ReMamba: Equip Mamba with Effective Long-Sequence Modeling

25

Sign in to get full access
Overview
- This paper introduces ReMamba, a technique to equip the Mamba language model with effective long-sequence modeling capabilities.
- Mamba is a popular large language model, but it struggles with modeling long sequences of text.
- ReMamba aims to address this limitation by incorporating state space models into the Mamba architecture.
Plain English Explanation
ReMamba: Equipping Mamba with Effective Long-Sequence Modeling is a research paper that proposes a new approach to enhance the Mamba language model's ability to handle long sequences of text.
Mamba is a well-known large language model, but it has difficulty processing and generating long passages of text. The researchers behind ReMamba recognized this limitation and sought to find a solution. Their approach involves integrating state space models into the Mamba architecture, which allows the model to better capture the temporal dynamics and long-range dependencies present in longer sequences.
By incorporating these state space techniques, the ReMamba model is able to more effectively learn and generate coherent text over extended periods, improving upon Mamba's original capabilities. This advancement could have significant implications for applications that require the language model to work with lengthy documents, conversations, or other long-form content.
Technical Explanation
The Preliminaries section introduces the key concepts underlying the ReMamba approach. It explains state space models, which are a class of models that can effectively capture the temporal evolution of a system's internal state. The researchers hypothesized that integrating such state space techniques into the Mamba model would allow it to better handle long-sequence modeling tasks.
The core of the ReMamba architecture involves incorporating state space models directly into the Mamba model. This is achieved through various architectural modifications, such as introducing recurrent state transitions and modulating the model's outputs based on the evolving internal state. The specific details of these modifications are outlined in the paper.
The researchers conducted extensive experiments to evaluate the performance of ReMamba on a range of long-sequence tasks, including language modeling, text generation, and question-answering. The results demonstrate that ReMamba significantly outperforms the original Mamba model, highlighting the effectiveness of the state space modeling approach in enhancing long-sequence capabilities.
Critical Analysis
The paper provides a thorough and well-designed study of the ReMamba approach. The researchers have clearly identified a significant limitation in the Mamba model and have proposed a thoughtful solution that builds upon established state space modeling techniques.
One potential area for further investigation mentioned in the paper is the interpretability of the ReMamba model's internal dynamics. While the state space components improve performance, the interpretability and explainability of the model's decision-making process could be an interesting avenue for future research.
Additionally, the paper does not extensively explore the computational efficiency and resource requirements of the ReMamba model compared to the original Mamba. This information would be valuable for understanding the practical trade-offs and deployment considerations of the proposed approach.
Overall, the ReMamba paper presents a compelling and well-executed research contribution that addresses an important problem in large language model design. The integration of state space modeling techniques is a promising direction for enhancing the long-sequence capabilities of language models like Mamba.
Conclusion
The ReMamba: Equipping Mamba with Effective Long-Sequence Modeling paper introduces a novel approach to improve the long-sequence modeling capabilities of the Mamba language model. By incorporating state space modeling techniques into the Mamba architecture, the researchers have developed a more effective model that can better capture temporal dynamics and long-range dependencies in text.
The results of the study demonstrate the effectiveness of the ReMamba approach, showcasing significant performance improvements over the original Mamba model on a range of long-sequence tasks. This advancement has the potential to unlock new applications and use cases for language models that require the ability to process and generate coherent text over extended periods.
Overall, the ReMamba paper represents an important contribution to the field of large language model development, highlighting the value of integrating specialized modeling techniques to enhance the core capabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
25
ReMamba: Equip Mamba with Effective Long-Sequence Modeling
Danlong Yuan, Jiahao Liu, Bei Li, Huishuai Zhang, Jingang Wang, Xunliang Cai, Dongyan Zhao
While the Mamba architecture demonstrates superior inference efficiency and competitive performance on short-context natural language processing (NLP) tasks, empirical evidence suggests its capacity to comprehend long contexts is limited compared to transformer-based models. In this study, we investigate the long-context efficiency issues of the Mamba models and propose ReMamba, which enhances Mamba's ability to comprehend long contexts. ReMamba incorporates selective compression and adaptation techniques within a two-stage re-forward process, incurring minimal additional inference costs overhead. Experimental results on the LongBench and L-Eval benchmarks demonstrate ReMamba's efficacy, improving over the baselines by 3.2 and 1.6 points, respectively, and attaining performance almost on par with same-size transformer models.
