Rethinking Score Distillation as a Bridge Between Image Distributions

0
Sign in to get full access
Overview
- The paper explores a new approach to score distillation, which aims to bridge the gap between image distributions.
- It proposes a method to distill the score function of a generative model and use it to sample from a learned manifold, leading to diverse and high-quality image generation.
- The authors demonstrate the effectiveness of their approach on various datasets, showcasing its potential for practical applications.
Plain English Explanation
The paper introduces a novel technique for score distillation, which is a way to capture the "essence" of how a generative model creates images. The key idea is to distill the "score function" of the model - this is a mathematical function that tells the model how to gradually adjust the image to make it more realistic.
By distilling this score function, the researchers can then use it to sample directly from the learned manifold - the space of all possible realistic images that the model has learned. This allows them to generate diverse and high-quality images, without having to go through the full process of the original generative model.
The authors demonstrate the effectiveness of their approach on several different datasets, showing that it can produce impressive results compared to other methods. This suggests that their technique could have important practical applications in areas like image synthesis, where being able to efficiently generate diverse and realistic images is crucial.
Technical Explanation
The paper proposes a new method for score distillation, which aims to bridge the gap between the distributions of real and generated images. The key insight is that by distilling the score function of a pre-trained generative model, one can then use this distilled score function to directly sample from the learned manifold of realistic images.
The authors first train a generative model using a variant of diffusion-based techniques. They then distill the score function of this model into a separate network, which can be used to generate new images. This distillation process allows the authors to bypass the full generative process of the original model, leading to more efficient and diverse image sampling.
Specifically, the authors use a reparameterized version of the Denoising Diffusion Implicit Models (DDIM) framework to distill the score function. This allows them to capture the geometry of the learned image manifold more accurately. They then demonstrate the effectiveness of their approach on several image datasets, showing that it can generate diverse and high-quality images compared to other state-of-the-art methods.
Critical Analysis
The paper presents a novel and promising approach to score distillation, but there are a few potential limitations and areas for further research:
-
Dependence on the base generative model: The performance of the score distillation method is heavily dependent on the quality and expressiveness of the pre-trained generative model. If the base model has limitations or biases, these may be inherited by the distilled score function.
-
Computational efficiency: While the score distillation process itself is efficient, the need to first train a full generative model may be computationally intensive, especially for large-scale datasets.
-
Generalization to other domains: The paper focuses on image generation, but it would be interesting to see if the score distillation approach could be extended to other data modalities, such as text or speech.
-
Interpretability: The paper does not delve deeply into the interpretability of the distilled score function. Understanding the underlying mechanisms and representations learned by this function could provide valuable insights.
Overall, the paper presents an interesting and promising direction for improving the efficiency and diversity of generative modeling. Further research exploring the limitations and potential extensions of this approach could lead to significant advancements in the field.
Conclusion
The paper introduces a novel score distillation technique that aims to bridge the gap between the distributions of real and generated images. By distilling the score function of a pre-trained generative model, the authors demonstrate the ability to efficiently sample from the learned manifold of realistic images, leading to diverse and high-quality generation.
The authors' findings suggest that score distillation could have important practical applications in areas like image synthesis, where the ability to generate diverse and realistic content is crucial. While the approach has some potential limitations, the paper presents an interesting and promising direction for improving the efficiency and capabilities of generative modeling. Further research exploring the broader implications and extensions of this work could lead to significant advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking Score Distillation as a Bridge Between Image Distributions
David McAllister, Songwei Ge, Jia-Bin Huang, David W. Jacobs, Alexei A. Efros, Aleksander Holynski, Angjoo Kanazawa
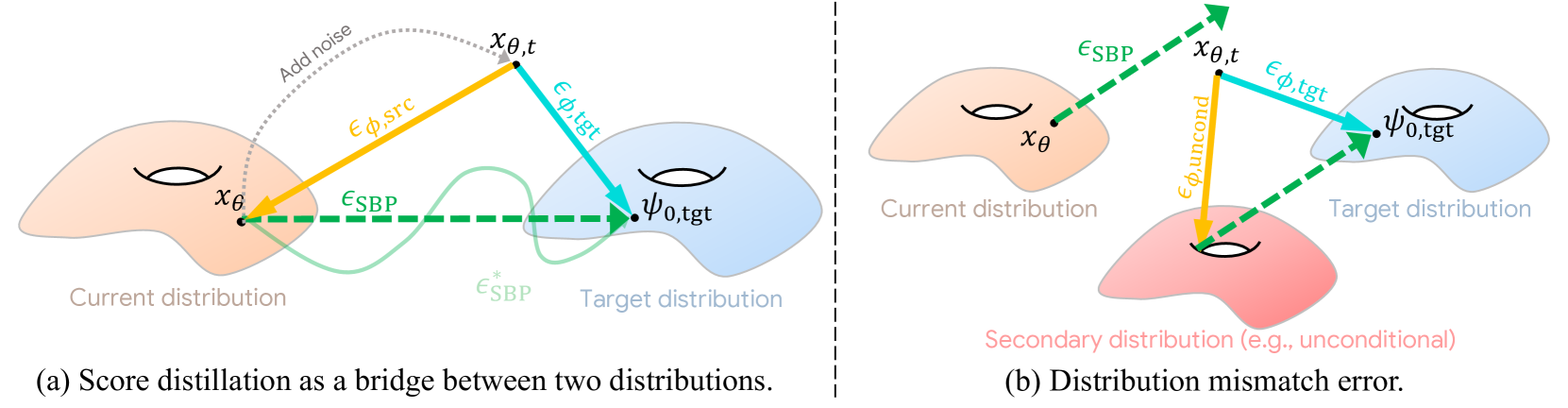
Score distillation sampling (SDS) has proven to be an important tool, enabling the use of large-scale diffusion priors for tasks operating in data-poor domains. Unfortunately, SDS has a number of characteristic artifacts that limit its usefulness in general-purpose applications. In this paper, we make progress toward understanding the behavior of SDS and its variants by viewing them as solving an optimal-cost transport path from a source distribution to a target distribution. Under this new interpretation, these methods seek to transport corrupted images (source) to the natural image distribution (target). We argue that current methods' characteristic artifacts are caused by (1) linear approximation of the optimal path and (2) poor estimates of the source distribution. We show that calibrating the text conditioning of the source distribution can produce high-quality generation and translation results with little extra overhead. Our method can be easily applied across many domains, matching or beating the performance of specialized methods. We demonstrate its utility in text-to-2D, text-based NeRF optimization, translating paintings to real images, optical illusion generation, and 3D sketch-to-real. We compare our method to existing approaches for score distillation sampling and show that it can produce high-frequency details with realistic colors.
Read more6/14/2024

