Residual Connections and Normalization Can Provably Prevent Oversmoothing in GNNs

0

Sign in to get full access
Overview
- This paper investigates the issue of oversmoothing in Graph Neural Networks (GNNs) and proposes a solution using residual connections and normalization.
- Oversmoothing is a problem where repeated message passing in GNNs can lead to node representations becoming indistinguishable, reducing the model's performance.
- The authors show that using residual connections and normalization can provably prevent oversmoothing and improve the model's performance.
Plain English Explanation
Graph Neural Networks (GNNs) are a type of machine learning model that can work with data represented as graphs, where the data points are connected to each other in a network. GNNs work by passing "messages" between connected nodes, which can lead to a problem called "oversmoothing."
Oversmoothing happens when the repeated message passing causes the node representations (the way the model represents each data point) to become too similar to each other, to the point where the model can't tell them apart anymore. This reduces the model's ability to make accurate predictions.
The researchers in this paper found a way to solve the oversmoothing problem by using two key techniques: residual connections and normalization. Residual connections allow the model to "skip" some of the message passing, which prevents the representations from becoming too smooth. Normalization helps keep the node representations within a certain range, also preventing them from becoming too similar.
The authors were able to mathematically prove that using these techniques can effectively prevent oversmoothing in GNNs, improving the model's performance on various tasks. This is an important finding, as oversmoothing has been a significant challenge for GNNs, and this solution provides a way to address it.
Technical Explanation
The paper starts by introducing the problem of oversmoothing in Graph Neural Networks (GNNs). Oversmoothing occurs when the repeated message passing in GNNs causes the node representations to become indistinguishable, leading to a decrease in the model's performance.
The authors then propose two key techniques to address this issue: residual connections and normalization. Residual connections allow the model to "skip" some of the message passing, preventing the node representations from becoming too smooth. Normalization, such as layer normalization, helps keep the node representations within a certain range, further preventing oversmoothing.
The paper provides a formal analysis to show that using residual connections and normalization can provably prevent oversmoothing in GNNs. The authors prove that these techniques can maintain the distinguishability of node representations, even as the number of message passing steps increases.
To validate their approach, the researchers conduct experiments on various graph benchmarks, including citation networks and molecular graphs. The results show that the proposed model with residual connections and normalization outperforms standard GNN architectures, especially in deeper models where oversmoothing is more prevalent.
Critical Analysis
The paper presents a compelling solution to the oversmoothing problem in GNNs, with a strong theoretical foundation and experimental validation. The use of residual connections and normalization is a well-established approach in other deep learning models, and the authors have demonstrated its effectiveness in the context of GNNs.
One potential limitation of the research is that it focuses on a specific set of graph benchmarks, and the generalization of the findings to other types of graph data and tasks may require further investigation. Additionally, while the paper provides a theoretical analysis of the proposed techniques, there may be other factors that contribute to oversmoothing in real-world scenarios that are not fully captured in the analysis.
Furthermore, the paper does not explore the computational and memory overhead of the residual connections and normalization layers, which could be an important consideration for the practical deployment of the proposed model, especially in resource-constrained environments.
Overall, this paper makes an important contribution to the field of Graph Neural Networks by addressing the significant challenge of oversmoothing. The proposed solution using residual connections and normalization is a valuable addition to the toolbox of GNN researchers and practitioners, and it opens up new avenues for further exploration and improvement of these powerful models.
Conclusion
This paper presents a novel solution to the problem of oversmoothing in Graph Neural Networks (GNNs) using residual connections and normalization. The authors provide a formal analysis to show that these techniques can provably prevent the node representations from becoming indistinguishable, a key issue that has hindered the performance of GNNs.
The experimental results demonstrate the effectiveness of the proposed approach, which outperforms standard GNN architectures, especially in deeper models where oversmoothing is more prevalent. This work contributes to the ongoing efforts to improve the robustness and reliability of Graph Neural Networks, which have shown great potential in a wide range of applications, from social network analysis to molecular modeling.
