A replica analysis of under-bagging
2404.09779
0
0
Abstract
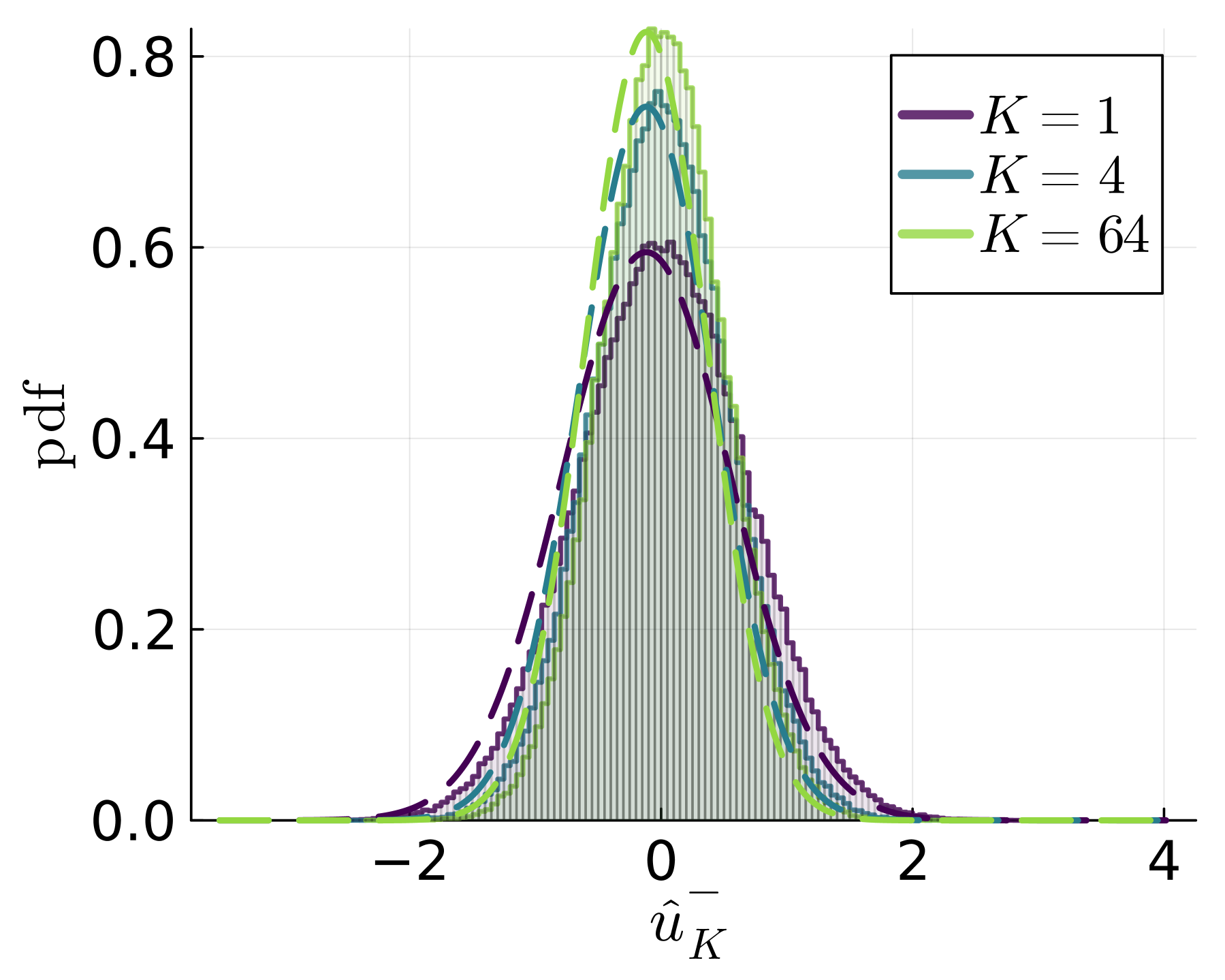
Under-bagging (UB), which combines under sampling and bagging, is a popular ensemble learning method for training classifiers on an imbalanced data. Using bagging to reduce the increased variance caused by the reduction in sample size due to under sampling is a natural approach. However, it has recently been pointed out that in generalized linear models, naive bagging, which does not consider the class imbalance structure, and ridge regularization can produce the same results. Therefore, it is not obvious whether it is better to use UB, which requires an increased computational cost proportional to the number of under-sampled data sets, when training linear models. Given such a situation, in this study, we heuristically derive a sharp asymptotics of UB and use it to compare with several other standard methods for learning from imbalanced data, in the scenario where a linear classifier is trained from a two-component mixture data. The methods compared include the under-sampling (US) method, which trains a model using a single realization of the subsampled data, and the simple weighting (SW) method, which trains a model with a weighted loss on the entire data. It is shown that the performance of UB is improved by increasing the size of the majority class while keeping the size of the minority fixed, even though the class imbalance can be large, especially when the size of the minority class is small. This is in contrast to US, whose performance does not change as the size of the majority class increases, and SW, whose performance decreases as the imbalance increases. These results are different from the case of the naive bagging when training generalized linear models without considering the structure of the class imbalance, indicating the intrinsic difference between the ensembling and the direct regularization on the parameters.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper provides a detailed analysis of the under-bagging technique, which is a variation of the popular bagging ensemble method used in machine learning.
