Representing Animatable Avatar via Factorized Neural Fields
2406.00637
0
0
🧠
Abstract
For reconstructing high-fidelity human 3D models from monocular videos, it is crucial to maintain consistent large-scale body shapes along with finely matched subtle wrinkles. This paper explores the observation that the per-frame rendering results can be factorized into a pose-independent component and a corresponding pose-dependent equivalent to facilitate frame consistency. Pose adaptive textures can be further improved by restricting frequency bands of these two components. In detail, pose-independent outputs are expected to be low-frequency, while highfrequency information is linked to pose-dependent factors. We achieve a coherent preservation of both coarse body contours across the entire input video and finegrained texture features that are time variant with a dual-branch network with distinct frequency components. The first branch takes coordinates in canonical space as input, while the second branch additionally considers features outputted by the first branch and pose information of each frame. Our network integrates the information predicted by both branches and utilizes volume rendering to generate photo-realistic 3D human images. Through experiments, we demonstrate that our network surpasses the neural radiance fields (NeRF) based state-of-the-art methods in preserving high-frequency details and ensuring consistent body contours.
Create account to get full access
Overview
- This paper explores a method for reconstructing high-fidelity 3D human models from monocular videos, with the goal of maintaining consistent large-scale body shapes and fine-grained texture details.
- The key idea is to factorize the per-frame rendering results into a pose-independent component and a pose-dependent component, which can be further optimized to preserve both coarse body contours and fine-grained texture features.
- The proposed network integrates information from two branches - one that takes coordinates in canonical space as input, and another that considers pose information - to generate photo-realistic 3D human images using volume rendering.
Plain English Explanation
The researchers wanted to create realistic 3D models of humans from regular video footage. This is a challenging task because the 3D shape and texture of a person can change a lot depending on their pose. The researchers found a way to split the video information into two parts: one part that describes the overall body shape, which doesn't change much between frames, and another part that describes the finer details of the texture, which can change a lot with the person's pose.
By separating these two components, the researchers were able to better preserve both the large-scale body contours and the small-scale texture details in the final 3D model. Their network takes in the video footage and uses this two-part representation to generate a 3D human model that looks very realistic and true to the original person.
This approach outperforms previous methods, like NeRF, in maintaining consistent body shapes and fine details across the entire video.
Technical Explanation
The key technical innovation in this paper is the use of a dual-branch network architecture to factorize the per-frame rendering results. The first branch takes coordinates in a canonical space as input, which captures the pose-independent, low-frequency component of the 3D human model. The second branch considers both the output of the first branch and the pose information of the current frame, allowing it to model the high-frequency, pose-dependent texture details.
By restricting the frequency bands of these two components, the network can better preserve both the coarse body contours and the fine-grained texture features in the final 3D reconstruction. The network integrates the information from both branches and uses volume rendering to generate the photo-realistic 3D human images.
Through extensive experiments, the authors demonstrate that their approach surpasses the NeRF-based state-of-the-art methods in terms of preserving high-frequency details and ensuring consistent body contours across the entire input video.
Critical Analysis
The paper presents a promising approach for reconstructing high-fidelity 3D human models from monocular videos. The key strength of the method is its ability to maintain coherent large-scale body shapes and fine-grained texture details, which is a crucial requirement for many applications, such as animatable and relightable human avatars.
However, the paper does not explore the limitations of the proposed method, such as its performance on challenging scenarios, like rapid movements or occluded body parts. Additionally, the paper does not provide a detailed analysis of the computational complexity and real-time performance of the method, which are important factors for practical deployment.
Further research could investigate the generalization capabilities of the method to handle a wider range of body shapes, clothing, and lighting conditions. Exploring the integration of the proposed factorization approach with other human modeling techniques could also lead to interesting advancements in the field.