Read more9/4/2024

0
DeciMamba: Exploring the Length Extrapolation Potential of Mamba
Assaf Ben-Kish, Itamar Zimerman, Shady Abu-Hussein, Nadav Cohen, Amir Globerson, Lior Wolf, Raja Giryes
Long-range sequence processing poses a significant challenge for Transformers due to their quadratic complexity in input length. A promising alternative is Mamba, which demonstrates high performance and achieves Transformer-level capabilities while requiring substantially fewer computational resources. In this paper we explore the length-generalization capabilities of Mamba, which we find to be relatively limited. Through a series of visualizations and analyses we identify that the limitations arise from a restricted effective receptive field, dictated by the sequence length used during training. To address this constraint, we introduce DeciMamba, a context-extension method specifically designed for Mamba. This mechanism, built on top of a hidden filtering mechanism embedded within the S6 layer, enables the trained model to extrapolate well even without additional training. Empirical experiments over real-world long-range NLP tasks show that DeciMamba can extrapolate to context lengths that are 25x times longer than the ones seen during training, and does so without utilizing additional computational resources. We will release our code and models.
Read more6/21/2024
0
Mamba Retriever: Utilizing Mamba for Effective and Efficient Dense Retrieval
Hanqi Zhang, Chong Chen, Lang Mei, Qi Liu, Jiaxin Mao
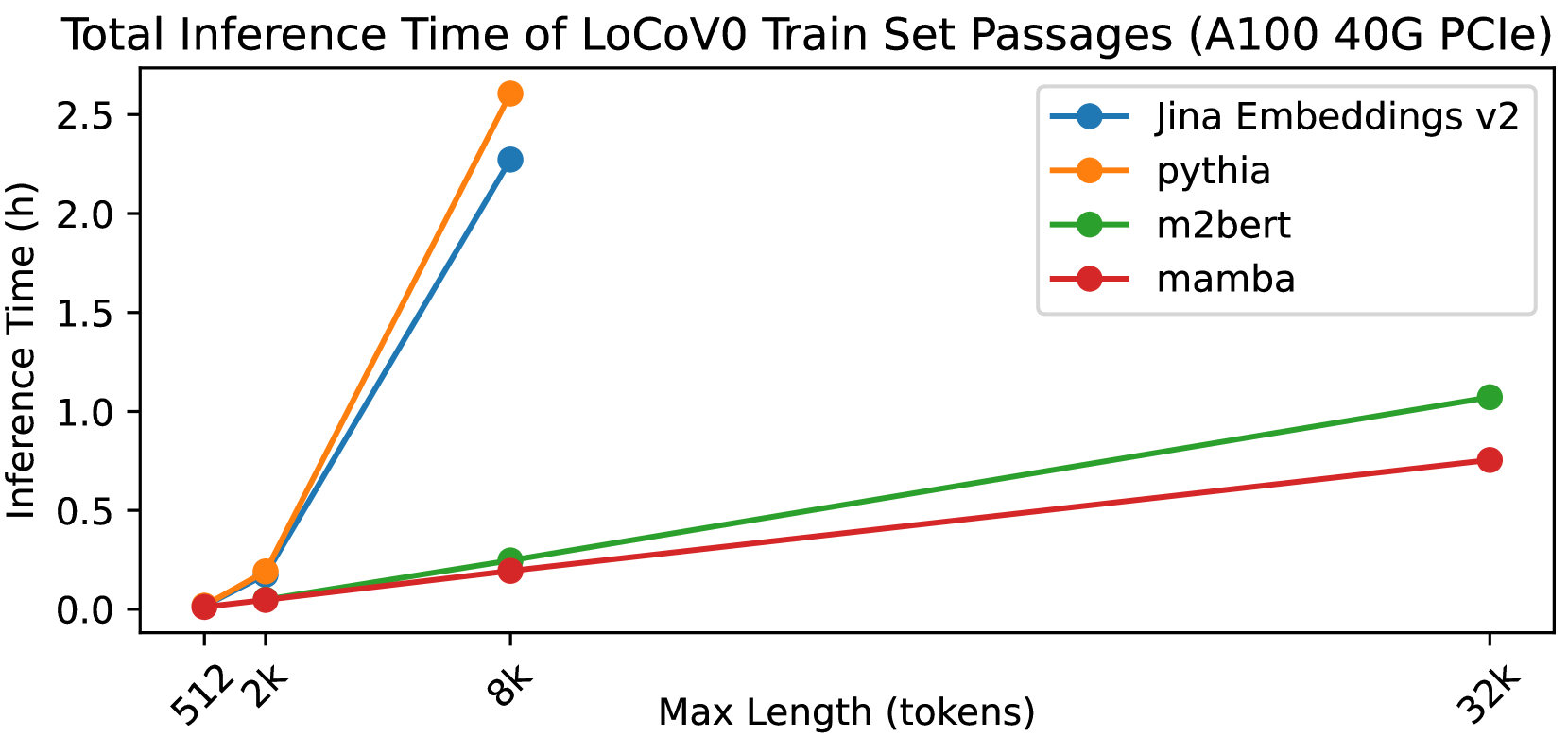
In the information retrieval (IR) area, dense retrieval (DR) models use deep learning techniques to encode queries and passages into embedding space to compute their semantic relations. It is important for DR models to balance both efficiency and effectiveness. Pre-trained language models (PLMs), especially Transformer-based PLMs, have been proven to be effective encoders of DR models. However, the self-attention component in Transformer-based PLM results in a computational complexity that grows quadratically with sequence length, and thus exhibits a slow inference speed for long-text retrieval. Some recently proposed non-Transformer PLMs, especially the Mamba architecture PLMs, have demonstrated not only comparable effectiveness to Transformer-based PLMs on generative language tasks but also better efficiency due to linear time scaling in sequence length. This paper implements the Mamba Retriever to explore whether Mamba can serve as an effective and efficient