Interpretability of Language Models via Task Spaces
2406.06441
0
0
Abstract
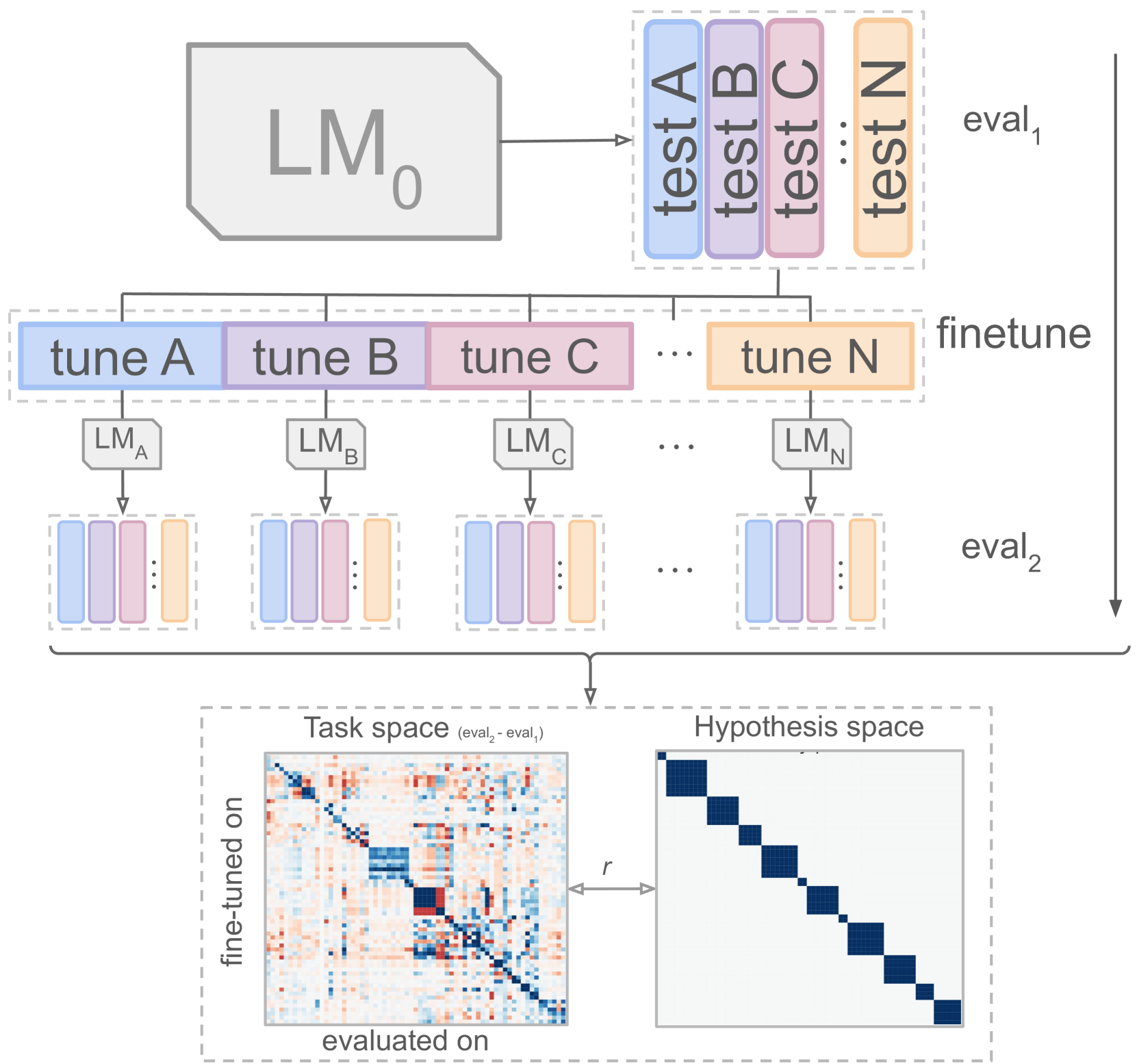
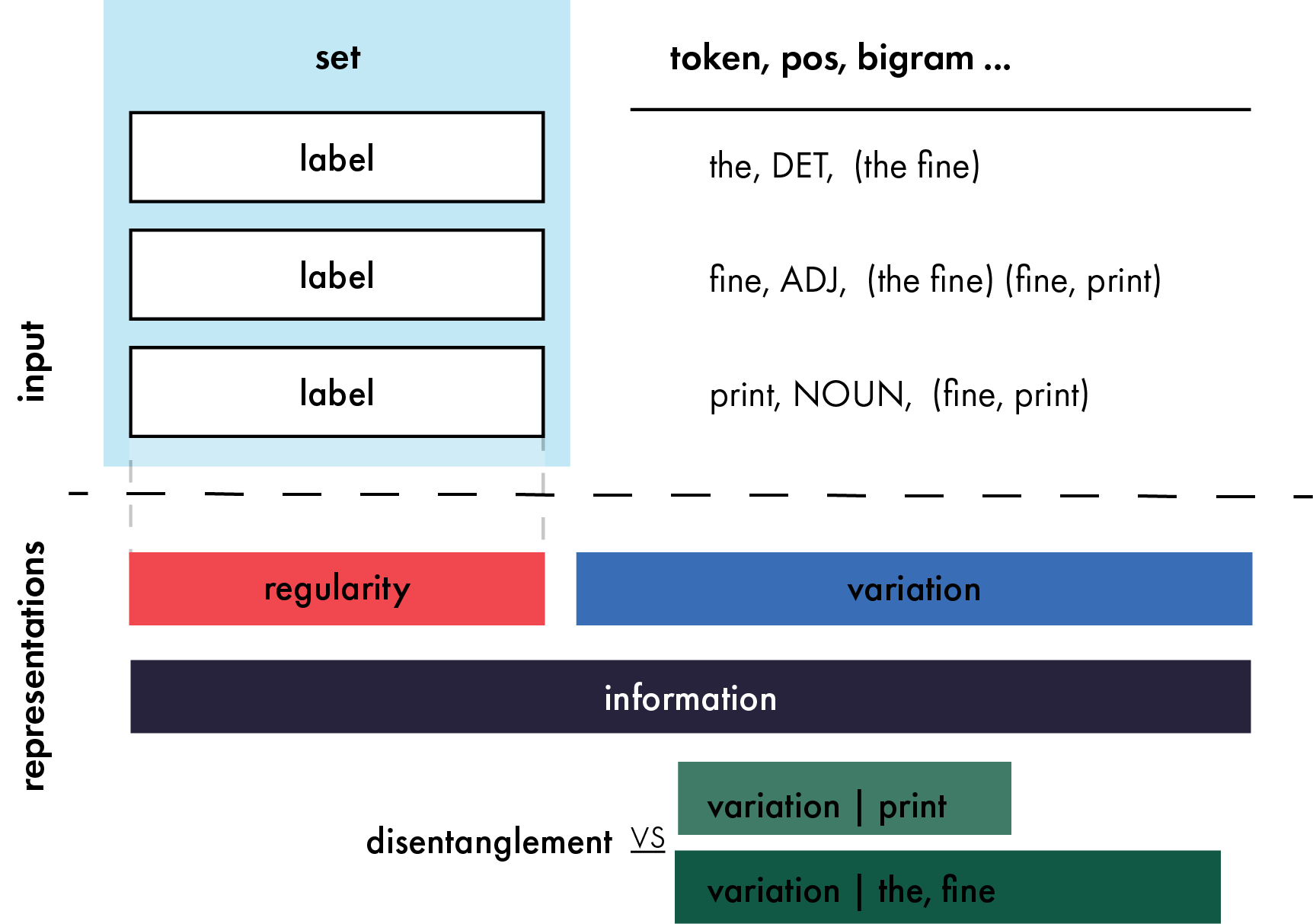
The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
Create account to get full access
Overview
- This paper explores a novel approach to interpreting the internal representations of large language models (LLMs) by framing them in terms of task spaces.
- The researchers propose that the behavior of LLMs can be better understood by analyzing the models' performance on a diverse set of tasks, rather than just examining their raw outputs or internal activations.
- By mapping LLM representations to task spaces, the researchers aim to gain insights into the models' underlying capabilities and limitations, as well as how these capabilities are distributed across different types of tasks.
Plain English Explanation
The paper presents a new way to understand how large language models (LLMs) work under the hood. Instead of just looking at the text the models produce or the internal signals they generate, the researchers suggest that we can learn more by examining how the models perform on a wide variety of tasks.
The key idea is to conceptualize the LLM's "knowledge" in terms of a "task space" - a multidimensional space where each dimension represents a different type of task the model is good or bad at. By mapping the model's performance across this task space, the researchers believe we can gain deeper insights into the model's underlying capabilities and limitations.
For example, an LLM might be great at answering factual questions, but struggle with tasks that require logical reasoning. By understanding this task space profile, we can start to unpack what the model "knows" and how it approaches different types of problems. This could help us design better LLMs in the future, or use existing models more effectively for particular applications.
Technical Explanation
The paper introduces a framework for interpreting LLM representations in terms of task spaces. The key idea is to evaluate an LLM's performance across a diverse set of tasks, and then use this task-level information to gain insights into the model's internal representations and capabilities.
Specifically, the researchers propose:
- Defining a "task space" - a multidimensional space where each dimension corresponds to a particular type of task (e.g. factual question answering, logical reasoning, common sense understanding, etc.).
- Evaluating the LLM's performance on a wide range of tasks that span this task space.