Conclusion
This paper presents a novel approach for reconstructing high-fidelity 3D human models from monocular videos, which outperforms the state-of-the-art NeRF-based methods in preserving both coarse body contours and fine-grained texture details. By factorizing the per-frame rendering results into pose-independent and pose-dependent components, the method can generate consistent and realistic 3D human avatars, with significant implications for various applications, such as virtual reality, gaming, and entertainment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Animatable and Relightable Gaussians for High-fidelity Human Avatar Modeling
Zhe Li, Yipengjing Sun, Zerong Zheng, Lizhen Wang, Shengping Zhang, Yebin Liu
0
0
Modeling animatable human avatars from RGB videos is a long-standing and challenging problem. Recent works usually adopt MLP-based neural radiance fields (NeRF) to represent 3D humans, but it remains difficult for pure MLPs to regress pose-dependent garment details. To this end, we introduce Animatable Gaussians, a new avatar representation that leverages powerful 2D CNNs and 3D Gaussian splatting to create high-fidelity avatars. To associate 3D Gaussians with the animatable avatar, we learn a parametric template from the input videos, and then parameterize the template on two front & back canonical Gaussian maps where each pixel represents a 3D Gaussian. The learned template is adaptive to the wearing garments for modeling looser clothes like dresses. Such template-guided 2D parameterization enables us to employ a powerful StyleGAN-based CNN to learn the pose-dependent Gaussian maps for modeling detailed dynamic appearances. Furthermore, we introduce a pose projection strategy for better generalization given novel poses. To tackle the realistic relighting of animatable avatars, we introduce physically-based rendering into the avatar representation for decomposing avatar materials and environment illumination. Overall, our method can create lifelike avatars with dynamic, realistic, generalized and relightable appearances. Experiments show that our method outperforms other state-of-the-art approaches.
