FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
2403.00175
0
0
Abstract
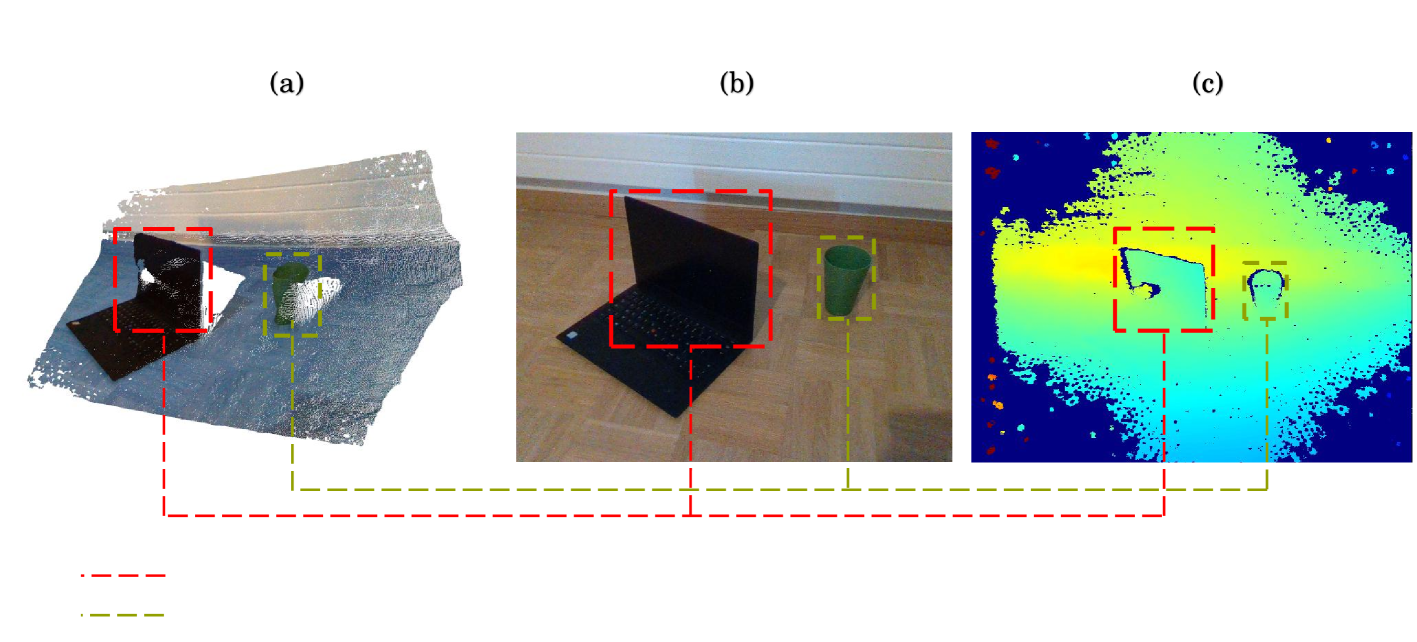
In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color textit{RGB} and depth textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
Create account to get full access
Overview
- The paper presents "FusionVision", a comprehensive approach for 3D object reconstruction and segmentation from RGB-D (Red-Green-Blue-Depth) cameras using YOLO (You Only Look Once) and Fast Segment Anything.
- The method combines object detection, instance segmentation, and 3D reconstruction to provide a full pipeline for understanding the 3D environment from a single RGB-D input.
Plain English Explanation
The paper introduces a new system called "FusionVision" that can analyze 3D scenes using a depth-sensing camera. It takes the camera's color and depth information and uses advanced AI models to detect objects, outline their exact shapes, and reconstruct their 3D geometry.
The key innovations are:
- Using the YOLO object detection model to quickly identify what objects are present in the scene.
- Applying the Fast Segment Anything model to precisely segment the outlines of those detected objects.
- Combining the object detection, segmentation, and depth information to reconstruct a full 3D representation of the scene.
This allows FusionVision to provide a comprehensive understanding of the 3D world from a single RGB-D camera input, which could be useful for applications like robotics, augmented reality, or 3D scene understanding.
Technical Explanation
The paper first reviews related work in 3D object reconstruction, multi-modal 3D object detection, and single-view 3D reconstruction. It then proposes the FusionVision pipeline, which consists of three key components:
- Object Detection: The authors use the YOLO object detection model to quickly identify the objects present in the RGB-D input.
- Instance Segmentation: They then apply the Fast Segment Anything model to precisely segment the outlines of the detected objects.
- 3D Reconstruction: Finally, they combine the object detections, segmentations, and depth information to reconstruct a full 3D representation of the scene.
The paper presents experiments on several RGB-D benchmark datasets, demonstrating that FusionVision outperforms previous methods on 3D object detection and segmentation metrics. The authors also show qualitative results of the reconstructed 3D scenes.
