Sharp analysis of out-of-distribution error for importance-weighted estimators in the overparameterized regime

0
📉
Sign in to get full access
Overview
- Overparameterized models can achieve zero training error but may degrade in performance when faced with data that is underrepresented in the training sample.
- This paper studies an overparameterized Gaussian mixture model with a spurious feature, and analyzes the in-distribution and out-of-distribution test error of a cost-sensitive interpolating solution that incorporates importance weights.
- The analysis provides sharp upper and lower bounds on the error, and significantly weakens the required assumptions on data dimensionality compared to recent related work.
- The error characterizations apply to any choice of importance weights and unveil a novel tradeoff between worst-case robustness to distribution shift and average accuracy as a function of the importance weight magnitude.
Plain English Explanation
Machine learning models that have a large number of parameters can sometimes achieve perfect performance on the data they are trained on. However, these overparameterized models may not generalize well to new, unseen data that is different from the training data.
This paper looks at a specific type of overparameterized model - a Gaussian mixture model with an extra, irrelevant "spurious" feature. The researchers analyze how well this model performs on data that is similar to the training data (in-distribution) versus data that is different (out-of-distribution).
They use a technique called "importance weighting" to try to improve the model's performance on the out-of-distribution data. Importance weighting assigns higher weights to data points that are underrepresented in the training set, to compensate for the model's tendency to focus on the more common training data.
The analysis in the paper provides precise upper and lower bounds on the model's error rates, and shows that the required assumptions are less restrictive than in some previous related work, such as Behnia et al. (2022) and Wang et al. (2021).
Importantly, the results reveal a tradeoff between the model's robustness to distribution shift (how well it performs on out-of-distribution data) and its average accuracy. The magnitude of the importance weights used can control this tradeoff - higher weights can improve robustness, but may come at the cost of reduced average performance.
Technical Explanation
The paper studies an overparameterized Gaussian mixture model with a spurious feature, and analyzes the in-distribution and out-of-distribution test error of a cost-sensitive interpolating solution that incorporates importance weights.
The key technical elements are:
-
Model architecture: The model is a Gaussian mixture with a spurious feature - an additional feature that is irrelevant for the classification task.
-
Importance weighting: The researchers use a cost-sensitive interpolating solution that incorporates importance weights. These weights are designed to compensate for underrepresented data points in the training set, with the goal of improving out-of-distribution performance.
-
Error analysis: The paper provides sharp upper and lower bounds on the in-distribution and out-of-distribution test errors of the model. These bounds are shown to be tighter and require weaker assumptions on data dimensionality compared to recent related work.
-
Tradeoff analysis: The error characterizations reveal a novel tradeoff between worst-case robustness to distribution shift and average accuracy, as a function of the importance weight magnitude. This tradeoff can guide the choice of importance weights in practice.
Critical Analysis
The paper makes important contributions to the understanding of overparameterized models and their behavior under distribution shift. The sharp error bounds and the weakening of required assumptions are significant technical advances.
However, the analysis is limited to a specific Gaussian mixture model with a spurious feature. While this provides a tractable setting for the theoretical analysis, the real-world applicability of the results may be limited. Extending the analysis to more complex model architectures and data distributions would be an important direction for future research.
Additionally, the paper does not address the practical challenges of estimating the appropriate importance weights in real-world scenarios, where the true data distributions may be unknown. Incorporating more realistic weight estimation techniques into the analysis could further enhance the relevance of the findings.
Finally, the paper focuses on the statistical properties of the model, but does not delve into the computational aspects of training and deploying such overparameterized models. Understanding the interplay between statistical and computational considerations would be valuable for developing effective strategies for robust machine learning.
Conclusion
This paper provides a detailed theoretical analysis of the in-distribution and out-of-distribution performance of an overparameterized Gaussian mixture model with a spurious feature. The key insights are:
- The model can achieve zero training error but may degrade in performance on out-of-distribution data.
- Importance weighting can help improve robustness to distribution shift, but there is a tradeoff between worst-case robustness and average accuracy.
- The analysis offers sharp error bounds and relaxes assumptions compared to previous related work.
These findings contribute to our understanding of the challenges and opportunities in developing robust machine learning models that can generalize well beyond the training data. Further research is needed to extend these insights to more complex real-world scenarios and practical deployment considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Sharp analysis of out-of-distribution error for importance-weighted estimators in the overparameterized regime
Kuo-Wei Lai, Vidya Muthukumar
Overparameterized models that achieve zero training error are observed to generalize well on average, but degrade in performance when faced with data that is under-represented in the training sample. In this work, we study an overparameterized Gaussian mixture model imbued with a spurious feature, and sharply analyze the in-distribution and out-of-distribution test error of a cost-sensitive interpolating solution that incorporates importance weights. Compared to recent work Wang et al. (2021), Behnia et al. (2022), our analysis is sharp with matching upper and lower bounds, and significantly weakens required assumptions on data dimensionality. Our error characterizations also apply to any choice of importance weights and unveil a novel tradeoff between worst-case robustness to distribution shift and average accuracy as a function of the importance weight magnitude.
