Score Distillation via Reparametrized DDIM
2405.15891
0
0

Abstract
While 2D diffusion models generate realistic, high-detail images, 3D shape generation methods like Score Distillation Sampling (SDS) built on these 2D diffusion models produce cartoon-like, over-smoothed shapes. To help explain this discrepancy, we show that the image guidance used in Score Distillation can be understood as the velocity field of a 2D denoising generative process, up to the choice of a noise term. In particular, after a change of variables, SDS resembles a high-variance version of Denoising Diffusion Implicit Models (DDIM) with a differently-sampled noise term: SDS introduces noise i.i.d. randomly at each step, while DDIM infers it from the previous noise predictions. This excessive variance can lead to over-smoothing and unrealistic outputs. We show that a better noise approximation can be recovered by inverting DDIM in each SDS update step. This modification makes SDS's generative process for 2D images almost identical to DDIM. In 3D, it removes over-smoothing, preserves higher-frequency detail, and brings the generation quality closer to that of 2D samplers. Experimentally, our method achieves better or similar 3D generation quality compared to other state-of-the-art Score Distillation methods, all without training additional neural networks or multi-view supervision, and providing useful insights into relationship between 2D and 3D asset generation with diffusion models.
Create account to get full access
Overview
- This paper introduces a novel technique called "Score Distillation via Reparametrized DDIM" for generating high-quality 3D content from text.
- The method builds upon the DDIM (Denoising Diffusion Implicit Models) framework, which is a powerful class of generative models that can produce realistic images and 3D content.
- The key innovation is a reparametrization of the DDIM process, which allows for more efficient and stable training and generation of 3D objects.
Plain English Explanation
The researchers have developed a new way to generate 3D objects and content based on written descriptions. This builds on previous work on diffusion models, which are a type of AI system that can create realistic images and 3D shapes.
The core idea is to reparameterize, or redefine, how the diffusion model works. This makes the training and generation process more efficient and stable, allowing the model to create higher-quality 3D content from text inputs.
Rather than having to start from scratch, the model can build on the strengths of existing diffusion techniques like DDIM. By tweaking the underlying mathematical formulation, the researchers were able to improve the performance and capabilities of this type of generative AI system.
The end result is a system that can take natural language descriptions and turn them into detailed, realistic 3D models and objects. This could have applications in areas like 3D content generation, product design, virtual environments, and more.
Technical Explanation
The key technical contribution of this paper is a novel reparametrization of the DDIM framework, which the authors call "Score Distillation via Reparametrized DDIM" (SD-DDIM).
DDIM is a class of diffusion models that can generate high-quality images and 3D content by learning to reverse a noising process. The reparametrization in SD-DDIM involves modifying the underlying mathematical formulation to make the training and generation more efficient and stable.
Specifically, the authors introduce a new parameterization of the reverse diffusion process that decouples the score function (which captures the gradients of the data distribution) from the diffusion process itself. This allows the model to better leverage the score function during training and generation, leading to improved sample quality and diversity.
The authors demonstrate the effectiveness of SD-DDIM on several 3D generation tasks, including text-to-3D and one-shot 3D generation. Compared to baseline DDIM models, their reparametrized approach shows significant improvements in metrics like Chamfer distance and Inception Score.
Critical Analysis
The paper presents a compelling technical advancement in the field of diffusion-based 3D generation. The reparametrization of DDIM is a clever idea that addresses some of the known challenges with training and using these types of models.
One potential limitation is that the paper focuses primarily on evaluating the model's performance on synthetic 3D datasets. It would be interesting to see how well SD-DDIM performs on more diverse, real-world 3D data, such as scanned objects or CAD models. The generalization capabilities of the model could be further explored in this context.
Additionally, the paper does not provide much insight into the failure modes or limitations of the SD-DDIM approach. It would be valuable to understand the types of 3D content that are challenging for the model to generate, or any potential biases that may arise.
Overall, this research represents an important advancement in the field of diffusion-based 3D generation, with the reparametrized DDIM model showing promising results. As the authors note, further investigation into the theoretical properties and practical applications of this technique could lead to even more exciting developments in this space.
Conclusion
This paper introduces a novel reparametrization of the DDIM framework, called SD-DDIM, that improves the efficiency and stability of diffusion-based 3D content generation. By decoupling the score function from the diffusion process, the authors were able to create a more powerful and versatile generative model.
The demonstrated improvements in 3D generation tasks, such as text-to-3D and one-shot 3D generation, suggest that SD-DDIM could have a significant impact on applications that require the creation of high-quality 3D content from diverse inputs. As diffusion models continue to advance, techniques like this reparametrization will be crucial for unlocking the full potential of these generative systems.
