Report Cards: Qualitative Evaluation of Language Models Using Natural Language Summaries

0
Sign in to get full access
Overview
- Describes a qualitative method for evaluating language models using natural language summaries
- Proposes "report cards" to provide a more comprehensive assessment of language model capabilities
- Aims to complement traditional metrics-based evaluations with a qualitative, human-centered approach
Plain English Explanation
This research paper introduces a new way to evaluate the performance of language models, which are artificial intelligence systems that can generate and understand human language. The traditional approach to evaluating language models has focused on metrics-based evaluations, such as measuring how accurately the model can complete certain tasks.
However, the researchers argue that these metrics don't always capture the full picture of a language model's capabilities. To address this, they propose using "report cards" - qualitative, natural language summaries written by humans to provide a more comprehensive assessment.
The idea is that these report cards can highlight nuanced aspects of the language model's performance, such as its ability to express empathy, creativity, or logical reasoning. This can complement the traditional metrics and give a richer, more holistic understanding of the model's strengths and weaknesses.
The researchers demonstrate their approach by having humans evaluate the performance of several prominent language models across a variety of tasks. The report cards provide detailed, descriptive feedback that goes beyond simply measuring accuracy or fluency. This can help developers and users better understand the real-world capabilities and limitations of these AI systems.
Technical Explanation
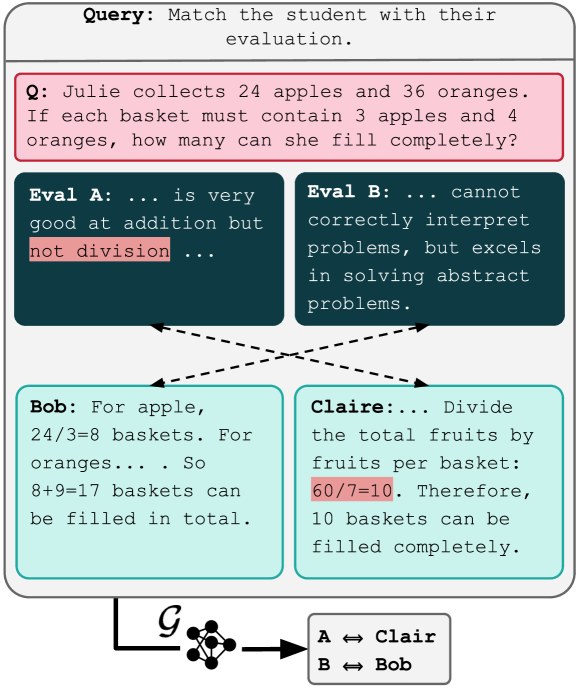
The researchers developed a qualitative evaluation method that involves having human evaluators write natural language "report cards" to assess language models. These report cards cover various aspects of the model's performance, such as its ability to follow instructions, demonstrate reasoning, and express creativity and empathy.
The evaluation process involves presenting the human evaluators with a set of prompts or tasks for the language model to complete. The evaluators then write detailed, descriptive summaries of the model's responses, highlighting both its strengths and weaknesses.
To ensure consistency, the researchers provided the evaluators with detailed guidelines and training on how to write the report cards. They also had multiple evaluators assess each language model to capture a range of perspectives.
The researchers applied this qualitative evaluation method to several prominent language models, including GPT-3, InstructGPT, and PaLM. The report cards generated by the human evaluators provided rich, nuanced feedback on the models' capabilities, going beyond traditional metrics like perplexity or BLEU scores.
The qualitative insights from the report cards revealed interesting patterns and tradeoffs in the language models' performance. For example, some models excelled at following instructions but struggled with open-ended creativity, while others demonstrated strong reasoning skills but lacked empathy in their responses.
Critical Analysis
The researchers acknowledge that their qualitative evaluation method has some limitations. The report cards are inherently subjective, and the evaluators' assessments may be influenced by their own biases and backgrounds. Additionally, the process of generating and analyzing the report cards is time-consuming and resource-intensive compared to automated metrics-based evaluations.
Furthermore, the paper does not provide a comprehensive comparison of the qualitative evaluation method to other proposed approaches for assessing language model performance, such as probing tasks or human-in-the-loop evaluations. It would be valuable to understand how the report card method compares to these alternatives in terms of the insights it provides and the practical considerations for deployment.
