Research on color recipe recommendation based on unstructured data using TENN

0

Sign in to get full access
Overview
- This paper presents a technique for recommending color recipes based on unstructured data using a novel neural network architecture called TENN.
- The proposed method leverages TENN to efficiently extract and integrate relevant color information from diverse, unstructured data sources.
- The researchers evaluate the effectiveness of their approach on a real-world color recipe dataset and demonstrate its superiority over existing methods.
Plain English Explanation
The paper describes a new way to recommend color recipes using machine learning. Traditionally, color recipe recommendations have relied on structured data, like paint formulas. But this new approach can work with unstructured data, such as images, text descriptions, and other sources that don't have a clear, organized format.
The key to this is a special type of neural network called TENN, which can effectively extract and combine relevant color information from these diverse, unstructured sources. This allows the system to make more informed and useful color recipe recommendations.
The researchers tested their TENN-based approach on a real-world dataset of color recipes and found that it outperformed existing methods. This suggests the TENN architecture could be a valuable tool for color recommendation systems that need to work with a wide variety of information sources.
Technical Explanation
The paper introduces a deep learning-based approach for color recipe recommendation using a novel neural network architecture called TENN (Transformer-Encoder-Neural-Network).
The TENN model is designed to effectively extract and integrate relevant color information from diverse, unstructured data sources, such as images, text descriptions, and other formats that lack a clear, structured format. This is achieved through the use of a transformer-based encoder that can capture complex relationships within the input data, combined with a neural network that learns to map this encoded information to appropriate color recipes.
To evaluate the proposed approach, the researchers conducted experiments on a real-world color recipe dataset. They compared the performance of their TENN-based method to existing techniques and found that it consistently outperformed the alternatives in terms of recommendation accuracy and other relevant metrics.
Critical Analysis
The paper presents a novel and promising approach for color recipe recommendation that effectively leverages unstructured data sources. The use of the TENN architecture is a key contribution, as it allows the system to handle the complexity and diversity of the input data in a robust manner.
However, the paper does not address some potential limitations of the proposed method. For example, it is unclear how the TENN model would perform on edge cases or noisy data, or how it might scale to larger and more diverse datasets. Additionally, the paper does not provide a detailed analysis of the computational complexity and training requirements of the TENN architecture, which could be important considerations for real-world deployments.
Further research could explore ways to improve the interpretability of the TENN model, allowing users to better understand the reasoning behind the color recommendations. Incorporating user feedback and preferences into the model could also be an interesting avenue for future work, enhancing the personalization and relevance of the recommendations.
Conclusion
This paper introduces a novel TENN-based approach for color recipe recommendation that can effectively leverage unstructured data sources, such as images and text descriptions. The researchers demonstrate the effectiveness of their method through experiments on a real-world dataset, showcasing its superior performance compared to existing techniques.
The TENN architecture's ability to extract and integrate relevant color information from diverse, unstructured inputs is a significant contribution, with potential applications in color recommendation systems and beyond. Further research could explore ways to improve the model's interpretability, personalization, and scalability, ultimately enhancing the practical utility of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Research on color recipe recommendation based on unstructured data using TENN
Seongsu Jhang, Donghwi Yoo, Jaeyong Kown
Recently, services and business models based on large language models, such as OpenAI Chatgpt, Google BARD, and Microsoft copilot, have been introduced, and the applications utilizing natural language processing with deep learning are increasing, and it is one of the natural language preprocessing methods. Conversion to machine language through tokenization and processing of unstructured data are increasing. Although algorithms that can understand and apply human language are becoming increasingly sophisticated, it is difficult to apply them to processes that rely on human emotions and senses in industries that still mainly deal with standardized data. In particular, in processes where brightness, saturation, and color information are essential, such as painting and injection molding, most small and medium-sized companies, excluding large corporations, rely on the tacit knowledge and sensibility of color mixers, and even customer companies often present non-standardized requirements. . In this paper, we proposed TENN to infer color recipe based on unstructured data with emotional natural language, and demonstrated it.
Read more8/20/2024

0
Large Language Models estimate fine-grained human color-concept associations
Kushin Mukherjee, Timothy T. Rogers, Karen B. Schloss
Concepts, both abstract and concrete, elicit a distribution of association strengths across perceptual color space, which influence aspects of visual cognition ranging from object recognition to interpretation of information visualizations. While prior work has hypothesized that color-concept associations may be learned from the cross-modal statistical structure of experience, it has been unclear whether natural environments possess such structure or, if so, whether learning systems are capable of discovering and exploiting it without strong prior constraints. We addressed these questions by investigating the ability of GPT-4, a multimodal large language model, to estimate human-like color-concept associations without any additional training. Starting with human color-concept association ratings for 71 color set spanning perceptual color space (texttt{UW-71}) and concepts that varied in abstractness, we assessed how well association ratings generated by GPT-4 could predict human ratings. GPT-4 ratings were correlated with human ratings, with performance comparable to state-of-the-art methods for automatically estimating color-concept associations from images. Variability in GPT-4's performance across concepts could be explained by specificity of the concept's color-concept association distribution. This study suggests that high-order covariances between language and perception, as expressed in the natural environment of the internet, contain sufficient information to support learning of human-like color-concept associations, and provides an existence proof that a learning system can encode such associations without initial constraints. The work further shows that GPT-4 can be used to efficiently estimate distributions of color associations for a broad range of concepts, potentially serving as a critical tool for designing effective and intuitive information visualizations.
Read more6/27/2024