Critical Analysis
The paper provides a comprehensive approach to 3D scene understanding from RGB-D cameras, leveraging state-of-the-art computer vision models. However, the authors acknowledge a few limitations:
- The 3D reconstruction quality is still imperfect, especially for thin or occluded objects.
- The approach relies on the availability of reliable RGB-D sensors, which may not be present in all environments.
- There is room for further research to improve the robustness and efficiency of the overall pipeline.
Additionally, one could question the generalizability of the method, as the experiments are conducted on a limited set of benchmark datasets. Further testing on more diverse real-world scenarios would help validate the system's performance and applicability.
Conclusion
The FusionVision paper presents a notable advance in 3D scene understanding by combining object detection, instance segmentation, and 3D reconstruction from a single RGB-D input. This comprehensive approach could have significant implications for applications like robotics, augmented reality, and 3D scene analysis. While the method has some limitations, it demonstrates the potential of fusing multiple computer vision techniques to create a more complete understanding of the 3D world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation
Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Fahad Shahbaz Khan
0
0
Recent works on open-vocabulary 3D instance segmentation show strong promise, but at the cost of slow inference speed and high computation requirements. This high computation cost is typically due to their heavy reliance on 3D clip features, which require computationally expensive 2D foundation models like Segment Anything (SAM) and CLIP for multi-view aggregation into 3D. As a consequence, this hampers their applicability in many real-world applications that require both fast and accurate predictions. To this end, we propose a fast yet accurate open-vocabulary 3D instance segmentation approach, named Open-YOLO 3D, that effectively leverages only 2D object detection from multi-view RGB images for open-vocabulary 3D instance segmentation. We address this task by generating class-agnostic 3D masks for objects in the scene and associating them with text prompts. We observe that the projection of class-agnostic 3D point cloud instances already holds instance information; thus, using SAM might only result in redundancy that unnecessarily increases the inference time. We empirically find that a better performance of matching text prompts to 3D masks can be achieved in a faster fashion with a 2D object detector. We validate our Open-YOLO 3D on two benchmarks, ScanNet200 and Replica, under two scenarios: (i) with ground truth masks, where labels are required for given object proposals, and (ii) with class-agnostic 3D proposals generated from a 3D proposal network. Our Open-YOLO 3D achieves state-of-the-art performance on both datasets while obtaining up to $sim$16$times$ speedup compared to the best existing method in literature. On ScanNet200 val. set, our Open-YOLO 3D achieves mean average precision (mAP) of 24.7% while operating at 22 seconds per scene. Code and model are available at github.com/aminebdj/OpenYOLO3D.
6/21/2024

Enhanced Automotive Object Detection via RGB-D Fusion in a DiffusionDet Framework
Eliraz Orfaig, Inna Stainvas, Igal Bilik
0
0
Vision-based autonomous driving requires reliable and efficient object detection. This work proposes a DiffusionDet-based framework that exploits data fusion from the monocular camera and depth sensor to provide the RGB and depth (RGB-D) data. Within this framework, ground truth bounding boxes are randomly reshaped as part of the training phase, allowing the model to learn the reverse diffusion process of noise addition. The system methodically enhances a randomly generated set of boxes at the inference stage, guiding them toward accurate final detections. By integrating the textural and color features from RGB images with the spatial depth information from the LiDAR sensors, the proposed framework employs a feature fusion that substantially enhances object detection of automotive targets. The $2.3$ AP gain in detecting automotive targets is achieved through comprehensive experiments using the KITTI dataset. Specifically, the improved performance of the proposed approach in detecting small objects is demonstrated.
6/6/2024
🤿
3D Instance Segmentation Using Deep Learning on RGB-D Indoor Data
Siddiqui Muhammad Yasir, Amin Muhammad Sadiq, Hyunsik Ahn
0
0
3D object recognition is a challenging task for intelligent and robot systems in industrial and home indoor environments. It is critical for such systems to recognize and segment the 3D object instances that they encounter on a frequent basis. The computer vision, graphics, and machine learning fields have all given it a lot of attention. Traditionally, 3D segmentation was done with hand-crafted features and designed approaches that did not achieve acceptable performance and could not be generalized to large-scale data. Deep learning approaches have lately become the preferred method for 3D segmentation challenges by their great success in 2D computer vision. However, the task of instance segmentation is currently less explored. In this paper, we propose a novel approach for efficient 3D instance segmentation using red green blue and depth (RGB-D) data based on deep learning. The 2D region based convolutional neural networks (Mask R-CNN) deep learning model with point based rending module is adapted to integrate with depth information to recognize and segment 3D instances of objects. In order to generate 3D point cloud coordinates (x, y, z), segmented 2D pixels (u, v) of recognized object regions in the RGB image are merged into (u, v) points of the depth image. Moreover, we conducted an experiment and analysis to compare our proposed method from various points of view and distances. The experimentation shows the proposed 3D object recognition and instance segmentation are sufficiently beneficial to support object handling in robotic and intelligent systems.