Looking ahead, further research on the theoretical underpinnings of SD-DDIM, as well as its performance on real-world 3D data, could lead to even more exciting developments in the field of 3D content generation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Flow Score Distillation for Diverse Text-to-3D Generation
Runjie Yan, Kailu Wu, Kaisheng Ma
0
0
Recent advancements in Text-to-3D generation have yielded remarkable progress, particularly through methods that rely on Score Distillation Sampling (SDS). While SDS exhibits the capability to create impressive 3D assets, it is hindered by its inherent maximum-likelihood-seeking essence, resulting in limited diversity in generation outcomes. In this paper, we discover that the Denoise Diffusion Implicit Models (DDIM) generation process (ie PF-ODE) can be succinctly expressed using an analogue of SDS loss. One step further, one can see SDS as a generalized DDIM generation process. Following this insight, we show that the noise sampling strategy in the noise addition stage significantly restricts the diversity of generation results. To address this limitation, we present an innovative noise sampling approach and introduce a novel text-to-3D method called Flow Score Distillation (FSD). Our validation experiments across various text-to-image Diffusion Models demonstrate that FSD substantially enhances generation diversity without compromising quality.
5/21/2024
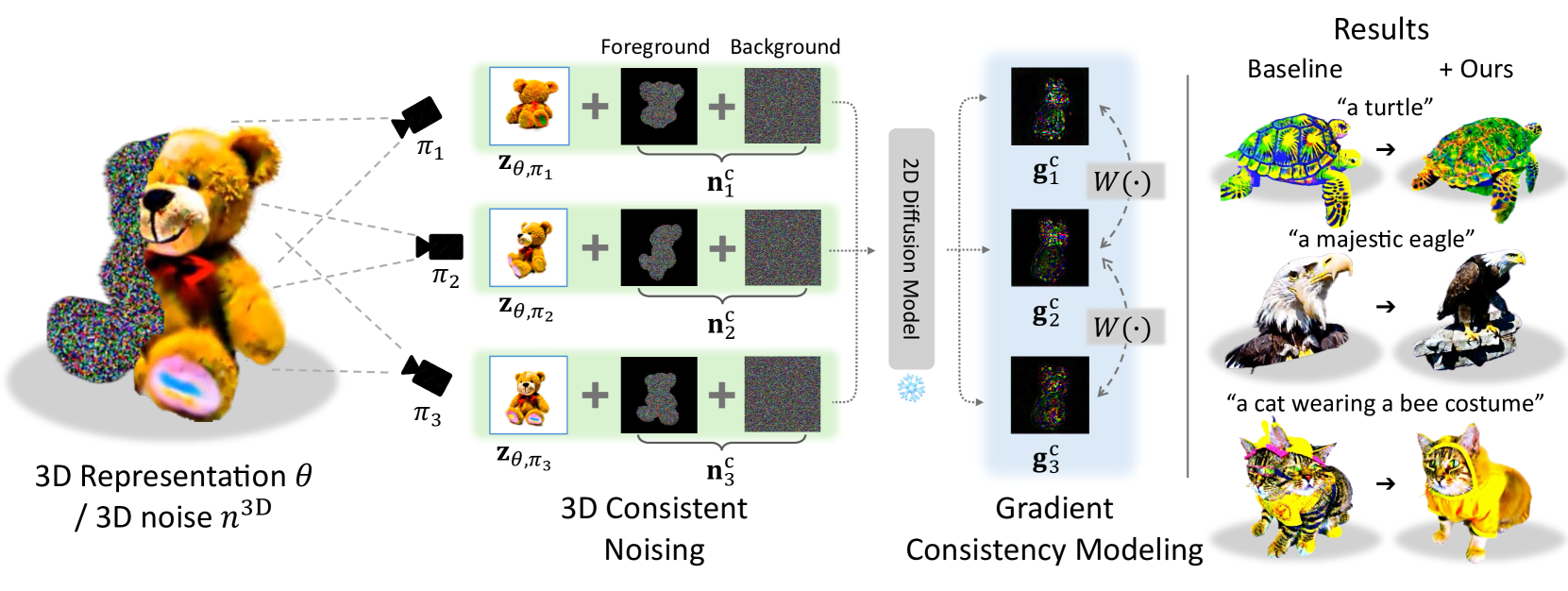
Geometry-Aware Score Distillation via 3D Consistent Noising and Gradient Consistency Modeling
Min-Seop Kwak, Donghoon Ahn, Ines Hyeonsu Kim, Jin-Hwa Kim, Seungryong Kim
0
0
Score distillation sampling (SDS), the methodology in which the score from pretrained 2D diffusion models is distilled into 3D representation, has recently brought significant advancements in text-to-3D generation task. However, this approach is still confronted with critical geometric inconsistency problems such as the Janus problem. Starting from a hypothesis that such inconsistency problems may be induced by multiview inconsistencies between 2D scores predicted from various viewpoints, we introduce GSD, a simple and general plug-and-play framework for incorporating 3D consistency and therefore geometry awareness into the SDS process. Our methodology is composed of three components: 3D consistent noising, designed to produce 3D consistent noise maps that perfectly follow the standard Gaussian distribution, geometry-based gradient warping for identifying correspondences between predicted gradients of different viewpoints, and novel gradient consistency loss to optimize the scene geometry toward producing more consistent gradients. We demonstrate that our method significantly improves performance, successfully addressing the geometric inconsistency problems in text-to-3D generation task with minimal computation cost and being compatible with existing score distillation-based models. Our project page is available at https://ku-cvlab.github.io/GSD/.