Read more5/13/2024
0
Quantifying Distribution Shifts and Uncertainties for Enhanced Model Robustness in Machine Learning Applications
Vegard Flovik
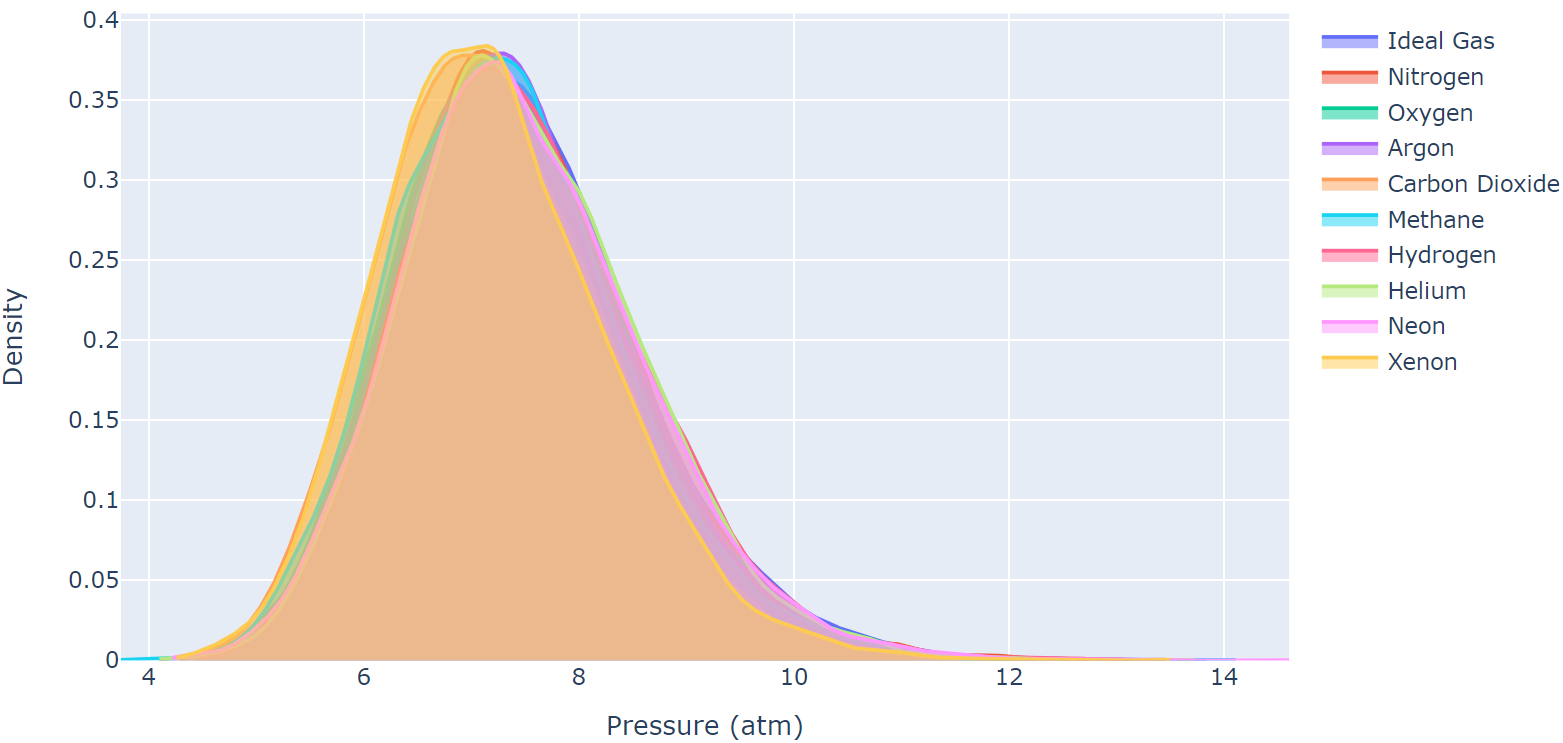
Distribution shifts, where statistical properties differ between training and test datasets, present a significant challenge in real-world machine learning applications where they directly impact model generalization and robustness. In this study, we explore model adaptation and generalization by utilizing synthetic data to systematically address distributional disparities. Our investigation aims to identify the prerequisites for successful model adaptation across diverse data distributions, while quantifying the associated uncertainties. Specifically, we generate synthetic data using the Van der Waals equation for gases and employ quantitative measures such as Kullback-Leibler divergence, Jensen-Shannon distance, and Mahalanobis distance to assess data similarity. These metrics en able us to evaluate both model accuracy and quantify the associated uncertainty in predictions arising from data distribution shifts. Our findings suggest that utilizing statistical measures, such as the Mahalanobis distance, to determine whether model predictions fall within the low-error interpolation regime or the high-error extrapolation regime provides a complementary method for assessing distribution shift and model uncertainty. These insights hold significant value for enhancing model robustness and generalization, essential for the successful deployment of machine learning applications in real-world scenarios.
