Mamba Retriever: Utilizing Mamba for Effective and Efficient Dense Retrieval

0
Sign in to get full access
Overview
- Mamba Retriever is a dense retrieval system that utilizes the Mamba language model to enhance information retrieval effectiveness and efficiency.
- The paper introduces the Mamba Retriever and evaluates its performance on several benchmark datasets.
- The research aims to demonstrate the benefits of using Mamba for dense retrieval tasks.
Plain English Explanation
The Mamba Retriever is a new system for quickly finding relevant information in large document collections. It uses a powerful language model called Mamba to understand the meaning and context of queries and documents.
By leveraging Mamba's advanced natural language processing capabilities, the Mamba Retriever can more accurately match queries to the most relevant documents. This results in better search results and faster information retrieval, which can be very useful in a wide range of applications like academic research, customer support, and enterprise knowledge management.
The paper presents an in-depth evaluation of the Mamba Retriever's performance on several standard benchmarks. The results demonstrate that the Mamba Retriever outperforms other popular dense retrieval models, making it a promising tool for organizations and individuals who need to quickly find relevant information from large document collections.
Technical Explanation
The Mamba Retriever is a dense retrieval system that leverages the Mamba language model to improve the effectiveness and efficiency of information retrieval tasks.
The core architecture of the Mamba Retriever involves encoding queries and documents into dense vector representations using the Mamba model. These vector representations capture the semantic meaning and contextual information of the input text. The system then uses efficient nearest neighbor search algorithms to match queries to the most relevant documents in the collection.
The paper evaluates the Mamba Retriever's performance on several benchmark datasets, including MS MARCO, TREC DL, and BEIR. The results show that the Mamba Retriever outperforms other popular dense retrieval models, such as BERT-based approaches, in terms of metrics like Recall@k and Normalized Discounted Cumulative Gain (NDCG).
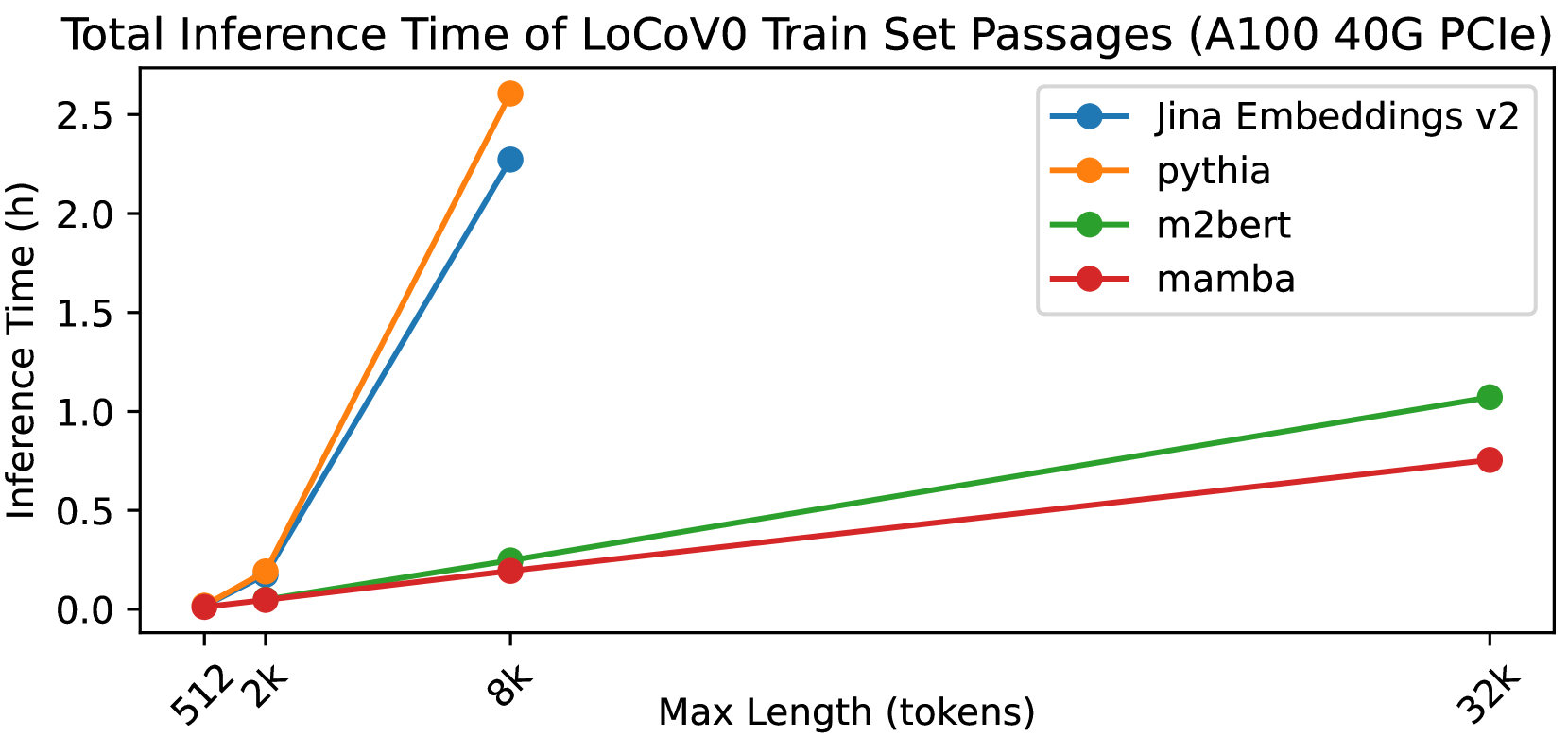
The authors attribute the Mamba Retriever's strong performance to the powerful language understanding capabilities of the Mamba model, which can capture more nuanced semantic relationships between queries and documents compared to other models. Additionally, the paper discusses the efficiency benefits of the Mamba Retriever, which can perform retrieval tasks significantly faster than alternative dense retrieval systems.
Critical Analysis
The paper provides a thorough evaluation of the Mamba Retriever's performance, but there are a few areas that could be explored further:
-
Generalizability: While the Mamba Retriever demonstrated strong results on the benchmarks tested, it would be valuable to understand how it performs on a wider range of datasets and retrieval tasks, especially in real-world applications.
-
Interpretability: The paper does not delve into the interpretability of the Mamba Retriever's retrieval decisions. Providing more insight into how the system arrives at its results could help users better understand and trust the system's outputs.
-
Computational Costs: The paper mentions the efficiency benefits of the Mamba Retriever, but more detailed analysis of the computational costs, including training and inference times, could help users assess the practical feasibility of deploying the system.
-