6/24/2024
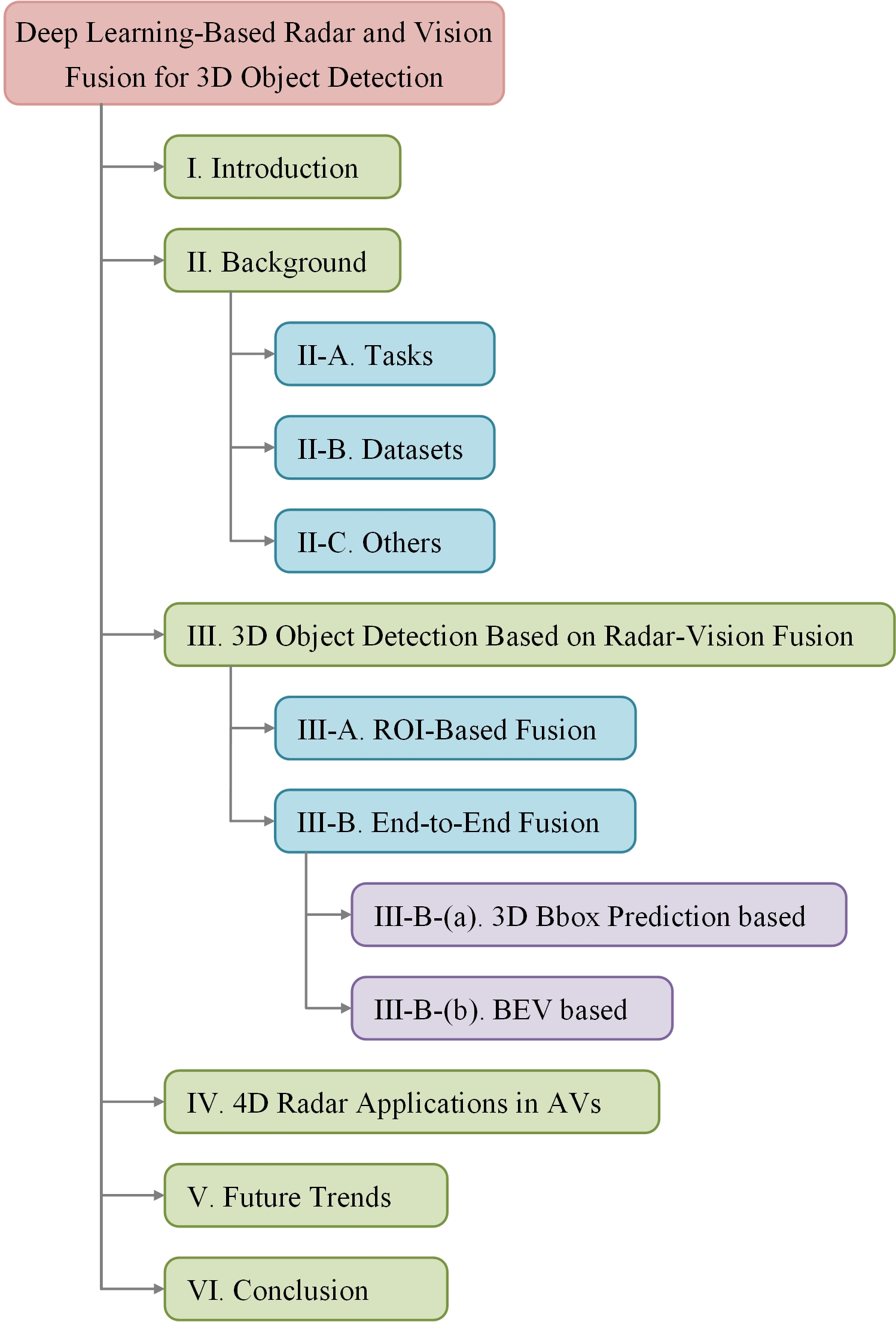
A Survey of Deep Learning Based Radar and Vision Fusion for 3D Object Detection in Autonomous Driving
Di Wu, Feng Yang, Benlian Xu, Pan Liao, Bo Liu
0
0
With the rapid advancement of autonomous driving technology, there is a growing need for enhanced safety and efficiency in the automatic environmental perception of vehicles during their operation. In modern vehicle setups, cameras and mmWave radar (radar), being the most extensively employed sensors, demonstrate complementary characteristics, inherently rendering them conducive to fusion and facilitating the achievement of both robust performance and cost-effectiveness. This paper focuses on a comprehensive survey of radar-vision (RV) fusion based on deep learning methods for 3D object detection in autonomous driving. We offer a comprehensive overview of each RV fusion category, specifically those employing region of interest (ROI) fusion and end-to-end fusion strategies. As the most promising fusion strategy at present, we provide a deeper classification of end-to-end fusion methods, including those 3D bounding box prediction based and BEV based approaches. Moreover, aligning with recent advancements, we delineate the latest information on 4D radar and its cutting-edge applications in autonomous vehicles (AVs). Finally, we present the possible future trends of RV fusion and summarize this paper.
6/4/2024