Automated Label Unification for Multi-Dataset Semantic Segmentation with GNNs

0
Sign in to get full access
Overview
- This paper presents a method for automatically unifying labels across multiple datasets for multi-dataset semantic segmentation tasks using graph neural networks (GNNs).
- The key idea is to leverage the semantic relationships between labels to automatically align and merge label sets from different datasets, enabling more effective training and inference on combined datasets.
- The proposed approach outperforms previous methods on several benchmark multi-dataset semantic segmentation tasks.
Plain English Explanation
Semantic segmentation is a computer vision task where an AI system learns to identify and label different objects, people, and other elements within an image. Automated Label Unification for Multi-Dataset Semantic Segmentation with GNNs addresses a common challenge in this field - the fact that different datasets often use different label sets to describe the same underlying concepts.
For example, one dataset might label "car" and "automobile" as separate classes, while another uses a single "vehicle" label. This can make it difficult to combine multiple datasets for training, as the models get confused by the inconsistent labeling. The researchers propose using graph neural networks to automatically analyze the semantic relationships between labels and unify them across datasets.
The key insight is that even if the label names differ, the underlying visual and semantic properties of the concepts are often quite similar. By modeling these relationships in a graph structure, the system can learn to map disparate label sets onto a common semantic space. This allows the model to be trained on a combined, unified dataset, leading to better performance on multi-dataset semantic segmentation tasks.
Technical Explanation
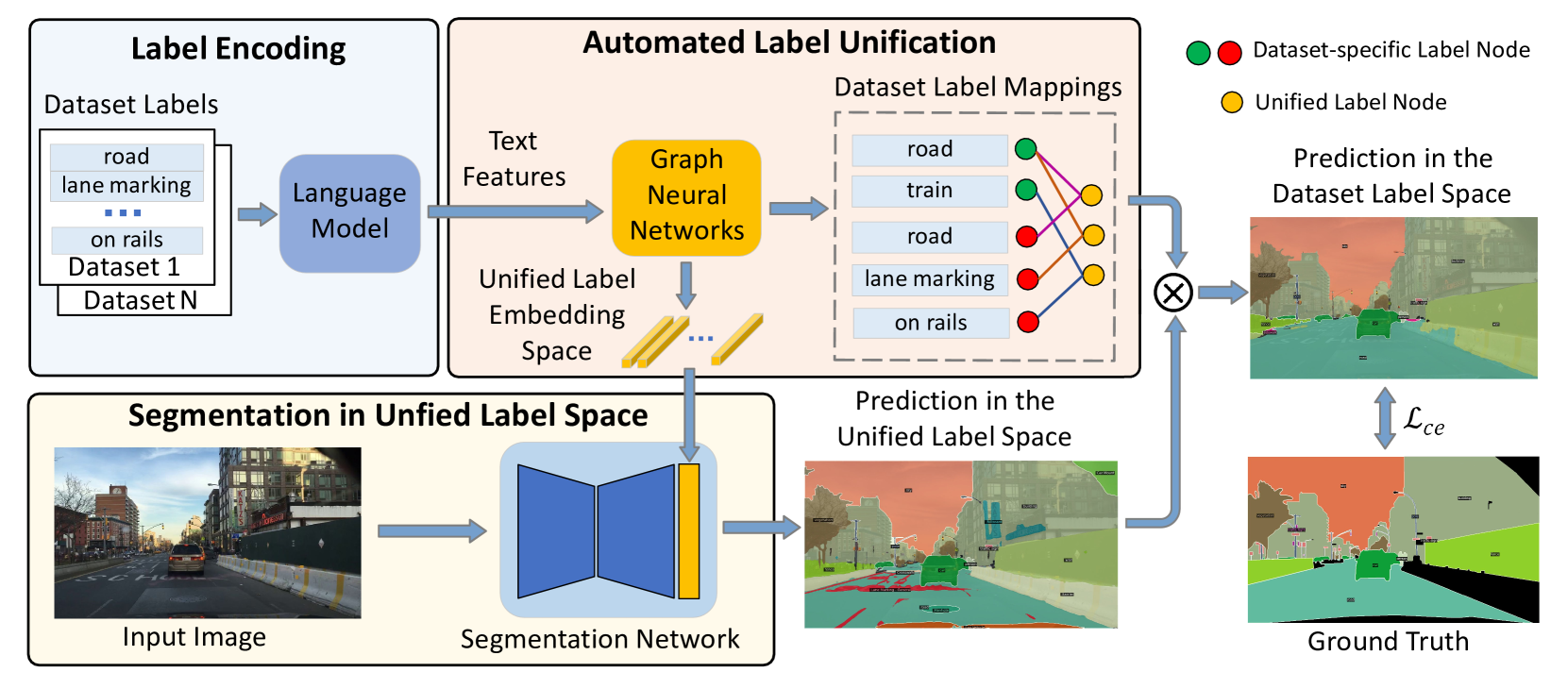
The proposed Automated Label Unification approach first constructs a semantic graph from the label sets of the input datasets. Nodes in this graph represent individual labels, and edges between nodes encode the semantic similarity between them, as determined by word embeddings and other techniques.