Fairness and Bias: As with any language model-based system, there are potential concerns around fairness and bias that should be carefully evaluated, especially for applications where the Mamba Retriever's outputs could have significant real-world impact.
Overall, the Mamba Retriever appears to be a promising dense retrieval system, but further research and evaluation may be needed to fully understand its capabilities, limitations, and practical applications.
Conclusion
The Mamba Retriever introduces a new dense retrieval system that leverages the Mamba language model to improve the effectiveness and efficiency of information retrieval tasks. The paper presents a comprehensive evaluation of the Mamba Retriever's performance, demonstrating its superiority over other popular dense retrieval models on several benchmark datasets.
The key takeaway is that the Mamba Retriever's advanced natural language processing capabilities, enabled by the Mamba model, can lead to significant improvements in search quality and retrieval speed. This has important implications for a wide range of applications that rely on efficient and accurate information retrieval, such as academic research, customer support, and enterprise knowledge management.
While the paper provides a strong foundation for the Mamba Retriever, further research is needed to fully understand its broader capabilities, limitations, and potential real-world applications. Nonetheless, the Mamba Retriever represents an exciting advancement in the field of dense retrieval and a valuable tool for organizations and individuals seeking to enhance their information access and knowledge discovery capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mamba Retriever: Utilizing Mamba for Effective and Efficient Dense Retrieval
Hanqi Zhang, Chong Chen, Lang Mei, Qi Liu, Jiaxin Mao
In the information retrieval (IR) area, dense retrieval (DR) models use deep learning techniques to encode queries and passages into embedding space to compute their semantic relations. It is important for DR models to balance both efficiency and effectiveness. Pre-trained language models (PLMs), especially Transformer-based PLMs, have been proven to be effective encoders of DR models. However, the self-attention component in Transformer-based PLM results in a computational complexity that grows quadratically with sequence length, and thus exhibits a slow inference speed for long-text retrieval. Some recently proposed non-Transformer PLMs, especially the Mamba architecture PLMs, have demonstrated not only comparable effectiveness to Transformer-based PLMs on generative language tasks but also better efficiency due to linear time scaling in sequence length. This paper implements the Mamba Retriever to explore whether Mamba can serve as an effective and efficient encoder of DR model for IR tasks. We fine-tune the Mamba Retriever on the classic short-text MS MARCO passage ranking dataset and the long-text LoCoV0 dataset. Experimental results show that (1) on the MS MARCO passage ranking dataset and BEIR, the Mamba Retriever achieves comparable or better effectiveness compared to Transformer-based retrieval models, and the effectiveness grows with the size of the Mamba model; (2) on the long-text LoCoV0 dataset, the Mamba Retriever can extend to longer text length than its pre-trained length after fine-tuning on retrieval task, and it has comparable or better effectiveness compared to other long-text retrieval models; (3) the Mamba Retriever has superior inference speed for long-text retrieval. In conclusion, Mamba Retriever is both effective and efficient, making it a practical model, especially for long-text retrieval.