- The paper explores the theoretical properties of under-bagging and compares its performance to standard bagging through a replica analysis.
- The findings offer insights into when and why under-bagging may be preferred over bagging, particularly in scenarios with high-dimensional data or model complexity.
Plain English Explanation
Bagging is a machine learning technique that combines multiple models to improve the overall accuracy and reliability of predictions. Under-bagging is a variation of this approach that uses a smaller number of models compared to standard bagging.
The researchers in this paper wanted to understand how under-bagging works and when it might be a better choice than regular bagging. They used a mathematical technique called "replica analysis" to study the theoretical properties of under-bagging.
The key insights from their analysis are:
- Under-bagging can outperform standard bagging in high-dimensional settings or when the individual models are very complex. In these cases, using fewer but more powerful models can be more effective than combining many simpler models.
- Under-bagging is particularly advantageous when there is a large difference in the performance of the individual models. By focusing on the stronger models, under-bagging can leverage their strengths more effectively.
- However, under-bagging also has some limitations. If the individual models are not very diverse or have similar weaknesses, then standard bagging may still be the better choice.
Overall, this research provides a deeper understanding of the tradeoffs between bagging and under-bagging, which can help machine learning practitioners select the most appropriate ensemble technique for their specific problem and data characteristics.
Technical Explanation
The paper presents a detailed replica analysis of the under-bagging technique. Under-bagging is a variation of the standard bagging ensemble method, where a smaller number of base models are combined instead of the full ensemble.
The authors derive precise expressions for the generalization error of under-bagging in the high-dimensional limit. They compare these results to the known performance of standard bagging, identifying the key factors that determine when under-bagging will outperform or underperform the traditional approach.
The main findings are:
- Under-bagging can achieve lower generalization error than bagging when the individual models are highly complex or the data has a high dimensionality. In these scenarios, the benefit of using stronger, more diverse models outweighs the disadvantage of having fewer base models.
- The relative advantage of under-bagging increases as the gap in performance between the best and worst individual models grows larger. By focusing on the stronger models, under-bagging is able to leverage their strengths more effectively.
- However, under-bagging is more sensitive to the diversity of the individual models. If the models have similar weaknesses, then standard bagging may still be preferable as it can average out these common flaws more effectively.
The theoretical analysis is complemented by numerical experiments that validate the predicted trends and provide additional insights into the practical considerations for choosing between bagging and under-bagging.
Critical Analysis
The paper provides a thorough theoretical analysis of under-bagging and carefully compares its performance to standard bagging. The replica analysis technique used is well-established in the machine learning literature and gives the authors a rigorous mathematical framework to study the problem.
One potential limitation of the work is that the analysis is primarily focused on the high-dimensional asymptotic regime. While this setting is highly relevant for many modern machine learning applications, it would be valuable to also understand the behavior of under-bagging in finite-sample scenarios, where the assumptions of the replica analysis may not hold as neatly.
Additionally, the paper does not explore the sensitivity of under-bagging's performance to the specific choice of base models or the techniques used to select the subset of models. These implementation details could have a significant impact on the practical viability of under-bagging, and warrant further investigation.
Finally, while the paper discusses the tradeoffs between bagging and under-bagging, it does not provide clear guidelines on how to choose between the two approaches for a given problem. Developing such decision-making frameworks would help practitioners apply the insights from this research more effectively.
Overall, this is a well-executed theoretical study that advances our understanding of under-bagging and its relationship to standard bagging. The results offer useful guidance, but there remain opportunities for further research to broaden the applicability and usability of these findings.
Conclusion
This research paper provides a detailed replica analysis of the under-bagging ensemble technique, which uses a smaller number of base models compared to standard bagging. The theoretical analysis reveals that under-bagging can outperform bagging in high-dimensional settings or when the individual models are highly complex, particularly when there is a large gap in performance between the best and worst models.
These insights help expand our understanding of the tradeoffs between bagging and under-bagging, and offer guidance to machine learning practitioners on when to consider using the under-bagging approach. By exploring the theoretical properties of these ensemble techniques, the researchers provide a foundation for more informed decisions about model architecture and data usage in complex machine learning problems.