This graph is then fed into a graph neural network model, which learns to predict a unified label for each node (i.e., each original dataset label) based on its relationships to other labels. The unified labels are then used to relabel the training data from the original datasets, allowing a single segmentation model to be trained on the combined, harmonized dataset.
The researchers evaluate their method on several multi-dataset semantic segmentation benchmarks. They show that their approach outperforms previous techniques that either required manual label mapping or could not effectively handle datasets with very different label sets.
Critical Analysis
The paper provides a compelling solution to the practical challenge of combining heterogeneous datasets for semantic segmentation. By automating the label unification process, the researchers enable more effective training and deployment of models on diverse real-world data sources.
That said, the approach does rely on the availability of word embeddings or other semantic similarity measures to construct the initial label graph. In some specialized domains, these auxiliary resources may not be readily available, which could limit the applicability of the method.
Additionally, the paper does not extensively explore the robustness of the approach to noisy or inconsistent label assignments within the original datasets. In real-world scenarios, dataset curation is often imperfect, and the ability of the system to handle such noise would be an important consideration.
Conclusion
Automated Label Unification for Multi-Dataset Semantic Segmentation with GNNs presents a novel approach to address a critical challenge in building robust, high-performance semantic segmentation models. By automatically aligning label sets across disparate datasets, the proposed method enables more effective training and deployment of these models in practical, real-world applications. While the approach has some limitations, it represents an important step forward in the field of multi-dataset machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automated Label Unification for Multi-Dataset Semantic Segmentation with GNNs
Rong Ma, Jie Chen, Xiangyang Xue, Jian Pu
Deep supervised models possess significant capability to assimilate extensive training data, thereby presenting an opportunity to enhance model performance through training on multiple datasets. However, conflicts arising from different label spaces among datasets may adversely affect model performance. In this paper, we propose a novel approach to automatically construct a unified label space across multiple datasets using graph neural networks. This enables semantic segmentation models to be trained simultaneously on multiple datasets, resulting in performance improvements. Unlike existing methods, our approach facilitates seamless training without the need for additional manual reannotation or taxonomy reconciliation. This significantly enhances the efficiency and effectiveness of multi-dataset segmentation model training. The results demonstrate that our method significantly outperforms other multi-dataset training methods when trained on seven datasets simultaneously, and achieves state-of-the-art performance on the WildDash 2 benchmark.
Read more8/29/2024

0
Resolving Inconsistent Semantics in Multi-Dataset Image Segmentation
Qilong Zhangli, Di Liu, Abhishek Aich, Dimitris Metaxas, Samuel Schulter
Leveraging multiple training datasets to scale up image segmentation models is beneficial for increasing robustness and semantic understanding. Individual datasets have well-defined ground truth with non-overlapping mask layouts and mutually exclusive semantics. However, merging them for multi-dataset training disrupts this harmony and leads to semantic inconsistencies; for example, the class person in one dataset and class face in another will require multilabel handling for certain pixels. Existing methods struggle with this setting, particularly when evaluated on label spaces mixed from the individual training sets. To overcome these issues, we introduce a simple yet effective multi-dataset training approach by integrating language-based embeddings of class names and label space-specific query embeddings. Our method maintains high performance regardless of the underlying inconsistencies between training datasets. Notably, on four benchmark datasets with label space inconsistencies during inference, we outperform previous methods by 1.6% mIoU for semantic segmentation, 9.1% PQ for panoptic segmentation, 12.1% AP for instance segmentation, and 3.0% in the newly proposed PIQ metric.
Read more9/17/2024
🏋️
0
New!Semi-Supervised Semantic Segmentation with Professional and General Training
Yuting Hong, Hui Xiao, Huazheng Hao, Xiaojie Qiu, Baochen Yao, Chengbin Peng
With the advancement of convolutional neural networks, semantic segmentation has achieved remarkable progress. The training of such networks heavily relies on image annotations, which are very expensive to obtain. Semi-supervised learning can utilize both labeled data and unlabeled data with the help of pseudo-labels. However, in many real-world scenarios where classes are imbalanced, majority classes often play a dominant role during training and the learning quality of minority classes can be undermined. To overcome this limitation, we propose a synergistic training framework, including a professional training module to enhance minority class learning and a general training module to learn more comprehensive semantic information. Based on a pixel selection strategy, they can iteratively learn from each other to reduce error accumulation and coupling. In addition, a dual contrastive learning with anchors is proposed to guarantee more distinct decision boundaries. In experiments, our framework demonstrates superior performance compared to state-of-the-art methods on benchmark datasets.
Read more9/20/2024
🏷️
0
Article Classification with Graph Neural Networks and Multigraphs
Khang Ly, Yury Kashnitsky, Savvas Chamezopoulos, Valeria Krzhizhanovskaya
Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Network (GNN) pipelines with multi-graph representations that simultaneously encode multiple signals of article relatedness, e.g. references, co-authorship, shared publication source, shared subject headings, as distinct edge types. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark OGBN-arXiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph and PubMed Central, respectively. The results demonstrate that multi-graphs consistently improve the performance of a variety of GNN models compared to the default graphs. When deployed with SOTA textual node embedding methods, the transformed multi-graphs enable simple and shallow 2-layer GNN pipelines to achieve results on par with more complex architectures.
Read more5/29/2024