Results of the Big ANN: NeurIPS'23 competition

1

Sign in to get full access
Overview
- The paper presents the results of the "Big ANN: NeurIPS'23" competition, which challenged researchers to develop efficient and scalable approximate nearest-neighbor (ANN) search algorithms.
- Key highlights include the top-performing models, insights into the strengths and limitations of different approaches, and broader implications for the field of large-scale machine learning.
Plain English Explanation
The "Big ANN: NeurIPS'23" competition focused on a fundamental problem in machine learning and AI called approximate nearest-neighbor (ANN) search. This involves quickly finding the objects in a large database that are most similar to a given query object.
For example, imagine you have a huge library of images, and you want to find the images that are visually most similar to a new photo you've taken. ANN search algorithms can rapidly sift through the entire image library to surface the closest matches, without having to do an exhaustive comparison.
The competition challenged researchers to develop new ANN search methods that could scale to billions of data points while maintaining high accuracy. This is important for real-world applications like image retrieval, product recommendation, and knowledge graph exploration.
The top-performing models showcased novel neural network architectures and optimization techniques tailored for efficient ANN search. Insights from the competition could inform the development of next-generation AI systems that can rapidly process and make sense of massive datasets.
Technical Explanation
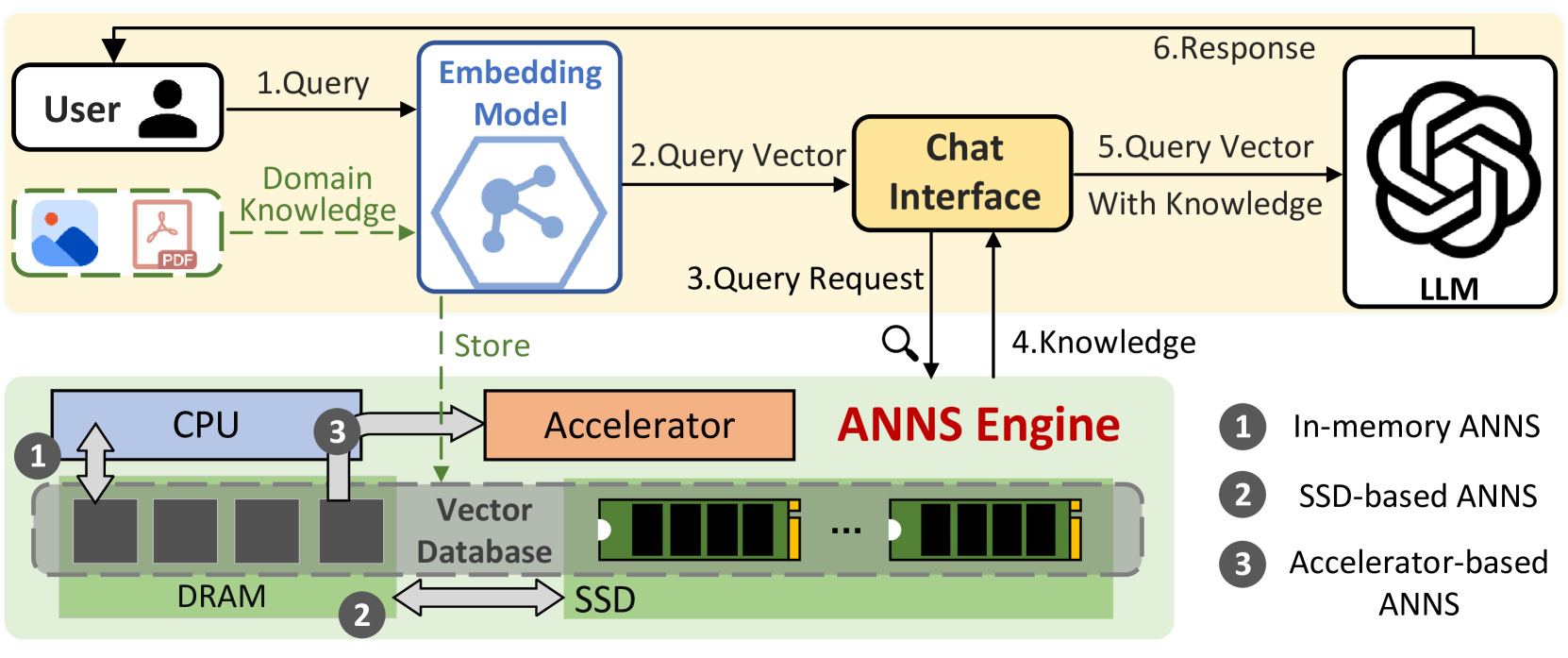
The paper reports the results of the "Big ANN: NeurIPS'23" competition, which challenged participants to develop scalable and accurate approximate nearest-neighbor (ANN) search algorithms. The task involved retrieving the top-k nearest neighbors for a given query from a database of up to 1 billion high-dimensional feature vectors.