encoder of DR model for IR tasks. We fine-tune the Mamba Retriever on the classic short-text MS MARCO passage ranking dataset and the long-text LoCoV0 dataset. Experimental results show that (1) on the MS MARCO passage ranking dataset and BEIR, the Mamba Retriever achieves comparable or better effectiveness compared to Transformer-based retrieval models, and the effectiveness grows with the size of the Mamba model; (2) on the long-text LoCoV0 dataset, the Mamba Retriever can extend to longer text length than its pre-trained length after fine-tuning on retrieval task, and it has comparable or better effectiveness compared to other long-text retrieval models; (3) the Mamba Retriever has superior inference speed for long-text retrieval. In conclusion, Mamba Retriever is both effective and efficient, making it a practical model, especially for long-text retrieval.
Read more8/23/2024

0
Decision Mamba: Reinforcement Learning via Hybrid Selective Sequence Modeling
Sili Huang, Jifeng Hu, Zhejian Yang, Liwei Yang, Tao Luo, Hechang Chen, Lichao Sun, Bo Yang
Recent works have shown the remarkable superiority of transformer models in reinforcement learning (RL), where the decision-making problem is formulated as sequential generation. Transformer-based agents could emerge with self-improvement in online environments by providing task contexts, such as multiple trajectories, called in-context RL. However, due to the quadratic computation complexity of attention in transformers, current in-context RL methods suffer from huge computational costs as the task horizon increases. In contrast, the Mamba model is renowned for its efficient ability to process long-term dependencies, which provides an opportunity for in-context RL to solve tasks that require long-term memory. To this end, we first implement Decision Mamba (DM) by replacing the backbone of Decision Transformer (DT). Then, we propose a Decision Mamba-Hybrid (DM-H) with the merits of transformers and Mamba in high-quality prediction and long-term memory. Specifically, DM-H first generates high-value sub-goals from long-term memory through the Mamba model. Then, we use sub-goals to prompt the transformer, establishing high-quality predictions. Experimental results demonstrate that DM-H achieves state-of-the-art in long and short-term tasks, such as D4RL, Grid World, and Tmaze benchmarks. Regarding efficiency, the online testing of DM-H in the long-term task is 28$times$ times faster than the transformer-based baselines.
Read more6/4/2024