- Mapping the LLM's representations (e.g. activations from intermediate layers) to the task space, allowing them to visualize and analyze how the model's internal knowledge is distributed across different capabilities.
Through extensive experimentation on various LLMs and task sets, the researchers demonstrate that this task space framework can indeed provide valuable interpretability insights. For example, they are able to identify distinct "modes" of LLM behavior, highlighting specialized capabilities, as well as potential blindspots or limitations in the models' knowledge.
Critical Analysis
The task space framework proposed in this paper represents a promising new direction for interpreting and understanding large language models. By moving beyond simple input-output analysis and instead examining the models' performance across a diverse set of tasks, the researchers are able to uncover more nuanced insights about the LLMs' underlying representations and capabilities.
That said, the specific implementation and task set used in this study could be further expanded and refined. The researchers acknowledge that their current task space may not be comprehensive, and that there are likely other important dimensions of LLM behavior that are not captured. Additionally, the reliance on human-curated task sets introduces potential biases and limitations.
Future work could explore more automated or data-driven approaches to constructing the task space, perhaps by leveraging techniques from Representations as Language: An Information-Theoretic Framework for Model Interpretability or Evaluating Spatial Understanding in Large Language Models. There may also be opportunities to combine this task space approach with other interpretability techniques, such as those discussed in Concept Formation and Alignment in Language Models: Bridging the Gap Between Statistical and Symbolic Representations and Ranking Entities along Conceptual Space Dimensions in LLMs.
Overall, this paper represents an important step forward in our understanding of large language models, and the task space framework proposed here could have significant implications for the design, evaluation, and responsible deployment of these powerful AI systems.
Conclusion
The key contribution of this paper is the introduction of a task space framework for interpreting the internal representations of large language models. By evaluating LLM performance across a diverse set of tasks, the researchers are able to map the models' capabilities and limitations in a multidimensional space, providing valuable insights that go beyond simplistic input-output analysis.
This task space approach could have far-reaching implications for the development of more robust, capable, and transparent language models. By better understanding the strengths and weaknesses of current LLMs, researchers and practitioners will be better equipped to design the next generation of AI systems that can reliably and safely handle a wide range of real-world challenges.
Moreover, the task space framework outlined in this paper represents a promising step towards the broader goal of realizing disentanglement in LM latent spaces, which could lead to more interpretable and controllable language models. As AI systems become increasingly influential in our lives, tools like this that enhance our understanding of their inner workings will be crucial for ensuring their responsible development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
0
0
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
6/5/2024
🤔
Evaluating Spatial Understanding of Large Language Models
Yutaro Yamada, Yihan Bao, Andrew K. Lampinen, Jungo Kasai, Ilker Yildirim
0
0
Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. In extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
4/16/2024

Concept Formation and Alignment in Language Models: Bridging Statistical Patterns in Latent Space to Concept Taxonomy
Mehrdad Khatir, Chandan K. Reddy
0
0
This paper explores the concept formation and alignment within the realm of language models (LMs). We propose a mechanism for identifying concepts and their hierarchical organization within the semantic representations learned by various LMs, encompassing a spectrum from early models like Glove to the transformer-based language models like ALBERT and T5. Our approach leverages the inherent structure present in the semantic embeddings generated by these models to extract a taxonomy of concepts and their hierarchical relationships. This investigation sheds light on how LMs develop conceptual understanding and opens doors to further research to improve their ability to reason and leverage real-world knowledge. We further conducted experiments and observed the possibility of isolating these extracted conceptual representations from the reasoning modules of the transformer-based LMs. The observed concept formation along with the isolation of conceptual representations from the reasoning modules can enable targeted token engineering to open the door for potential applications in knowledge transfer, explainable AI, and the development of more modular and conceptually grounded language models.
6/11/2024

Ranking Entities along Conceptual Space Dimensions with LLMs: An Analysis of Fine-Tuning Strategies
Nitesh Kumar, Usashi Chatterjee, Steven Schockaert
0
0
Conceptual spaces represent entities in terms of their primitive semantic features. Such representations are highly valuable but they are notoriously difficult to learn, especially when it comes to modelling perceptual and subjective features. Distilling conceptual spaces from Large Language Models (LLMs) has recently emerged as a promising strategy, but existing work has been limited to probing pre-trained LLMs using relatively simple zero-shot strategies. We focus in particular on the task of ranking entities according to a given conceptual space dimension. Unfortunately, we cannot directly fine-tune LLMs on this task, because ground truth rankings for conceptual space dimensions are rare. We therefore use more readily available features as training data and analyse whether the ranking capabilities of the resulting models transfer to perceptual and subjective features. We find that this is indeed the case, to some extent, but having at least some perceptual and subjective features in the training data seems essential for achieving the best results.
6/6/2024