The competition featured several tracks, including CPU-only and CPU-GPU cooperative approaches. The top-performing models utilized a variety of techniques, such as:
- Specialized neural network architectures: Novel model designs, like the FusionANNs architecture, that combined multiple sub-networks for efficient query processing.
- Iterative optimization: Iterative refinement of the ANN search model, as demonstrated by the RoarGraph approach.
- Index structuring: Innovative indexing methods, such as the BANG algorithm, for quickly narrowing down the search space.
The competition results provide valuable insights into the strengths and limitations of different ANN search approaches. For example, the FusionANNs model showed the potential of CPU-GPU cooperative processing to achieve high efficiency, while the RoarGraph and BANG approaches demonstrated the importance of index structuring for scalability.
Critical Analysis
The paper presents a comprehensive evaluation of the state-of-the-art in large-scale ANN search, but it also acknowledges several limitations and areas for further research:
-
Generalization: The competition datasets, while large, may not fully capture the diversity and complexity of real-world applications. Additional testing on more varied datasets would be valuable to assess the generalization capabilities of the winning models.
-
Hardware Dependency: Some of the top-performing approaches, such as the FusionANNs model, rely on specialized hardware (e.g., GPU accelerators) that may not be available in all deployment scenarios. Further research is needed to develop hardware-agnostic ANN search solutions.
-
Energy Efficiency: The paper does not provide detailed metrics on the energy consumption or carbon footprint of the competing models. As the field of AI continues to mature, it will be important to consider the environmental sustainability of large-scale machine learning systems.
-
Fairness and Bias: The paper does not discuss the potential for ANN search algorithms to encode or amplify societal biases. Future research should investigate the fairness implications of these techniques, especially when applied to high-stakes domains like healthcare or criminal justice.
Overall, the "Big ANN: NeurIPS'23" competition has advanced the state of the art in large-scale ANN search, but there remain important challenges to address to ensure the long-term responsible development of these technologies.
Conclusion
The "Big ANN: NeurIPS'23" competition has pushed the boundaries of approximate nearest-neighbor (ANN) search, showcasing a range of novel neural network architectures and optimization techniques capable of handling billion-scale datasets. The insights gained from this competition could inform the development of next-generation AI systems that can quickly process and make sense of massive amounts of data, with applications in areas like image retrieval, product recommendation, and knowledge graph exploration.
