Interpreting Latent Student Knowledge Representations in Programming Assignments
2405.08213
0
0

Abstract
Recent advances in artificial intelligence for education leverage generative large language models, including using them to predict open-ended student responses rather than their correctness only. However, the black-box nature of these models limits the interpretability of the learned student knowledge representations. In this paper, we conduct a first exploration into interpreting latent student knowledge representations by presenting InfoOIRT, an Information regularized Open-ended Item Response Theory model, which encourages the latent student knowledge states to be interpretable while being able to generate student-written code for open-ended programming questions. InfoOIRT maximizes the mutual information between a fixed subset of latent knowledge states enforced with simple prior distributions and generated student code, which encourages the model to learn disentangled representations of salient syntactic and semantic code features including syntactic styles, mastery of programming skills, and code structures. Through experiments on a real-world programming education dataset, we show that InfoOIRT can both accurately generate student code and lead to interpretable student knowledge representations.
Create account to get full access
Overview
- This paper explores how to interpret the latent representations of student knowledge in programming assignments.
- The researchers developed a model that can capture and interpret the evolving knowledge of students as they work on programming assignments.
- The model provides insights into the different conceptual and procedural knowledge that students develop during the learning process.
Plain English Explanation
The paper is about understanding what students are actually learning when they complete programming assignments. The researchers created a model that can look at the underlying representations of student knowledge as they work through a programming task.
This is important because simply looking at a student's final code or output doesn't tell you much about their actual understanding. The model aims to provide a window into the different types of knowledge students are building, such as conceptual understanding of programming concepts versus the ability to implement specific procedures.
By analyzing these latent representations of student knowledge, the researchers hope to get better insights into the learning process and identify areas where students may be struggling or developing misconceptions. This could help instructors provide more targeted feedback and support to students as they learn to program.
Technical Explanation
The key component of the researchers' approach is a representation learning model that can capture the evolution of student knowledge during a programming assignment. The model takes the students' code submissions as input and learns latent representations that encode both their conceptual understanding and procedural knowledge.
These latent representations are then analyzed to identify different "knowledge states" that students pass through, revealing insights about their learning process. For example, the model may detect when a student has grasped a high-level programming concept but is still struggling with the low-level implementation details.