By addressing the oversmoothing problem, this research paves the way for more powerful and versatile GNN models that can better capture the complex relationships and structures in graph-structured data. As the field of Graph Neural Networks continues to evolve, this paper provides an important step forward, offering a practical and theoretically grounded solution to a key challenge in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Residual Connections and Normalization Can Provably Prevent Oversmoothing in GNNs
Michael Scholkemper, Xinyi Wu, Ali Jadbabaie, Michael T. Schaub
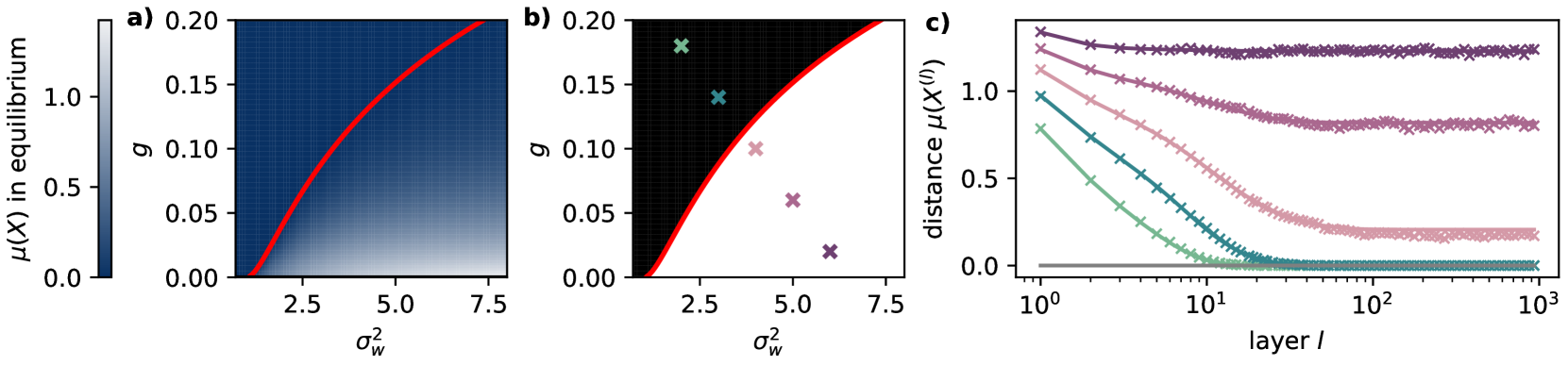
Residual connections and normalization layers have become standard design choices for graph neural networks (GNNs), and were proposed as solutions to the mitigate the oversmoothing problem in GNNs. However, how exactly these methods help alleviate the oversmoothing problem from a theoretical perspective is not well understood. In this work, we provide a formal and precise characterization of (linearized) GNNs with residual connections and normalization layers. We establish that (a) for residual connections, the incorporation of the initial features at each layer can prevent the signal from becoming too smooth, and determines the subspace of possible node representations; (b) batch normalization prevents a complete collapse of the output embedding space to a one-dimensional subspace through the individual rescaling of each column of the feature matrix. This results in the convergence of node representations to the top-$k$ eigenspace of the message-passing operator; (c) moreover, we show that the centering step of a normalization layer -- which can be understood as a projection -- alters the graph signal in message-passing in such a way that relevant information can become harder to extract. We therefore introduce a novel, principled normalization layer called GraphNormv2 in which the centering step is learned such that it does not distort the original graph signal in an undesirable way. Experimental results confirm the effectiveness of our method.
Read more6/13/2024
0
Graph Neural Networks Do Not Always Oversmooth
Bastian Epping, Alexandre Ren'e, Moritz Helias, Michael T. Schaub
Graph neural networks (GNNs) have emerged as powerful tools for processing relational data in applications. However, GNNs suffer from the problem of oversmoothing, the property that the features of all nodes exponentially converge to the same vector over layers, prohibiting the design of deep GNNs. In this work we study oversmoothing in graph convolutional networks (GCNs) by using their Gaussian process (GP) equivalence in the limit of infinitely many hidden features. By generalizing methods from conventional deep neural networks (DNNs), we can describe the distribution of features at the output layer of deep GCNs in terms of a GP: as expected, we find that typical parameter choices from the literature lead to oversmoothing. The theory, however, allows us to identify a new, nonoversmoothing phase: if the initial weights of the network have sufficiently large variance, GCNs do not oversmooth, and node features remain informative even at large depth. We demonstrate the validity of this prediction in finite-size GCNs by training a linear classifier on their output. Moreover, using the linearization of the GCN GP, we generalize the concept of propagation depth of information from DNNs to GCNs. This propagation depth diverges at the transition between the oversmoothing and non-oversmoothing phase. We test the predictions of our approach and find good agreement with finite-size GCNs. Initializing GCNs near the transition to the non-oversmoothing phase, we obtain networks which are both deep and expressive.
