Resolving Inconsistent Semantics in Multi-Dataset Image Segmentation

0

Sign in to get full access
Overview
- Presents a method to resolve inconsistent semantics in multi-dataset image segmentation tasks
- Addresses the challenge of mapping between different label sets when training on multiple datasets
- Proposes an automated label unification approach to harmonize semantic labels across datasets
Plain English Explanation
Image segmentation is the process of dividing an image into meaningful regions or objects. When training machine learning models for image segmentation, it is common to use multiple datasets, which can have inconsistent semantics. This means the same object or concept may be labeled differently across datasets.
The paper introduces a method to resolve these inconsistencies and enable effective multi-dataset training. The key idea is to automatically unify the semantic labels across datasets, mapping them to a common set of categories. This allows the model to learn from the diverse data while avoiding confusion from conflicting label definitions.
The automated label unification approach involves clustering similar classes across datasets and merging them into a harmonized label set. This harmonized set is then used to train a single model that can perform well on all the original datasets, despite their semantic differences.
Technical Explanation
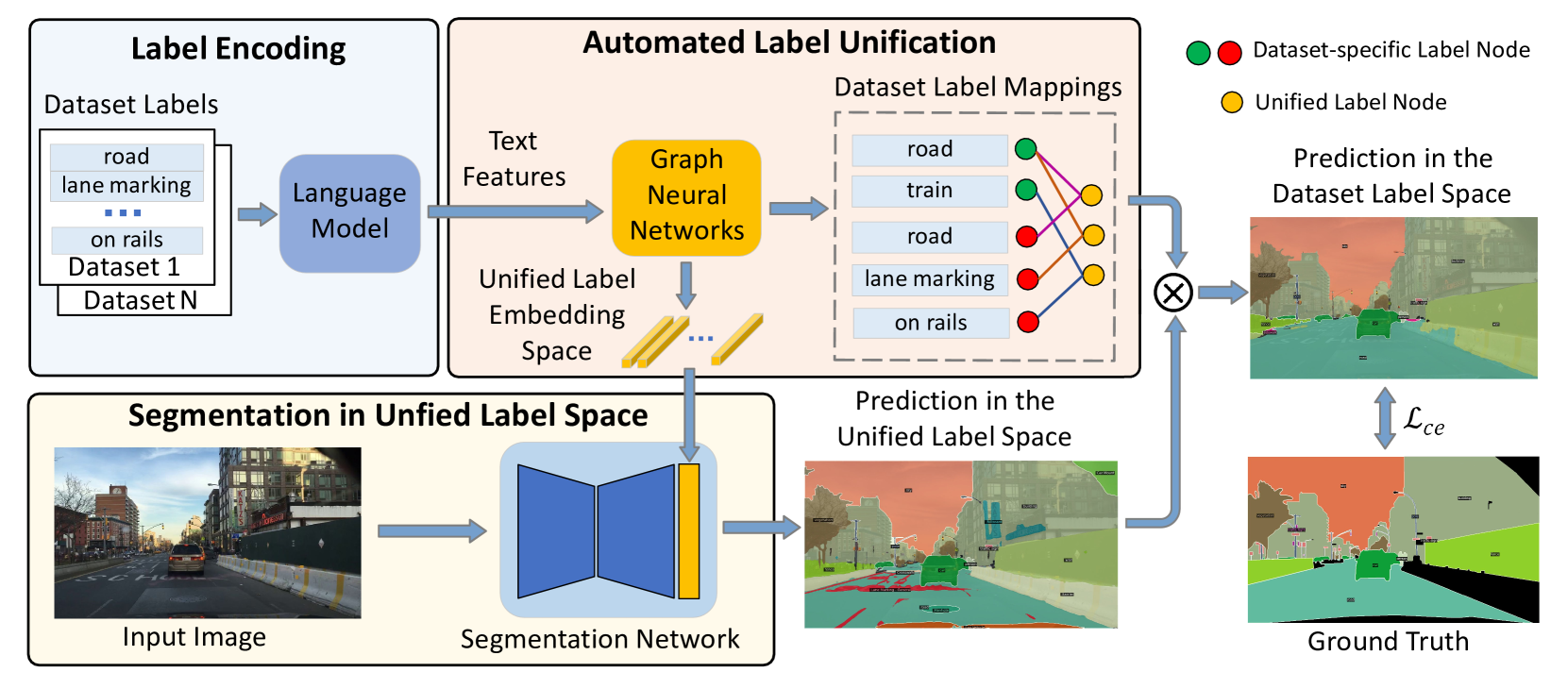
The paper presents an automated label unification approach to address the challenge of inconsistent semantics in multi-dataset image segmentation. The method involves three key steps:
- Label Embedding: The researchers learn a vector representation (embedding) for each semantic label by aggregating visual and textual features from the training data.
- Label Clustering: They then cluster the label embeddings to identify semantically similar classes across datasets, even if they have different names.
- Label Unification: The clustered labels are merged into a harmonized label set, which is used to train a single segmentation model.
This unified model is able to leverage the diverse data from multiple datasets, while avoiding the pitfalls of conflicting label semantics. The paper demonstrates the effectiveness of this approach through experiments on several real-world multi-dataset image segmentation benchmarks.
Critical Analysis
The paper acknowledges that resolving inconsistent semantics is a significant challenge in multi-dataset learning, and provides a principled solution to address it. However, the authors note that their approach relies on the availability of rich visual and textual features to learn the label embeddings, which may not always be the case in practice.
Additionally, the label unification process could potentially result in the loss of fine-grained distinctions between classes, as semantically similar labels are merged together. The impact of this label simplification on the overall segmentation performance is an area that could be explored further.
Conclusion
This paper presents a novel approach to resolving inconsistent semantics in multi-dataset image segmentation tasks. By automatically unifying the semantic labels across datasets, the method enables effective training of a single model that can perform well on diverse data sources. This work represents an important step towards making multi-dataset learning more practical and accessible for real-world computer vision applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Resolving Inconsistent Semantics in Multi-Dataset Image Segmentation
Qilong Zhangli, Di Liu, Abhishek Aich, Dimitris Metaxas, Samuel Schulter
Leveraging multiple training datasets to scale up image segmentation models is beneficial for increasing robustness and semantic understanding. Individual datasets have well-defined ground truth with non-overlapping mask layouts and mutually exclusive semantics. However, merging them for multi-dataset training disrupts this harmony and leads to semantic inconsistencies; for example, the class person in one dataset and class face in another will require multilabel handling for certain pixels. Existing methods struggle with this setting, particularly when evaluated on label spaces mixed from the individual training sets. To overcome these issues, we introduce a simple yet effective multi-dataset training approach by integrating language-based embeddings of class names and label space-specific query embeddings. Our method maintains high performance regardless of the underlying inconsistencies between training datasets. Notably, on four benchmark datasets with label space inconsistencies during inference, we outperform previous methods by 1.6% mIoU for semantic segmentation, 9.1% PQ for panoptic segmentation, 12.1% AP for instance segmentation, and 3.0% in the newly proposed PIQ metric.