The researchers tested their approach on a dataset of student programming assignments and found that the latent representations could indeed provide interpretable signals about student knowledge. By comparing the model's outputs to expert annotations, they demonstrated the model's ability to accurately capture the trajectory of student learning.
Critical Analysis
The research presented in this paper is a promising step towards understanding the internal representations of student knowledge in the context of programming assignments. By going beyond just the final product, the model can provide instructors with more nuanced insights into the learning process.
However, the paper does acknowledge some limitations. The dataset used was relatively small, and the analysis focused on a specific programming task. More work is needed to generalize the approach to a wider range of programming assignments and student populations.
Additionally, the paper does not address potential biases or fairness concerns that may arise from using such a model. There is a risk that the model could inadvertently perpetuate or amplify existing disparities in student performance, and further research is needed to ensure the interpretability and explainability of the model's outputs.
Conclusion
This paper presents a novel approach to interpreting the latent representations of student knowledge in programming assignments. By capturing the evolution of conceptual and procedural knowledge, the model provides a more nuanced understanding of the learning process than traditional assessment methods.
While the research shows promise, there are still opportunities to expand and refine the approach to make it more robust and generalizable. Nonetheless, this work represents an important step towards leveraging AI and representation learning to improve our understanding of how students learn to program and how we can better support their development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
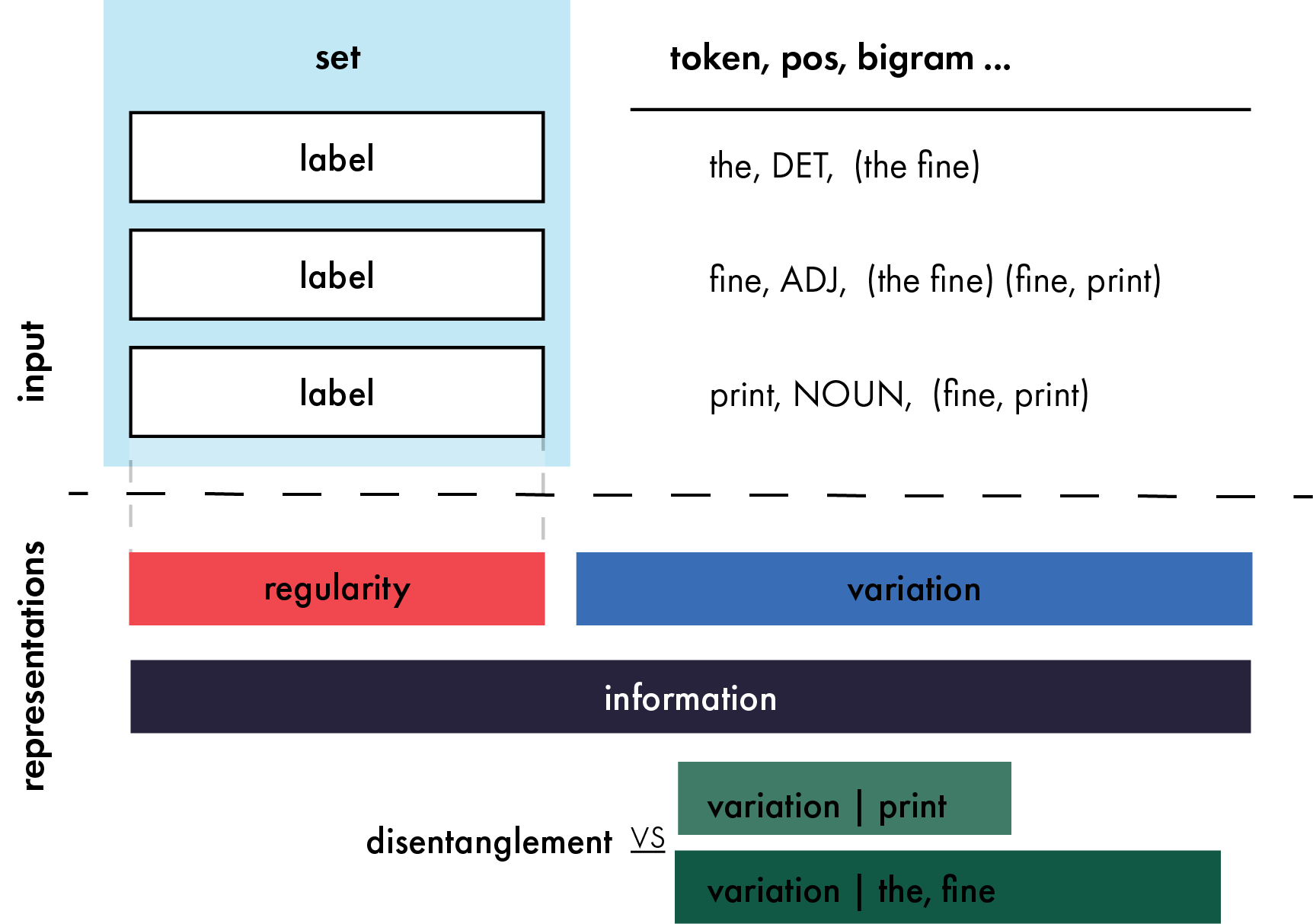
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
0
0
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
6/5/2024
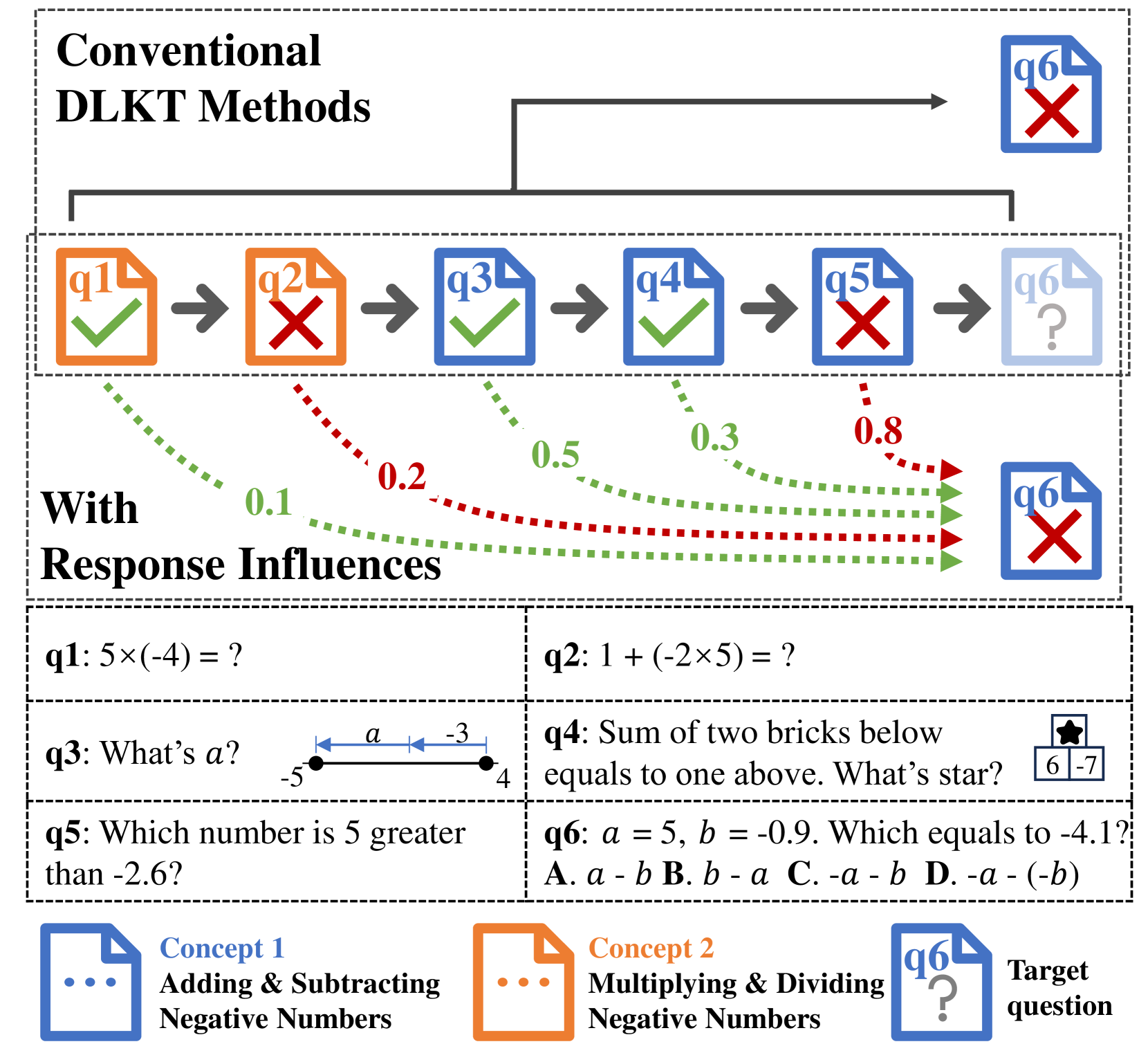
Interpretable Knowledge Tracing via Response Influence-based Counterfactual Reasoning
Jiajun Cui, Minghe Yu, Bo Jiang, Aimin Zhou, Jianyong Wang, Wei Zhang
0
0
Knowledge tracing (KT) plays a crucial role in computer-aided education and intelligent tutoring systems, aiming to assess students' knowledge proficiency by predicting their future performance on new questions based on their past response records. While existing deep learning knowledge tracing (DLKT) methods have significantly improved prediction accuracy and achieved state-of-the-art results, they often suffer from a lack of interpretability. To address this limitation, current approaches have explored incorporating psychological influences to achieve more explainable predictions, but they tend to overlook the potential influences of historical responses. In fact, understanding how models make predictions based on response influences can enhance the transparency and trustworthiness of the knowledge tracing process, presenting an opportunity for a new paradigm of interpretable KT. However, measuring unobservable response influences is challenging. In this paper, we resort to counterfactual reasoning that intervenes in each response to answer textit{what if