5/28/2024
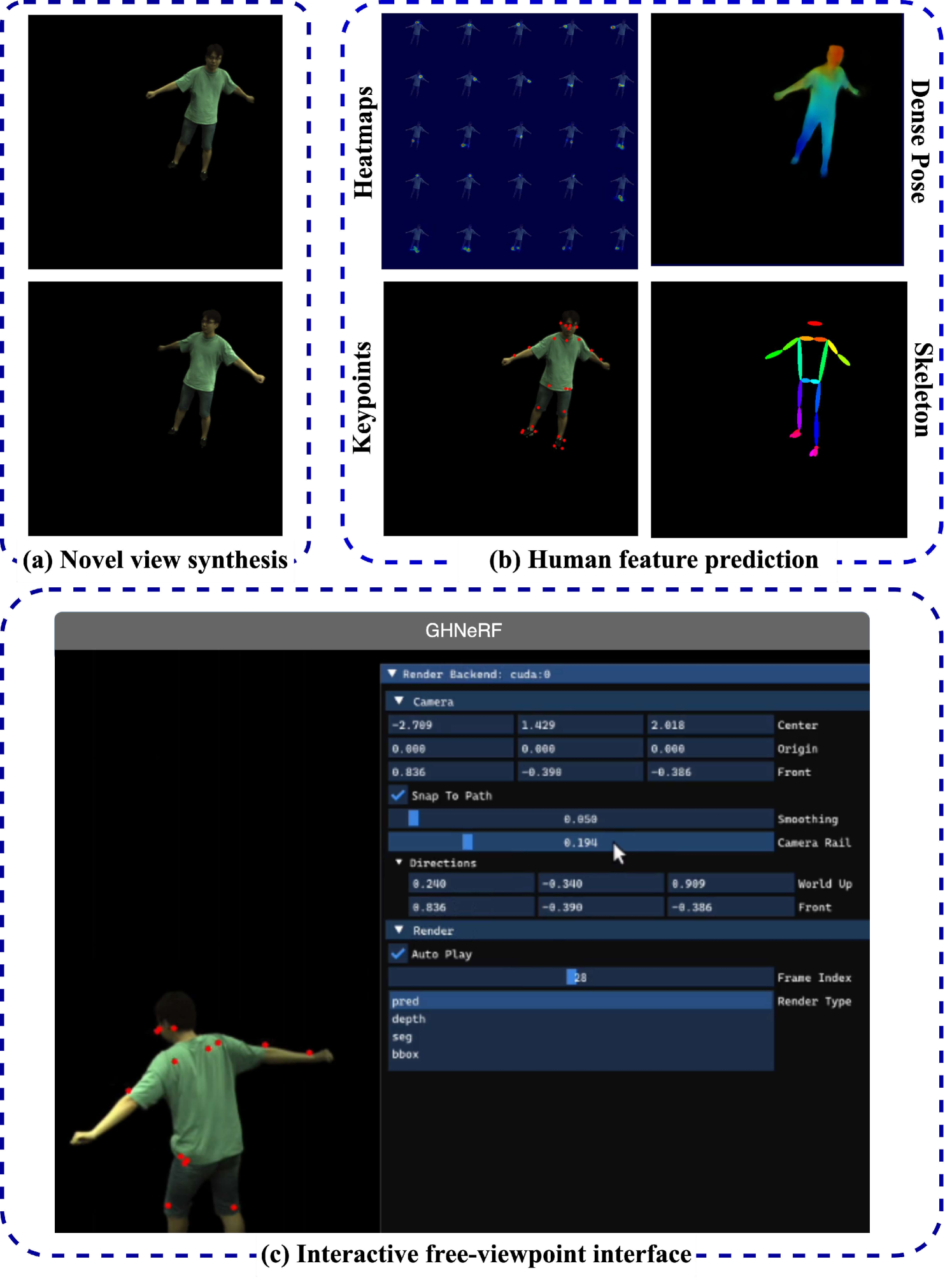
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Arnab Dey, Di Yang, Rohith Agaram, Antitza Dantcheva, Andrew I. Comport, Srinath Sridhar, Jean Martinet
0
0
Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
4/10/2024

HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields
Arnab Dey, Di Yang, Antitza Dantcheva, Jean Martinet
0
0
In recent advancements in novel view synthesis, generalizable Neural Radiance Fields (NeRF) based methods applied to human subjects have shown remarkable results in generating novel views from few images. However, this generalization ability cannot capture the underlying structural features of the skeleton shared across all instances. Building upon this, we introduce HFNeRF: a novel generalizable human feature NeRF aimed at generating human biomechanic features using a pre-trained image encoder. While previous human NeRF methods have shown promising results in the generation of photorealistic virtual avatars, such methods lack underlying human structure or biomechanic features such as skeleton or joint information that are crucial for downstream applications including Augmented Reality (AR)/Virtual Reality (VR). HFNeRF leverages 2D pre-trained foundation models toward learning human features in 3D using neural rendering, and then volume rendering towards generating 2D feature maps. We evaluate HFNeRF in the skeleton estimation task by predicting heatmaps as features. The proposed method is fully differentiable, allowing to successfully learn color, geometry, and human skeleton in a simultaneous manner. This paper presents preliminary results of HFNeRF, illustrating its potential in generating realistic virtual avatars with biomechanic features using NeRF.
4/10/2024
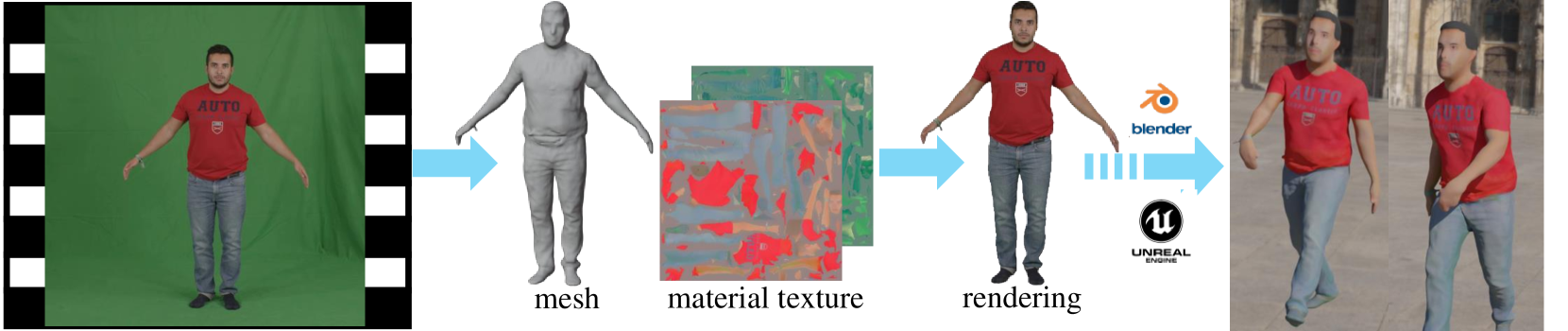
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
0
0
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
5/21/2024