Resampled Datasets Are Not Enough: Mitigating Societal Bias Beyond Single Attributes

0

Sign in to get full access
Overview
- The paper discusses the limitations of resampling datasets to mitigate societal biases in machine learning models
- It proposes a framework to identify and mitigate intersectional biases that arise from multiple, interacting attributes
- The approach involves probing models for biases and then using counterfactual reasoning to understand and correct these biases
Plain English Explanation
Machine learning models can sometimes reflect and amplify societal biases present in the data they are trained on. A common approach to address this is to resample the dataset to better represent underrepresented groups. However, this paper argues that resampling alone is not enough to fully mitigate biases, especially those that arise from the interaction of multiple attributes (e.g. gender and race).
The authors propose a framework to probe models for intersectional biases - biases that stem from the combination of multiple demographic factors. By using counterfactual reasoning, they can better understand how these complex biases manifest and then take steps to mitigate them.
This is an important advancement because many real-world applications of machine learning, such as image recognition, involve intersectional biases that are difficult to address through simple resampling techniques. The authors' framework provides a more systematic way to identify and address these subtle but pervasive biases.
Technical Explanation
The paper first reviews related work on dataset resampling and bias mitigation techniques. It then introduces a framework for probing models for intersectional biases using counterfactual reasoning.
The key steps are:
- Model Probing: Analyze the model's predictions on a diverse set of samples, including those representing different intersections of attributes (e.g. race and gender).
- Causal Reasoning: Use counterfactual analysis to identify which specific attribute combinations are driving biased predictions.
- Bias Mitigation: Develop targeted interventions to debias the model, such as adjusting training data or applying model-agnostic data attribution.
The authors demonstrate the effectiveness of their framework on several benchmark datasets, showing that it can uncover and mitigate biases that simple resampling techniques miss.
Critical Analysis
The paper makes a compelling case that resampling datasets alone is insufficient for addressing the complex, intersectional biases that can arise in machine learning models. By using counterfactual reasoning to probe for these more nuanced biases, the authors' framework represents an important advancement in bias mitigation.
However, the paper does not address the potential difficulty and scalability of the proposed approach. Probing models for intersectional biases may be computationally intensive, especially as the number of attributes increases. Additionally, developing targeted debiasing interventions could be challenging and require significant domain expertise.
Further research is needed to explore more efficient and automated methods for identifying and mitigating intersectional biases. The authors also acknowledge that their framework does not address all possible sources of bias, such as dataset bias or model architecture bias. A more holistic approach to bias mitigation may be necessary to ensure the fairness and robustness of machine learning systems.
Conclusion
This paper highlights the limitations of resampling datasets as a sole strategy for mitigating societal biases in machine learning. It proposes a framework that uses counterfactual reasoning to uncover and address more complex, intersectional biases. This is an important step forward, as many real-world applications of AI involve these types of subtle but impactful biases.
While the proposed approach shows promise, further research is needed to address the scalability and generalizability of the framework. Addressing intersectional biases is a crucial challenge for the AI community, and this paper contributes a valuable new tool to the growing arsenal of bias mitigation techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Resampled Datasets Are Not Enough: Mitigating Societal Bias Beyond Single Attributes
Yusuke Hirota, Jerone T. A. Andrews, Dora Zhao, Orestis Papakyriakopoulos, Apostolos Modas, Yuta Nakashima, Alice Xiang
We tackle societal bias in image-text datasets by removing spurious correlations between protected groups and image attributes. Traditional methods only target labeled attributes, ignoring biases from unlabeled ones. Using text-guided inpainting models, our approach ensures protected group independence from all attributes and mitigates inpainting biases through data filtering. Evaluations on multi-label image classification and image captioning tasks show our method effectively reduces bias without compromising performance across various models.
Read more7/12/2024
0
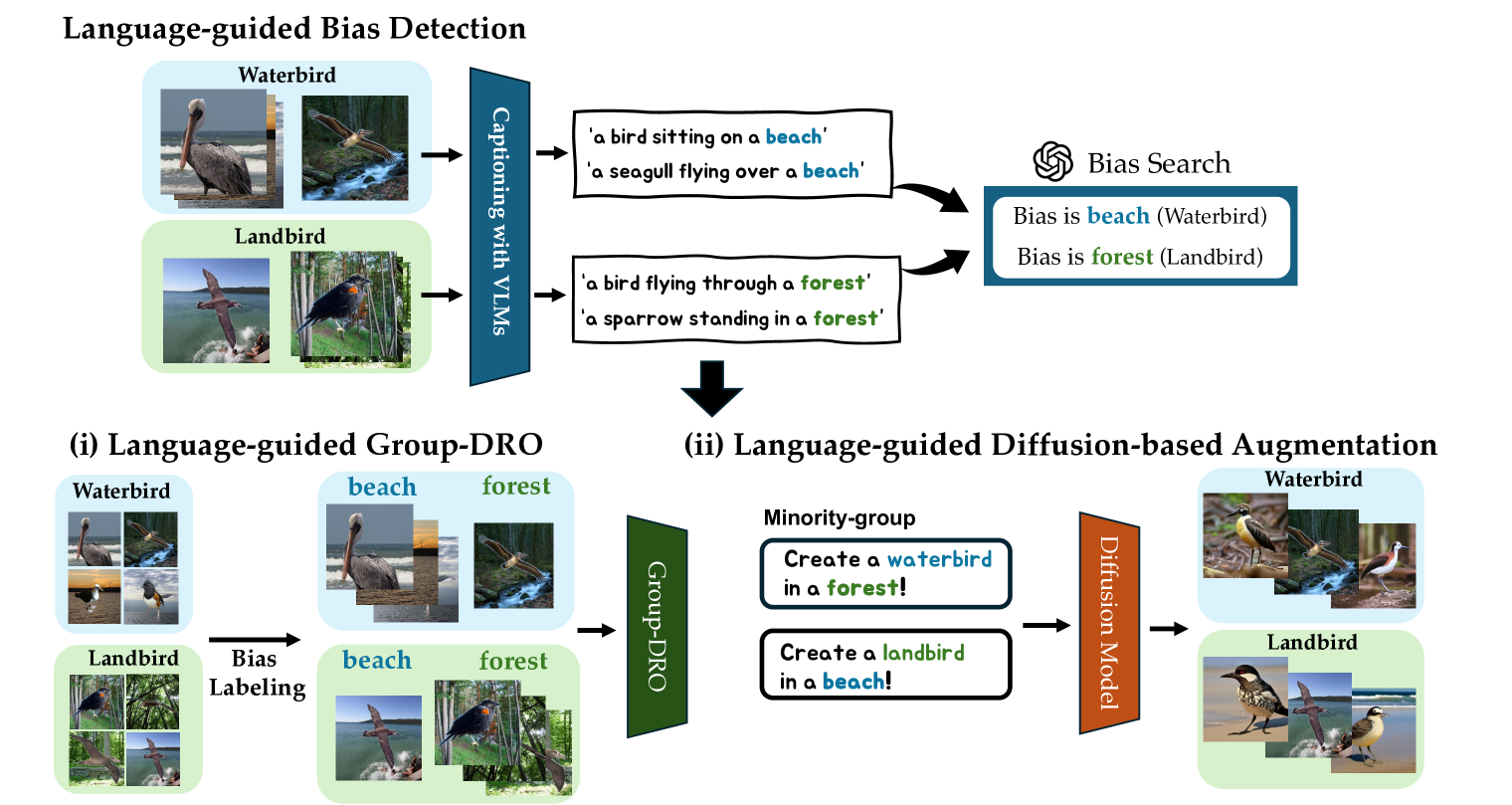
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Read more6/6/2024

