for managing the LULC to minimize runoff.
The authors highlight several benefits of using RL for these types of sociohydrology problems. First, RL's iterative policy updates align well with the co-evolutionary nature of human-water interactions. Second, RL can capture complex, nonlinear relationships between LULC decisions and hydrological outcomes. Third, RL can handle uncertainty and adapt to changes in the environment.
The authors also discuss potential future research directions, such as integrating RL with human feedback to better reflect stakeholder preferences, and applying RL to household-level water management to promote sustainable water use.
Critical Analysis
The authors provide a compelling case for the use of RL in sociohydrology problems, but the study is limited to a single case study. Additional research is needed to understand the broader applicability and limitations of this approach.
One potential concern is the reliance on a simulated environment. While this allows for controlled experiments, the real-world implementation may face challenges in accurately modeling the complex interactions between human behavior, land use, and hydrological processes.
Furthermore, the authors do not address the interpretability of the RL policies. In many sociohydrology problems, stakeholder engagement and transparency are crucial. It may be necessary to develop techniques to make the RL decision-making process more understandable to human decision-makers.
Conclusion
This study demonstrates the potential of reinforcement learning to provide an effective and efficient framework for solving sociohydrology problems. By leveraging RL's ability to iteratively update policies, the authors show how it can be used to address complex problems involving the co-evolution of human-water interactions, such as runoff reduction through LULC management.
While the case study provides a promising proof of concept, further research is needed to explore the broader applicability of this approach and address potential challenges, such as the integration of human feedback and the interpretability of RL policies. As the field of sociohydrology continues to evolve, the integration of RL may offer valuable insights and solutions for sustainable water management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
0
0
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
4/11/2024
🤿
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem
Raphael Koster, Miruna P^islar, Andrea Tacchetti, Jan Balaguer, Leqi Liu, Romuald Elie, Oliver P. Hauser, Karl Tuyls, Matt Botvinick, Christopher Summerfield
0
0
A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.
4/24/2024
🏅
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, Eyke Hullermeier
0
0
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of large language models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in directing the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between RL agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.
5/1/2024
🏅
Reducing Risk for Assistive Reinforcement Learning Policies with Diffusion Models
Andrii Tytarenko
0
0
Care-giving and assistive robotics, driven by advancements in AI, offer promising solutions to meet the growing demand for care, particularly in the context of increasing numbers of individuals requiring assistance. This creates a pressing need for efficient and safe assistive devices, particularly in light of heightened demand due to war-related injuries. While cost has been a barrier to accessibility, technological progress is able to democratize these solutions. Safety remains a paramount concern, especially given the intricate interactions between assistive robots and humans. This study explores the application of reinforcement learning (RL) and imitation learning, in improving policy design for assistive robots. The proposed approach makes the risky policies safer without additional environmental interactions. Through experimentation using simulated environments, the enhancement of the conventional RL approaches in tasks related to assistive robotics is demonstrated.
5/14/2024