Read more5/6/2024
0
Misspecification uncertainties in near-deterministic regression
Thomas D Swinburne, Danny Perez
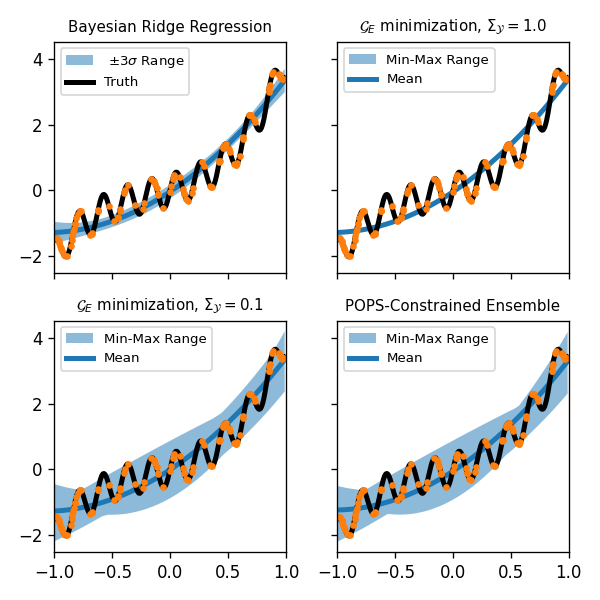
Bayesian regression determines model parameters by minimizing the expected loss, an upper bound to the true generalization error. However, the loss ignores misspecification, where models are imperfect. Parameter uncertainties from Bayesian regression are thus significantly underestimated and vanish in the large data limit. This is particularly problematic when building models of low- noise, or near-deterministic, calculations, as the main source of uncertainty is neglected. We analyze the generalization error of misspecified, near-deterministic surrogate models, a regime of broad relevance in science and engineering. We show posterior distributions must cover every training point to avoid a divergent generalization error and design an ansatz that respects this constraint, which for linear models incurs minimal overhead. This is demonstrated on model problems before application to thousand dimensional datasets in atomistic machine learning. Our efficient misspecification-aware scheme gives accurate prediction and bounding of test errors where existing schemes fail, allowing this important source of uncertainty to be incorporated in computational workflows.
Read more5/8/2024
✨
0
Spurious Feature Diversification Improves Out-of-distribution Generalization
Yong Lin, Lu Tan, Yifan Hao, Honam Wong, Hanze Dong, Weizhong Zhang, Yujiu Yang, Tong Zhang
Generalization to out-of-distribution (OOD) data is a critical challenge in machine learning. Ensemble-based methods, like weight space ensembles that interpolate model parameters, have been shown to achieve superior OOD performance. However, the underlying mechanism for their effectiveness remains unclear. In this study, we closely examine WiSE-FT, a popular weight space ensemble method that interpolates between a pre-trained and a fine-tuned model. We observe an unexpected ``FalseFalseTrue phenomenon, in which WiSE-FT successfully corrects many cases where each individual model makes incorrect predictions, which contributes significantly to its OOD effectiveness. To gain further insights, we conduct theoretical analysis in a multi-class setting with a large number of spurious features. Our analysis predicts the above phenomenon and it further shows that ensemble-based models reduce prediction errors in the OOD settings by utilizing a more diverse set of spurious features. Contrary to the conventional wisdom that focuses on learning invariant features for better OOD performance, our findings suggest that incorporating a large number of diverse spurious features weakens their individual contributions, leading to improved overall OOD generalization performance. Additionally, our findings provide the first explanation for the mysterious phenomenon of weight space ensembles outperforming output space ensembles in OOD. Empirically we demonstrate the effectiveness of utilizing diverse spurious features on a MultiColorMNIST dataset, and our experimental results are consistent with the theoretical analysis. Building upon the new theoretical insights into the efficacy of ensemble methods, we further propose a novel averaging method called BAlaNced averaGing (BANG) which significantly enhances the OOD performance of WiSE-FT.
Read more7/16/2024