However, the paper also highlights the need for further research to address limitations in areas such as generalization, hardware dependency, energy efficiency, and fairness. As the field of large-scale machine learning continues to evolve, it will be crucial to consider the broader societal implications of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Results of the Big ANN: NeurIPS'23 competition
Harsha Vardhan Simhadri, Martin Aumuller, Amir Ingber, Matthijs Douze, George Williams, Magdalen Dobson Manohar, Dmitry Baranchuk, Edo Liberty, Frank Liu, Ben Landrum, Mazin Karjikar, Laxman Dhulipala, Meng Chen, Yue Chen, Rui Ma, Kai Zhang, Yuzheng Cai, Jiayang Shi, Yizhuo Chen, Weiguo Zheng, Zihao Wan, Jie Yin, Ben Huang
The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
Read more9/27/2024
0
FusionANNS: An Efficient CPU/GPU Cooperative Processing Architecture for Billion-scale Approximate Nearest Neighbor Search
Bing Tian, Haikun Liu, Yuhang Tang, Shihai Xiao, Zhuohui Duan, Xiaofei Liao, Xuecang Zhang, Junhua Zhu, Yu Zhang
Approximate nearest neighbor search (ANNS) has emerged as a crucial component of database and AI infrastructure. Ever-increasing vector datasets pose significant challenges in terms of performance, cost, and accuracy for ANNS services. None of modern ANNS systems can address these issues simultaneously. We present FusionANNS, a high-throughput, low-latency, cost-efficient, and high-accuracy ANNS system for billion-scale datasets using SSDs and only one entry-level GPU. The key idea of FusionANNS lies in CPU/GPU collaborative filtering and re-ranking mechanisms, which significantly reduce I/O operations across CPUs, GPU, and SSDs to break through the I/O performance bottleneck. Specifically, we propose three novel designs: (1) multi-tiered indexing to avoid data swapping between CPUs and GPU, (2) heuristic re-ranking to eliminate unnecessary I/Os and computations while guaranteeing high accuracy, and (3) redundant-aware I/O deduplication to further improve I/O efficiency. We implement FusionANNS and compare it with the state-of-the-art SSD-based ANNS system--SPANN and GPU-accelerated in-memory ANNS system--RUMMY. Experimental results show that FusionANNS achieves 1) 9.4-13.1X higher query per second (QPS) and 5.7-8.8X higher cost efficiency compared with SPANN; 2) and 2-4.9X higher QPS and 2.3-6.8X higher cost efficiency compared with RUMMY, while guaranteeing low latency and high accuracy.
Read more9/26/2024
✅
0
Approximate Nearest Neighbour Search on Dynamic Datasets: An Investigation
Ben Harwood, Amir Dezfouli, Iadine Chades, Conrad Sanderson
Approximate k-Nearest Neighbour (ANN) methods are often used for mining information and aiding machine learning on large scale high-dimensional datasets. ANN methods typically differ in the index structure used for accelerating searches, resulting in various recall/runtime trade-off points. For applications with static datasets, runtime constraints and dataset properties can be used to empirically select an ANN method with suitable operating characteristics. However, for applications with dynamic datasets, which are subject to frequent online changes (like addition of new samples), there is currently no consensus as to which ANN methods are most suitable. Traditional evaluation approaches do not consider the computational costs of updating the index structure, as well as the rate and size of index updates. To address this, we empirically evaluate 5 popular ANN methods on two main applications (online data collection and online feature learning) while taking into account these considerations. Two dynamic datasets are used, derived from the SIFT1M dataset with 1 million samples and the DEEP1B dataset with 1 billion samples. The results indicate that the often used k-d trees method is not suitable on dynamic datasets as it is slower than a straightforward baseline exhaustive search method. For online data collection, the Hierarchical Navigable Small World Graphs method achieves a consistent speedup over baseline across a wide range of recall rates. For online feature learning, the Scalable Nearest Neighbours method is faster than baseline for recall rates below 75%.
Read more6/6/2024

0
RoarGraph: A Projected Bipartite Graph for Efficient Cross-Modal Approximate Nearest Neighbor Search
Meng Chen, Kai Zhang, Zhenying He, Yinan Jing, X. Sean Wang
Approximate Nearest Neighbor Search (ANNS) is a fundamental and critical component in many applications, including recommendation systems and large language model-based applications. With the advancement of multimodal neural models, which transform data from different modalities into a shared high-dimensional space as feature vectors, cross-modal ANNS aims to use the data vector from one modality (e.g., texts) as the query to retrieve the most similar items from another (e.g., images or videos). However, there is an inherent distribution gap between embeddings from different modalities, and cross-modal queries become Out-of-Distribution (OOD) to the base data. Consequently, state-of-the-art ANNS approaches suffer poor performance for OOD workloads. In this paper, we quantitatively analyze the properties of the OOD workloads to gain an understanding of their ANNS efficiency. Unlike single-modal workloads, we reveal OOD queries spatially deviate from base data, and the k-nearest neighbors of an OOD query are distant from each other in the embedding space. The property breaks the assumptions of existing ANNS approaches and mismatches their design for efficient search. With insights from the OOD workloads, we propose pRojected bipartite Graph (RoarGraph), an efficient ANNS graph index built under the guidance of query distribution. Extensive experiments show that RoarGraph significantly outperforms state-of-the-art approaches on modern cross-modal datasets, achieving up to 3.56x faster search speed at a 90% recall rate for OOD queries.
Read more8/20/2024