Rethinking RGB-D Fusion for Semantic Segmentation in Surgical Datasets

0

Sign in to get full access
Overview
- This paper explores a novel approach to fusing RGB and depth (RGB-D) data for semantic segmentation in surgical datasets.
- The researchers propose a multi-modal learning framework that effectively combines RGB and depth information to improve the performance of semantic segmentation models.
- The paper presents experimental results demonstrating the advantages of their approach over traditional RGB-D fusion methods.
Plain English Explanation
In this paper, the researchers tackle the challenge of semantic segmentation in surgical datasets. Semantic segmentation is the process of dividing an image into meaningful regions or segments, such as distinguishing different organs or surgical instruments.
The researchers recognize that combining RGB (color) and depth (3D) information can be beneficial for this task, as the depth data can provide additional spatial information that complements the color data. However, they argue that traditional RGB-D fusion methods may not be fully optimizing the potential of this multi-modal approach.
To address this, the researchers propose a new multi-modal learning framework that more effectively integrates the RGB and depth data. Their approach aims to better leverage the complementary information in these two data sources to improve the performance of semantic segmentation models in surgical settings.
Through experiments on surgical datasets, the researchers demonstrate that their proposed method outperforms existing RGB-D fusion techniques, leading to more accurate and robust semantic segmentation results. This could have important implications for computer-assisted surgery and other medical applications that rely on accurate understanding of the surgical environment.
Technical Explanation
The researchers begin by highlighting the limitations of existing RGB-D fusion methods for semantic segmentation in surgical datasets. They argue that these approaches may not be fully exploiting the potential benefits of combining color and depth information.
To address this, the researchers propose a novel multi-modal learning framework that learns to effectively fuse the RGB and depth data. Their approach involves a carefully designed architecture that includes separate encoder networks for the RGB and depth inputs, followed by a fusion module that integrates the learned features.
The key innovation of their method is the use of a cross-attention mechanism to dynamically weigh the contributions of the RGB and depth features during the fusion process. This allows the model to adaptively combine the information from the two modalities based on the specific characteristics of the surgical scene.
Through extensive experiments on several surgical datasets, the researchers demonstrate the advantages of their proposed approach. They show that their multi-modal learning framework consistently outperforms traditional RGB-D fusion techniques in terms of semantic segmentation accuracy, highlighting the benefits of their more sophisticated fusion strategy.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their study. For example, they note that their approach may not be as effective in scenarios with significant occlusions or missing depth data, which can be common in surgical environments.
Additionally, the researchers suggest that exploring alternative fusion architectures or incorporating additional modalities, such as infrared or ultrasound data, could potentially further improve the performance of their system.
While the results presented in the paper are promising, it would be valuable to see the proposed method evaluated on a wider range of surgical datasets and in real-world clinical settings to assess its practical applicability and robustness.
Conclusion
This paper presents a novel multi-modal learning framework for fusing RGB and depth data to improve semantic segmentation in surgical datasets. By leveraging a cross-attention mechanism to dynamically integrate the complementary information from these two modalities, the researchers demonstrate significant performance gains over traditional RGB-D fusion approaches.
The potential implications of this work are substantial, as accurate semantic segmentation is crucial for computer-assisted surgery and other medical applications that rely on a detailed understanding of the surgical environment. The researchers' findings suggest that further advancements in multi-modal learning could lead to even more powerful and robust tools for surgical data analysis and decision support.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking RGB-D Fusion for Semantic Segmentation in Surgical Datasets
Muhammad Abdullah Jamal, Omid Mohareri
Surgical scene understanding is a key technical component for enabling intelligent and context aware systems that can transform various aspects of surgical interventions. In this work, we focus on the semantic segmentation task, propose a simple yet effective multi-modal (RGB and depth) training framework called SurgDepth, and show state-of-the-art (SOTA) results on all publicly available datasets applicable for this task. Unlike previous approaches, which either fine-tune SOTA segmentation models trained on natural images, or encode RGB or RGB-D information using RGB only pre-trained backbones, SurgDepth, which is built on top of Vision Transformers (ViTs), is designed to encode both RGB and depth information through a simple fusion mechanism. We conduct extensive experiments on benchmark datasets including EndoVis2022, AutoLapro, LapI2I and EndoVis2017 to verify the efficacy of SurgDepth. Specifically, SurgDepth achieves a new SOTA IoU of 0.86 on EndoVis 2022 SAR-RARP50 challenge and outperforms the current best method by at least 4%, using a shallow and compute efficient decoder consisting of ConvNeXt blocks.
Read more7/30/2024