Read more6/5/2024
🧠
0
Demystifying Oversmoothing in Attention-Based Graph Neural Networks
Xinyi Wu, Amir Ajorlou, Zihui Wu, Ali Jadbabaie
Oversmoothing in Graph Neural Networks (GNNs) refers to the phenomenon where increasing network depth leads to homogeneous node representations. While previous work has established that Graph Convolutional Networks (GCNs) exponentially lose expressive power, it remains controversial whether the graph attention mechanism can mitigate oversmoothing. In this work, we provide a definitive answer to this question through a rigorous mathematical analysis, by viewing attention-based GNNs as nonlinear time-varying dynamical systems and incorporating tools and techniques from the theory of products of inhomogeneous matrices and the joint spectral radius. We establish that, contrary to popular belief, the graph attention mechanism cannot prevent oversmoothing and loses expressive power exponentially. The proposed framework extends the existing results on oversmoothing for symmetric GCNs to a significantly broader class of GNN models, including random walk GCNs, Graph Attention Networks (GATs) and (graph) transformers. In particular, our analysis accounts for asymmetric, state-dependent and time-varying aggregation operators and a wide range of common nonlinear activation functions, such as ReLU, LeakyReLU, GELU and SiLU.
Read more6/5/2024
0
Beyond Over-smoothing: Uncovering the Trainability Challenges in Deep Graph Neural Networks
Jie Peng, Runlin Lei, Zhewei Wei
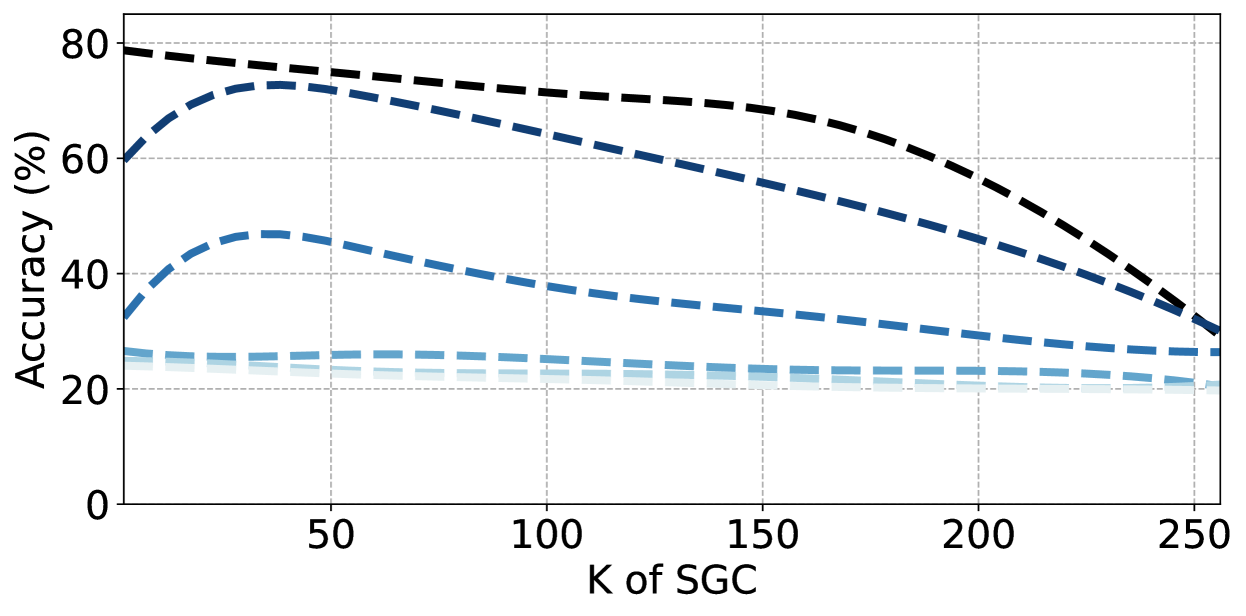
The drastic performance degradation of Graph Neural Networks (GNNs) as the depth of the graph propagation layers exceeds 8-10 is widely attributed to a phenomenon of Over-smoothing. Although recent research suggests that Over-smoothing may not be the dominant reason for such a performance degradation, they have not provided rigorous analysis from a theoretical view, which warrants further investigation. In this paper, we systematically analyze the real dominant problem in deep GNNs and identify the issues that these GNNs towards addressing Over-smoothing essentially work on via empirical experiments and theoretical gradient analysis. We theoretically prove that the difficult training problem of deep MLPs is actually the main challenge, and various existing methods that supposedly tackle Over-smoothing actually improve the trainability of MLPs, which is the main reason for their performance gains. Our further investigation into trainability issues reveals that properly constrained smaller upper bounds of gradient flow notably enhance the trainability of GNNs. Experimental results on diverse datasets demonstrate consistency between our theoretical findings and empirical evidence. Our analysis provides new insights in constructing deep graph models.
Read more8/9/2024