0
ColorPeel: Color Prompt Learning with Diffusion Models via Color and Shape Disentanglement
Muhammad Atif Butt, Kai Wang, Javier Vazquez-Corral, Joost van de Weijer
Text-to-Image (T2I) generation has made significant advancements with the advent of diffusion models. These models exhibit remarkable abilities to produce images based on textual prompts. Current T2I models allow users to specify object colors using linguistic color names. However, these labels encompass broad color ranges, making it difficult to achieve precise color matching. To tackle this challenging task, named color prompt learning, we propose to learn specific color prompts tailored to user-selected colors. Existing T2I personalization methods tend to result in color-shape entanglement. To overcome this, we generate several basic geometric objects in the target color, allowing for color and shape disentanglement during the color prompt learning. Our method, denoted as ColorPeel, successfully assists the T2I models to peel off the novel color prompts from these colored shapes. In the experiments, we demonstrate the efficacy of ColorPeel in achieving precise color generation with T2I models. Furthermore, we generalize ColorPeel to effectively learn abstract attribute concepts, including textures, materials, etc. Our findings represent a significant step towards improving precision and versatility of T2I models, offering new opportunities for creative applications and design tasks. Our project is available at https://moatifbutt.github.io/colorpeel/.
Read more7/11/2024
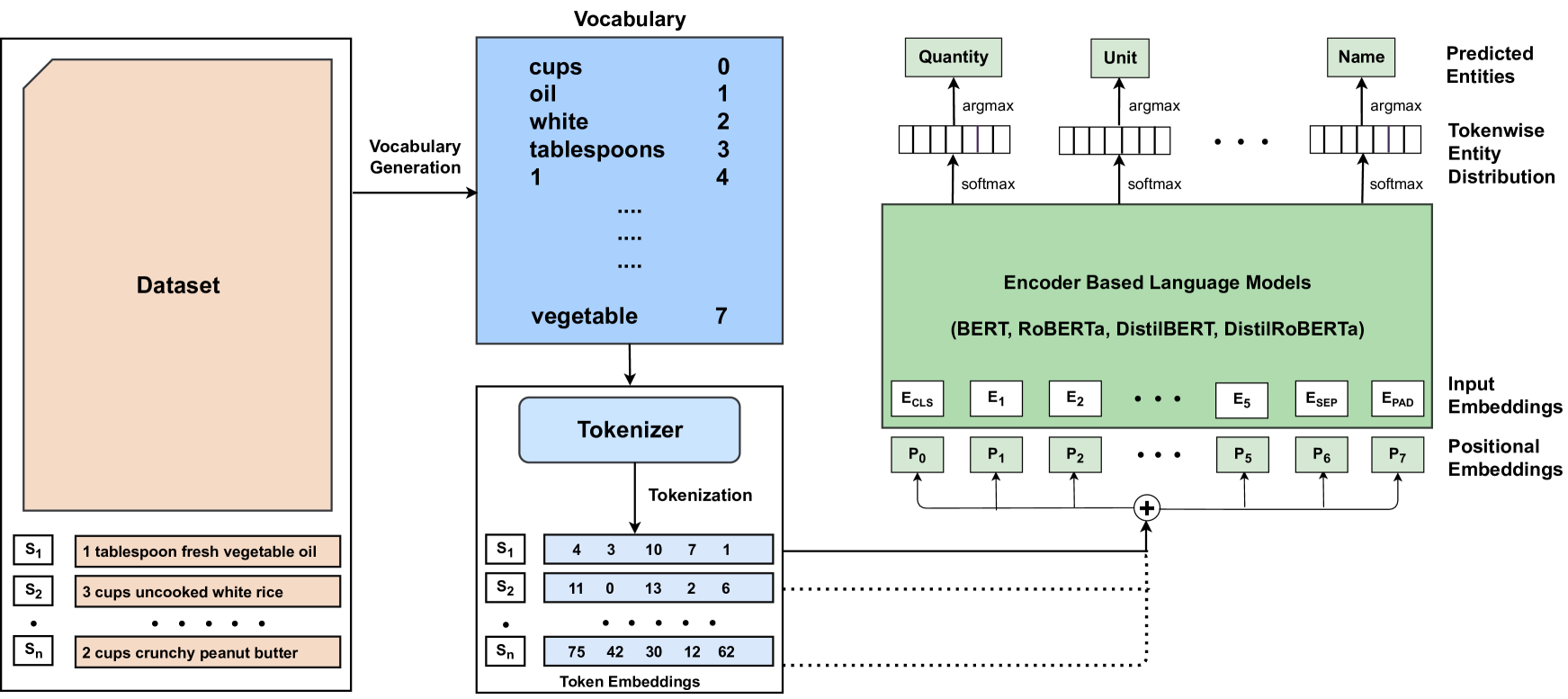
0
Deep Learning Based Named Entity Recognition Models for Recipes
Mansi Goel, Ayush Agarwal, Shubham Agrawal, Janak Kapuriya, Akhil Vamshi Konam, Rishabh Gupta, Shrey Rastogi, Niharika, Ganesh Bagler
Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.
Read more6/7/2024