0
Augmented Efficiency: Reducing Memory Footprint and Accelerating Inference for 3D Semantic Segmentation through Hybrid Vision
Aditya Krishnan, Jayneel Vora, Prasant Mohapatra
Semantic segmentation has emerged as a pivotal area of study in computer vision, offering profound implications for scene understanding and elevating human-machine interactions across various domains. While 2D semantic segmentation has witnessed significant strides in the form of lightweight, high-precision models, transitioning to 3D semantic segmentation poses distinct challenges. Our research focuses on achieving efficiency and lightweight design for 3D semantic segmentation models, similar to those achieved for 2D models. Such a design impacts applications of 3D semantic segmentation where memory and latency are of concern. This paper introduces a novel approach to 3D semantic segmentation, distinguished by incorporating a hybrid blend of 2D and 3D computer vision techniques, enabling a streamlined, efficient process. We conduct 2D semantic segmentation on RGB images linked to 3D point clouds and extend the results to 3D using an extrusion technique for specific class labels, reducing the point cloud subspace. We perform rigorous evaluations with the DeepViewAgg model on the complete point cloud as our baseline by measuring the Intersection over Union (IoU) accuracy, inference time latency, and memory consumption. This model serves as the current state-of-the-art 3D semantic segmentation model on the KITTI-360 dataset. We can achieve heightened accuracy outcomes, surpassing the baseline for 6 out of the 15 classes while maintaining a marginal 1% deviation below the baseline for the remaining class labels. Our segmentation approach demonstrates a 1.347x speedup and about a 43% reduced memory usage compared to the baseline.
Read more7/24/2024
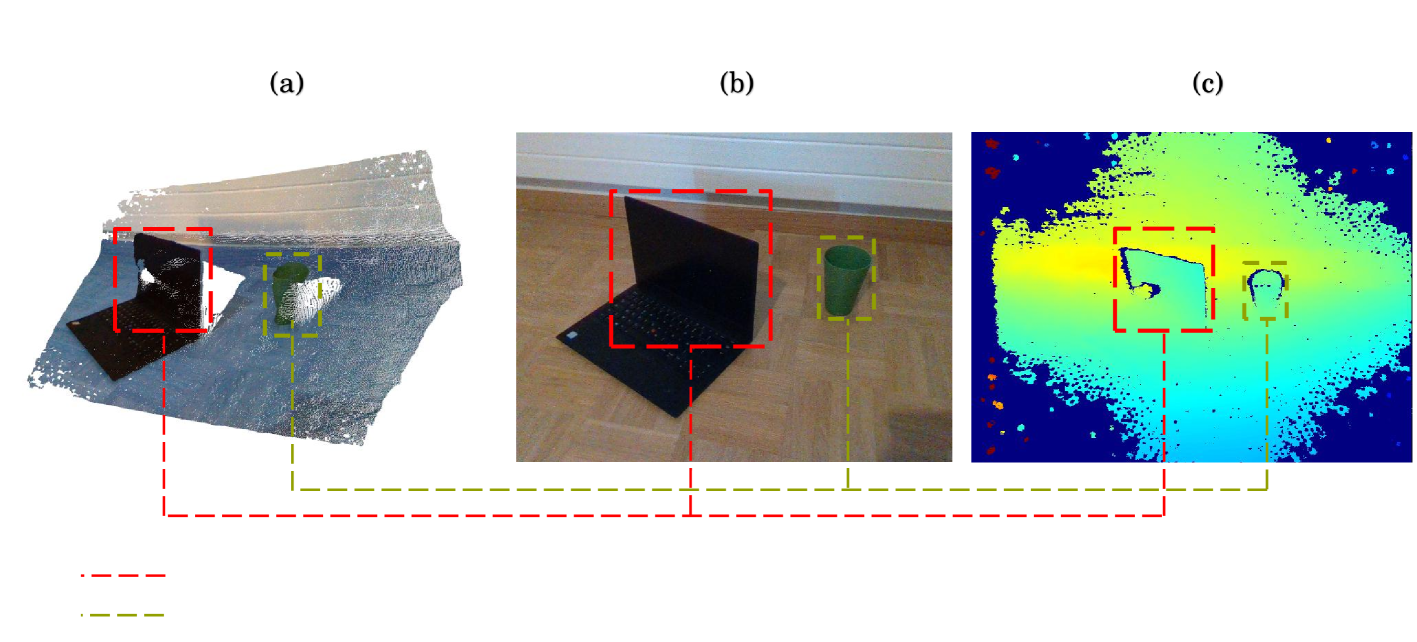
0
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Safouane El Ghazouali, Youssef Mhirit, Ali Oukhrid, Umberto Michelucci, Hichem Nouira
In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color textit{RGB} and depth textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
Read more5/2/2024

0
vFusedSeg3D: 3rd Place Solution for 2024 Waymo Open Dataset Challenge in Semantic Segmentation
Osama Amjad, Ammad Nadeem
In this technical study, we introduce VFusedSeg3D, an innovative multi-modal fusion system created by the VisionRD team that combines camera and LiDAR data to significantly enhance the accuracy of 3D perception. VFusedSeg3D uses the rich semantic content of the camera pictures and the accurate depth sensing of LiDAR to generate a strong and comprehensive environmental understanding, addressing the constraints inherent in each modality. Through a carefully thought-out network architecture that aligns and merges these information at different stages, our novel feature fusion technique combines geometric features from LiDAR point clouds with semantic features from camera images. With the use of multi-modality techniques, performance has significantly improved, yielding a state-of-the-art mIoU of 72.46% on the validation set as opposed to the prior 70.51%.VFusedSeg3D sets a new benchmark in 3D segmentation accuracy. making it an ideal solution for applications requiring precise environmental perception.
Read more8/29/2024