0
Score Distillation Sampling with Learned Manifold Corrective
Thiemo Alldieck, Nikos Kolotouros, Cristian Sminchisescu
Score Distillation Sampling (SDS) is a recent but already widely popular method that relies on an image diffusion model to control optimization problems using text prompts. In this paper, we conduct an in-depth analysis of the SDS loss function, identify an inherent problem with its formulation, and propose a surprisingly easy but effective fix. Specifically, we decompose the loss into different factors and isolate the component responsible for noisy gradients. In the original formulation, high text guidance is used to account for the noise, leading to unwanted side effects such as oversaturation or repeated detail. Instead, we train a shallow network mimicking the timestep-dependent frequency bias of the image diffusion model in order to effectively factor it out. We demonstrate the versatility and the effectiveness of our novel loss formulation through qualitative and quantitative experiments, including optimization-based image synthesis and editing, zero-shot image translation network training, and text-to-3D synthesis.
Read more7/8/2024

0
Score Distillation via Reparametrized DDIM
Artem Lukoianov, Haitz S'aez de Oc'ariz Borde, Kristjan Greenewald, Vitor Campagnolo Guizilini, Timur Bagautdinov, Vincent Sitzmann, Justin Solomon
While 2D diffusion models generate realistic, high-detail images, 3D shape generation methods like Score Distillation Sampling (SDS) built on these 2D diffusion models produce cartoon-like, over-smoothed shapes. To help explain this discrepancy, we show that the image guidance used in Score Distillation can be understood as the velocity field of a 2D denoising generative process, up to the choice of a noise term. In particular, after a change of variables, SDS resembles a high-variance version of Denoising Diffusion Implicit Models (DDIM) with a differently-sampled noise term: SDS introduces noise i.i.d. randomly at each step, while DDIM infers it from the previous noise predictions. This excessive variance can lead to over-smoothing and unrealistic outputs. We show that a better noise approximation can be recovered by inverting DDIM in each SDS update step. This modification makes SDS's generative process for 2D images almost identical to DDIM. In 3D, it removes over-smoothing, preserves higher-frequency detail, and brings the generation quality closer to that of 2D samplers. Experimentally, our method achieves better or similar 3D generation quality compared to other state-of-the-art Score Distillation methods, all without training additional neural networks or multi-view supervision, and providing useful insights into relationship between 2D and 3D asset generation with diffusion models.
Read more6/14/2024

0
Flow Score Distillation for Diverse Text-to-3D Generation
Runjie Yan, Kailu Wu, Kaisheng Ma
Recent advancements in Text-to-3D generation have yielded remarkable progress, particularly through methods that rely on Score Distillation Sampling (SDS). While SDS exhibits the capability to create impressive 3D assets, it is hindered by its inherent maximum-likelihood-seeking essence, resulting in limited diversity in generation outcomes. In this paper, we discover that the Denoise Diffusion Implicit Models (DDIM) generation process (ie PF-ODE) can be succinctly expressed using an analogue of SDS loss. One step further, one can see SDS as a generalized DDIM generation process. Following this insight, we show that the noise sampling strategy in the noise addition stage significantly restricts the diversity of generation results. To address this limitation, we present an innovative noise sampling approach and introduce a novel text-to-3D method called Flow Score Distillation (FSD). Our validation experiments across various text-to-image Diffusion Models demonstrate that FSD substantially enhances generation diversity without compromising quality.
Read more7/30/2024