Despite these limitations, the researchers make a compelling case for the value of qualitative, human-centered evaluations of language models. The report card approach can reveal important nuances and tradeoffs that may be missed by traditional metrics-based assessments, particularly when it comes to the models' real-world capabilities and their potential impact on users.
Conclusion
This research paper proposes a novel approach to evaluating language models that goes beyond traditional metrics-based assessments. By having humans write detailed, natural language "report cards" to describe the models' performance, the researchers aim to capture a more holistic and nuanced understanding of their capabilities.
The qualitative insights provided by the report cards can complement existing evaluation methods and help developers and users better understand the strengths, weaknesses, and potential societal impacts of these powerful AI systems. While the method has some limitations, it represents an important step towards a more comprehensive and human-centered approach to language model evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Report Cards: Qualitative Evaluation of Language Models Using Natural Language Summaries
Blair Yang, Fuyang Cui, Keiran Paster, Jimmy Ba, Pashootan Vaezipoor, Silviu Pitis, Michael R. Zhang
The rapid development and dynamic nature of large language models (LLMs) make it difficult for conventional quantitative benchmarks to accurately assess their capabilities. We propose report cards, which are human-interpretable, natural language summaries of model behavior for specific skills or topics. We develop a framework to evaluate report cards based on three criteria: specificity (ability to distinguish between models), faithfulness (accurate representation of model capabilities), and interpretability (clarity and relevance to humans). We also propose an iterative algorithm for generating report cards without human supervision and explore its efficacy by ablating various design choices. Through experimentation with popular LLMs, we demonstrate that report cards provide insights beyond traditional benchmarks and can help address the need for a more interpretable and holistic evaluation of LLMs.
Read more9/4/2024
🤿
0
On the Evaluation of Machine-Generated Reports
James Mayfield, Eugene Yang, Dawn Lawrie, Sean MacAvaney, Paul McNamee, Douglas W. Oard, Luca Soldaini, Ian Soboroff, Orion Weller, Efsun Kayi, Kate Sanders, Marc Mason, Noah Hibbler
Large Language Models (LLMs) have enabled new ways to satisfy information needs. Although great strides have been made in applying them to settings like document ranking and short-form text generation, they still struggle to compose complete, accurate, and verifiable long-form reports. Reports with these qualities are necessary to satisfy the complex, nuanced, or multi-faceted information needs of users. In this perspective paper, we draw together opinions from industry and academia, and from a variety of related research areas, to present our vision for automatic report generation, and -- critically -- a flexible framework by which such reports can be evaluated. In contrast with other summarization tasks, automatic report generation starts with a detailed description of an information need, stating the necessary background, requirements, and scope of the report. Further, the generated reports should be complete, accurate, and verifiable. These qualities, which are desirable -- if not required -- in many analytic report-writing settings, require rethinking how to build and evaluate systems that exhibit these qualities. To foster new efforts in building these systems, we present an evaluation framework that draws on ideas found in various evaluations. To test completeness and accuracy, the framework uses nuggets of information, expressed as questions and answers, that need to be part of any high-quality generated report. Additionally, evaluation of citations that map claims made in the report to their source documents ensures verifiability.
Read more5/13/2024

0
A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
Read more7/2/2024
💬
0
Large Language Models as Partners in Student Essay Evaluation
Toru Ishida, Tongxi Liu, Hailong Wang, William K. Cheung
As the importance of comprehensive evaluation in workshop courses increases, there is a growing demand for efficient and fair assessment methods that reduce the workload for faculty members. This paper presents an evaluation conducted with Large Language Models (LLMs) using actual student essays in three scenarios: 1) without providing guidance such as rubrics, 2) with pre-specified rubrics, and 3) through pairwise comparison of essays. Quantitative analysis of the results revealed a strong correlation between LLM and faculty member assessments in the pairwise comparison scenario with pre-specified rubrics, although concerns about the quality and stability of evaluations remained. Therefore, we conducted a qualitative analysis of LLM assessment comments, showing that: 1) LLMs can match the assessment capabilities of faculty members, 2) variations in LLM assessments should be interpreted as diversity rather than confusion, and 3) assessments by humans and LLMs can differ and complement each other. In conclusion, this paper suggests that LLMs should not be seen merely as assistants to faculty members but as partners in evaluation committees and outlines directions for further research.
Read more5/30/2024