Read more9/17/2024
0
Automated Label Unification for Multi-Dataset Semantic Segmentation with GNNs
Rong Ma, Jie Chen, Xiangyang Xue, Jian Pu
Deep supervised models possess significant capability to assimilate extensive training data, thereby presenting an opportunity to enhance model performance through training on multiple datasets. However, conflicts arising from different label spaces among datasets may adversely affect model performance. In this paper, we propose a novel approach to automatically construct a unified label space across multiple datasets using graph neural networks. This enables semantic segmentation models to be trained simultaneously on multiple datasets, resulting in performance improvements. Unlike existing methods, our approach facilitates seamless training without the need for additional manual reannotation or taxonomy reconciliation. This significantly enhances the efficiency and effectiveness of multi-dataset segmentation model training. The results demonstrate that our method significantly outperforms other multi-dataset training methods when trained on seven datasets simultaneously, and achieves state-of-the-art performance on the WildDash 2 benchmark.
Read more8/29/2024
📶
0
Scaling up Multi-domain Semantic Segmentation with Sentence Embeddings
Wei Yin, Yifan Liu, Chunhua Shen, Baichuan Sun, Anton van den Hengel
We propose an approach to semantic segmentation that achieves state-of-the-art supervised performance when applied in a zero-shot setting. It thus achieves results equivalent to those of the supervised methods, on each of the major semantic segmentation datasets, without training on those datasets. This is achieved by replacing each class label with a vector-valued embedding of a short paragraph that describes the class. The generality and simplicity of this approach enables merging multiple datasets from different domains, each with varying class labels and semantics. The resulting merged semantic segmentation dataset of over 2 Million images enables training a model that achieves performance equal to that of state-of-the-art supervised methods on 7 benchmark datasets, despite not using any images therefrom. By fine-tuning the model on standard semantic segmentation datasets, we also achieve a significant improvement over the state-of-the-art supervised segmentation on NYUD-V2 and PASCAL-context at 60% and 65% mIoU, respectively. Based on the closeness of language embeddings, our method can even segment unseen labels. Extensive experiments demonstrate strong generalization to unseen image domains and unseen labels, and that the method enables impressive performance improvements in downstream applications, including depth estimation and instance segmentation.
Read more5/1/2024

0
New!Semi-Supervised Semantic Segmentation with Professional and General Training
Yuting Hong, Hui Xiao, Huazheng Hao, Xiaojie Qiu, Baochen Yao, Chengbin Peng
With the advancement of convolutional neural networks, semantic segmentation has achieved remarkable progress. The training of such networks heavily relies on image annotations, which are very expensive to obtain. Semi-supervised learning can utilize both labeled data and unlabeled data with the help of pseudo-labels. However, in many real-world scenarios where classes are imbalanced, majority classes often play a dominant role during training and the learning quality of minority classes can be undermined. To overcome this limitation, we propose a synergistic training framework, including a professional training module to enhance minority class learning and a general training module to learn more comprehensive semantic information. Based on a pixel selection strategy, they can iteratively learn from each other to reduce error accumulation and coupling. In addition, a dual contrastive learning with anchors is proposed to guarantee more distinct decision boundaries. In experiments, our framework demonstrates superior performance compared to state-of-the-art methods on benchmark datasets.
Read more9/20/2024