7/2/2024
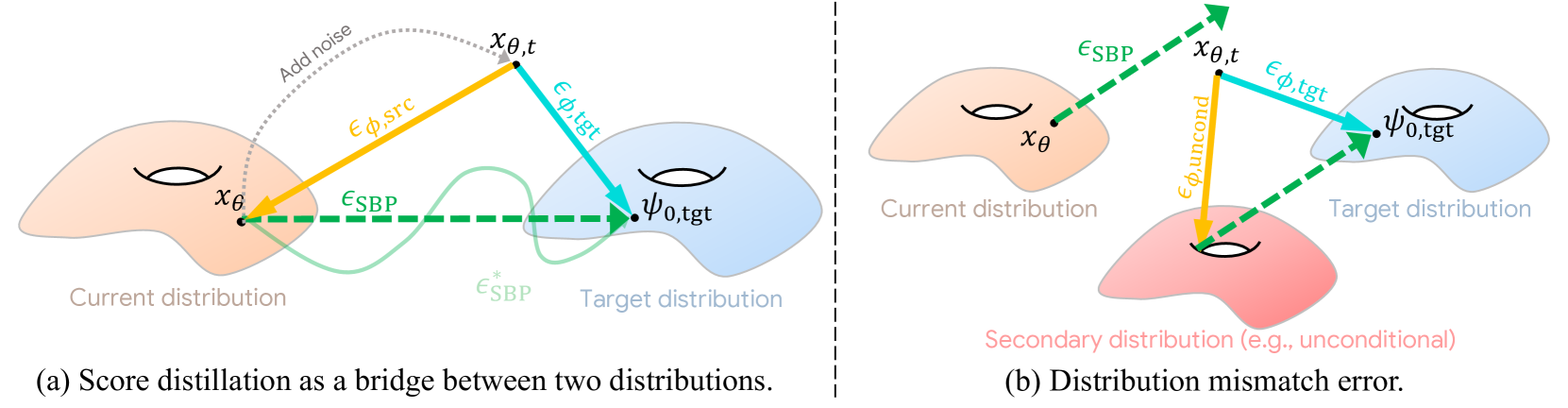
Rethinking Score Distillation as a Bridge Between Image Distributions
David McAllister, Songwei Ge, Jia-Bin Huang, David W. Jacobs, Alexei A. Efros, Aleksander Holynski, Angjoo Kanazawa
0
0
Score distillation sampling (SDS) has proven to be an important tool, enabling the use of large-scale diffusion priors for tasks operating in data-poor domains. Unfortunately, SDS has a number of characteristic artifacts that limit its usefulness in general-purpose applications. In this paper, we make progress toward understanding the behavior of SDS and its variants by viewing them as solving an optimal-cost transport path from a source distribution to a target distribution. Under this new interpretation, these methods seek to transport corrupted images (source) to the natural image distribution (target). We argue that current methods' characteristic artifacts are caused by (1) linear approximation of the optimal path and (2) poor estimates of the source distribution. We show that calibrating the text conditioning of the source distribution can produce high-quality generation and translation results with little extra overhead. Our method can be easily applied across many domains, matching or beating the performance of specialized methods. We demonstrate its utility in text-to-2D, text-based NeRF optimization, translating paintings to real images, optical illusion generation, and 3D sketch-to-real. We compare our method to existing approaches for score distillation sampling and show that it can produce high-frequency details with realistic colors.
6/14/2024
🌿
Repulsive Score Distillation for Diverse Sampling of Diffusion Models
Nicolas Zilberstein, Morteza Mardani, Santiago Segarra
0
0
Score distillation sampling has been pivotal for integrating diffusion models into generation of complex visuals. Despite impressive results it suffers from mode collapse and lack of diversity. To cope with this challenge, we leverage the gradient flow interpretation of score distillation to propose Repulsive Score Distillation (RSD). In particular, we propose a variational framework based on repulsion of an ensemble of particles that promotes diversity. Using a variational approximation that incorporates a coupling among particles, the repulsion appears as a simple regularization that allows interaction of particles based on their relative pairwise similarity, measured e.g., via radial basis kernels. We design RSD for both unconstrained and constrained sampling scenarios. For constrained sampling we focus on inverse problems in the latent space that leads to an augmented variational formulation, that strikes a good balance between compute, quality and diversity. Our extensive experiments for text-to-image generation, and inverse problems demonstrate that RSD achieves a superior trade-off between diversity and quality compared with state-of-the-art alternatives.
6/26/2024