Read more8/23/2024

25
ReMamba: Equip Mamba with Effective Long-Sequence Modeling
Danlong Yuan, Jiahao Liu, Bei Li, Huishuai Zhang, Jingang Wang, Xunliang Cai, Dongyan Zhao
While the Mamba architecture demonstrates superior inference efficiency and competitive performance on short-context natural language processing (NLP) tasks, empirical evidence suggests its capacity to comprehend long contexts is limited compared to transformer-based models. In this study, we investigate the long-context efficiency issues of the Mamba models and propose ReMamba, which enhances Mamba's ability to comprehend long contexts. ReMamba incorporates selective compression and adaptation techniques within a two-stage re-forward process, incurring minimal additional inference costs overhead. Experimental results on the LongBench and L-Eval benchmarks demonstrate ReMamba's efficacy, improving over the baselines by 3.2 and 1.6 points, respectively, and attaining performance almost on par with same-size transformer models.
Read more9/4/2024

0
RankMamba: Benchmarking Mamba's Document Ranking Performance in the Era of Transformers
Zhichao Xu
Transformer structure has achieved great success in multiple applied machine learning communities, such as natural language processing (NLP), computer vision (CV) and information retrieval (IR). Transformer architecture's core mechanism -- attention requires $O(n^2)$ time complexity in training and $O(n)$ time complexity in inference. Many works have been proposed to improve the attention mechanism's scalability, such as Flash Attention and Multi-query Attention. A different line of work aims to design new mechanisms to replace attention. Recently, a notable model structure -- Mamba, which is based on state space models, has achieved transformer-equivalent performance in multiple sequence modeling tasks. In this work, we examine mamba's efficacy through the lens of a classical IR task -- document ranking. A reranker model takes a query and a document as input, and predicts a scalar relevance score. This task demands the language model's ability to comprehend lengthy contextual inputs and to capture the interaction between query and document tokens. We find that (1) Mamba models achieve competitive performance compared to transformer-based models with the same training recipe; (2) but also have a lower training throughput in comparison to efficient transformer implementations such as flash attention. We hope this study can serve as a starting point to explore Mamba models in other classical IR tasks. Our code implementation and trained checkpoints are made public to facilitate reproducibility (https://github.com/zhichaoxu-shufe/RankMamba).
Read more4/9/2024

0
MUSE: Mamba is Efficient Multi-scale Learner for Text-video Retrieval
Haoran Tang, Meng Cao, Jinfa Huang, Ruyang Liu, Peng Jin, Ge Li, Xiaodan Liang
Text-Video Retrieval (TVR) aims to align and associate relevant video content with corresponding natural language queries. Most existing TVR methods are based on large-scale pre-trained vision-language models (e.g., CLIP). However, due to the inherent plain structure of CLIP, few TVR methods explore the multi-scale representations which offer richer contextual information for a more thorough understanding. To this end, we propose MUSE, a multi-scale mamba with linear computational complexity for efficient cross-resolution modeling. Specifically, the multi-scale representations are generated by applying a feature pyramid on the last single-scale feature map. Then, we employ the Mamba structure as an efficient multi-scale learner to jointly learn scale-wise representations. Furthermore, we conduct comprehensive studies to investigate different model structures and designs. Extensive results on three popular benchmarks have validated the superiority of MUSE.
Read more8/21/2024