Overall, this work contributes to the ongoing efforts to develop more robust and effective ensemble learning methods, with implications for a wide range of applications where accurate and reliable predictive models are paramount.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!Restoring balance: principled under/oversampling of data for optimal classification
Emanuele Loffredo, Mauro Pastore, Simona Cocco, R'emi Monasson
0
0
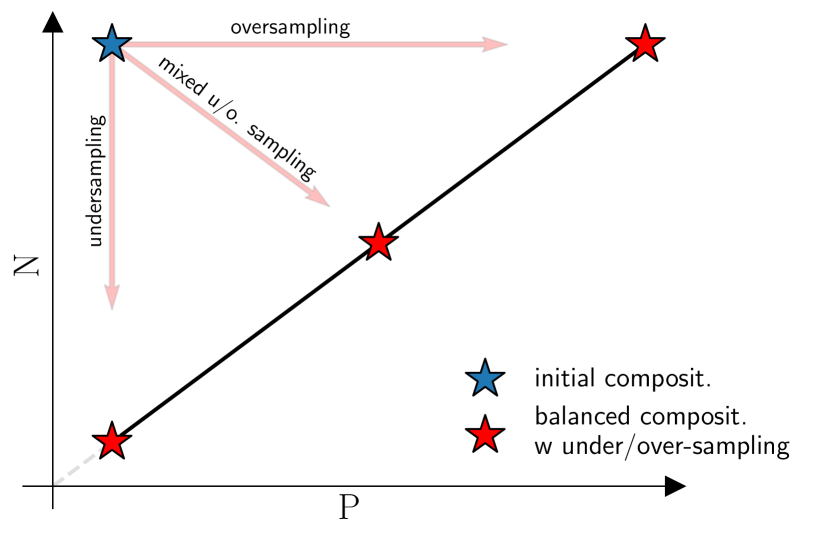
Class imbalance in real-world data poses a common bottleneck for machine learning tasks, since achieving good generalization on under-represented examples is often challenging. Mitigation strategies, such as under or oversampling the data depending on their abundances, are routinely proposed and tested empirically, but how they should adapt to the data statistics remains poorly understood. In this work, we determine exact analytical expressions of the generalization curves in the high-dimensional regime for linear classifiers (Support Vector Machines). We also provide a sharp prediction of the effects of under/oversampling strategies depending on class imbalance, first and second moments of the data, and the metrics of performance considered. We show that mixed strategies involving under and oversampling of data lead to performance improvement. Through numerical experiments, we show the relevance of our theoretical predictions on real datasets, on deeper architectures and with sampling strategies based on unsupervised probabilistic models.
5/16/2024
🎲
Sharp error bounds for imbalanced classification: how many examples in the minority class?
Anass Aghbalou, Franc{c}ois Portier, Anne Sabourin
0
0
When dealing with imbalanced classification data, reweighting the loss function is a standard procedure allowing to equilibrate between the true positive and true negative rates within the risk measure. Despite significant theoretical work in this area, existing results do not adequately address a main challenge within the imbalanced classification framework, which is the negligible size of one class in relation to the full sample size and the need to rescale the risk function by a probability tending to zero. To address this gap, we present two novel contributions in the setting where the rare class probability approaches zero: (1) a non asymptotic fast rate probability bound for constrained balanced empirical risk minimization, and (2) a consistent upper bound for balanced nearest neighbors estimates. Our findings provide a clearer understanding of the benefits of class-weighting in realistic settings, opening new avenues for further research in this field.
4/17/2024
📉
Sharp analysis of out-of-distribution error for importance-weighted estimators in the overparameterized regime
Kuo-Wei Lai, Vidya Muthukumar
0
0
Overparameterized models that achieve zero training error are observed to generalize well on average, but degrade in performance when faced with data that is under-represented in the training sample. In this work, we study an overparameterized Gaussian mixture model imbued with a spurious feature, and sharply analyze the in-distribution and out-of-distribution test error of a cost-sensitive interpolating solution that incorporates importance weights. Compared to recent work Wang et al. (2021), Behnia et al. (2022), our analysis is sharp with matching upper and lower bounds, and significantly weakens required assumptions on data dimensionality. Our error characterizations also apply to any choice of importance weights and unveil a novel tradeoff between worst-case robustness to distribution shift and average accuracy as a function of the importance weight magnitude.
5/13/2024
📊
Theoretical Guarantees of Data Augmented Last Layer Retraining Methods
Monica Welfert, Nathan Stromberg, Lalitha Sankar
0
0
Ensuring fair predictions across many distinct subpopulations in the training data can be prohibitive for large models. Recently, simple linear last layer retraining strategies, in combination with data augmentation methods such as upweighting, downsampling and mixup, have been shown to achieve state-of-the-art performance for worst-group accuracy, which quantifies accuracy for the least prevalent subpopulation. For linear last layer retraining and the abovementioned augmentations, we present the optimal worst-group accuracy when modeling the distribution of the latent representations (input to the last layer) as Gaussian for each subpopulation. We evaluate and verify our results for both synthetic and large publicly available datasets.
5/10/2024