a student had answered a question incorrectly that he/she actually answered correctly, and vice versa}. Based on this, we propose RCKT, a novel response influence-based counterfactual knowledge tracing framework. RCKT generates response influences by comparing prediction outcomes from factual sequences and constructed counterfactual sequences after interventions. Additionally, we introduce maximization and inference techniques to leverage accumulated influences from different past responses, further improving the model's performance and credibility. Extensive experimental results demonstrate that our RCKT method outperforms state-of-the-art knowledge tracing methods on four datasets against six baselines, and provides credible interpretations of response influences.
6/3/2024
IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators
Indraneil Paul, Goran Glavav{s}, Iryna Gurevych
0
0
Code understanding and generation have fast become some of the most popular applications of language models (LMs). Nonetheless, research on multilingual aspects of Code-LMs (i.e., LMs for code generation) such as cross-lingual transfer between different programming languages, language-specific data augmentation, and post-hoc LM adaptation, alongside exploitation of data sources other than the original textual content, has been much sparser than for their natural language counterparts. In particular, most mainstream Code-LMs have been pre-trained on source code files alone. In this work, we investigate the prospect of leveraging readily available compiler intermediate representations (IR) - shared across programming languages - to improve the multilingual capabilities of Code-LMs and facilitate cross-lingual transfer. To this end, we first compile SLTrans, a parallel dataset consisting of nearly 4M self-contained source code files coupled with respective intermediate representations. Next, starting from various base Code-LMs (ranging in size from 1.1B to 7.3B parameters), we carry out continued causal language modelling training on SLTrans, forcing the Code-LMs to (1) learn the IR language and (2) align the IR constructs with respective constructs of various programming languages. Our resulting models, dubbed IRCoder, display sizeable and consistent gains across a wide variety of code generation tasks and metrics, including prompt robustness, multilingual code completion, code understanding, and instruction following.
4/16/2024
🖼️
I've got the Answer! Interpretation of LLMs Hidden States in Question Answering
Valeriya Goloviznina, Evgeny Kotelnikov
0
0
Interpretability and explainability of AI are becoming increasingly important in light of the rapid development of large language models (LLMs). This paper investigates the interpretation of LLMs in the context of the knowledge-based question answering. The main hypothesis of the study is that correct and incorrect model behavior can be distinguished at the level of hidden states. The quantized models LLaMA-2-7B-Chat, Mistral-7B, Vicuna-7B and the MuSeRC question-answering dataset are used to test this hypothesis. The results of the analysis support the proposed hypothesis. We also identify the layers which have a negative effect on the model's behavior. As a prospect of practical application of the hypothesis, we propose to train such weak layers additionally in order to improve the quality of the task solution.
6/5/2024