0
Measuring and Mitigating Bias for Tabular Datasets with Multiple Protected Attributes
Manh Khoi Duong, Stefan Conrad
Motivated by the recital (67) of the current corrigendum of the AI Act in the European Union, we propose and present measures and mitigation strategies for discrimination in tabular datasets. We specifically focus on datasets that contain multiple protected attributes, such as nationality, age, and sex. This makes measuring and mitigating bias more challenging, as many existing methods are designed for a single protected attribute. This paper comes with a twofold contribution: Firstly, new discrimination measures are introduced. These measures are categorized in our framework along with existing ones, guiding researchers and practitioners in choosing the right measure to assess the fairness of the underlying dataset. Secondly, a novel application of an existing bias mitigation method, FairDo, is presented. We show that this strategy can mitigate any type of discrimination, including intersectional discrimination, by transforming the dataset. By conducting experiments on real-world datasets (Adult, Bank, Compas), we demonstrate that de-biasing datasets with multiple protected attributes is achievable. Further, the transformed fair datasets do not compromise any of the tested machine learning models' performances significantly when trained on these datasets compared to the original datasets. Discrimination was reduced by up to 83% in our experimentation. For most experiments, the disparity between protected groups was reduced by at least 7% and 27% on average. Generally, the findings show that the mitigation strategy used is effective, and this study contributes to the ongoing discussion on the implementation of the European Union's AI Act.
Read more5/30/2024
📊
0
Mitigating Bias Using Model-Agnostic Data Attribution
Sander De Coninck, Wei-Cheng Wang, Sam Leroux, Pieter Simoens
Mitigating bias in machine learning models is a critical endeavor for ensuring fairness and equity. In this paper, we propose a novel approach to address bias by leveraging pixel image attributions to identify and regularize regions of images containing significant information about bias attributes. Our method utilizes a model-agnostic approach to extract pixel attributions by employing a convolutional neural network (CNN) classifier trained on small image patches. By training the classifier to predict a property of the entire image using only a single patch, we achieve region-based attributions that provide insights into the distribution of important information across the image. We propose utilizing these attributions to introduce targeted noise into datasets with confounding attributes that bias the data, thereby constraining neural networks from learning these biases and emphasizing the primary attributes. Our approach demonstrates its efficacy in enabling the training of unbiased classifiers on heavily biased datasets.
Read more5/9/2024