RetinaQA: A Robust Knowledge Base Question Answering Model for both Answerable and Unanswerable Questions

0
📈
Sign in to get full access
Overview
- This paper presents a "Responsible NLP Research Checklist" - a set of guidelines for researchers to consider when publishing natural language processing (NLP) papers.
- The checklist covers aspects such as discussing the limitations and potential risks of the work, considering ethical implications, and making data and models publicly available.
- The goal is to promote responsible and ethical NLP research that is transparent about potential issues and negative societal impacts.
Plain English Explanation
The paper provides a checklist of important considerations for researchers working on natural language processing (NLP) projects. The aim is to encourage more responsible and transparent research practices in this field.
Some key points from the checklist include:
- <a href="https://aimodels.fyi/papers/arxiv/precision-empowers-excess-distracts-visual-question-answering">Discussing the limitations of your work</a> - being upfront about what your system can and cannot do, and acknowledging areas for improvement.
- <a href="https://aimodels.fyi/papers/arxiv/unk-vqa-dataset-probe-into-abstention-ability">Discussing potential risks or negative impacts</a> - thinking critically about how your technology could be misused or have unintended consequences.
- Considering ethical implications - evaluating whether your research raises any ethical concerns and how those might be addressed.
- Making data and models publicly available - allowing others to audit and build upon your work, rather than keeping everything private.
The overall message is that NLP researchers should go beyond just showcasing their technical achievements. They should also thoughtfully examine the broader implications of their work and be transparent about its limitations and potential downsides. This can help ensure NLP technology is developed in a way that benefits society.
Technical Explanation
The paper outlines a "Responsible NLP Research Checklist" that researchers are encouraged to consider when preparing NLP papers for publication. The checklist covers several key areas:
<a href="https://aimodels.fyi/papers/arxiv/find-gap-knowledge-base-reasoning-visual-question">Limitations and risks:</a> Researchers are asked to discuss the limitations of their work, such as performance issues or biases in the data or model. They should also consider and disclose any potential risks or negative societal impacts that could arise from the deployment of their technology.
Ethical considerations: The checklist prompts researchers to reflect on the ethical implications of their work, such as privacy concerns, fairness and non-discrimination, and potential for misuse. They should outline steps taken to mitigate ethical risks.
Transparency and reproducibility: Researchers are encouraged to make their data, models, and code publicly available to enable auditing and further research. They should also provide detailed documentation of their experimental setup and evaluation methodology.
The goal of this checklist is to foster more responsible and thoughtful NLP research that goes beyond just technical innovation. By being upfront about limitations and risks, considering ethical ramifications, and enabling transparency and reproducibility, the authors hope to promote NLP development that better serves the public good.
Critical Analysis
The "Responsible NLP Research Checklist" proposed in this paper is a positive step towards encouraging more ethical and transparent practices in the field of natural language processing. By prompting researchers to critically examine the societal implications of their work, it aims to mitigate potential harms and unintended consequences.
<a href="https://aimodels.fyi/papers/arxiv/chatkbqa-generate-then-retrieve-framework-knowledge-base">That said, the checklist does not go into deep detail on how researchers should actually go about identifying and addressing ethical concerns</a>. More guidance on ethical frameworks, stakeholder engagement, and impact assessment methodologies would strengthen the practical utility of the recommendations.
Additionally, the checklist focuses primarily on the publication stage, but responsible research practices should ideally be integrated throughout the entire research and development lifecycle. Extending the principles to earlier phases like problem formulation and experimental design could further bolster the positive impact.
<a href="https://aimodels.fyi/papers/arxiv/retrieval-augmented-generation-domain-specific-question-answering">While the authors acknowledge that their checklist may not be exhaustive, additional considerations around data provenance, model interpretability, and algorithmic mitigation of biases could round out the guidance</a>. Continual refinement of the checklist based on community feedback would also help ensure its relevance as the field of NLP rapidly evolves.
Overall, this paper makes a valuable contribution by bringing ethical and responsible research practices to the forefront of NLP. Wider adoption of such guidelines has the potential to shape the development of NLP technologies in a way that better serves the public interest.
Conclusion
The "Responsible NLP Research Checklist" outlined in this paper represents an important step towards promoting more ethical and transparent practices in the field of natural language processing. By prompting researchers to critically examine the limitations, risks, and societal implications of their work, it aims to minimize potential harms and unintended consequences.
While the checklist provides a solid foundation, there is room for further refinement and expansion to address additional ethical considerations and integrate responsible practices throughout the entire research lifecycle. Nonetheless, widespread adoption of such guidelines has the potential to steer the development of NLP technologies in a direction that better serves the public good.
As the capabilities and real-world impact of NLP systems continue to grow, it is crucial that the research community remains vigilant and proactive in addressing the ethical challenges. This paper's Responsible NLP Research Checklist is a valuable contribution towards that important goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
RetinaQA: A Robust Knowledge Base Question Answering Model for both Answerable and Unanswerable Questions
Prayushi Faldu, Indrajit Bhattacharya, Mausam
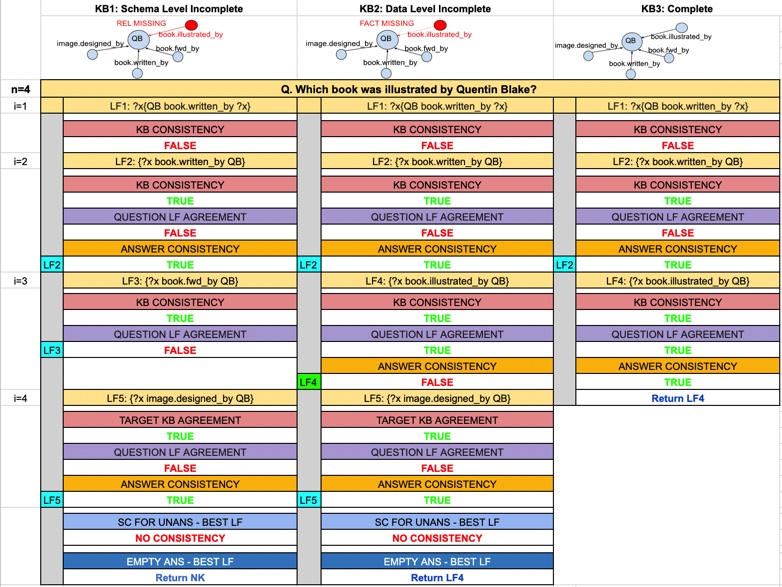
An essential requirement for a real-world Knowledge Base Question Answering (KBQA) system is the ability to detect answerability of questions when generating logical forms. However, state-of-the-art KBQA models assume all questions to be answerable. Recent research has found that such models, when superficially adapted to detect answerability, struggle to satisfactorily identify the different categories of unanswerable questions, and simultaneously preserve good performance for answerable questions. Towards addressing this issue, we propose RetinaQA, a new KBQA model that unifies two key ideas in a single KBQA architecture: (a) discrimination over candidate logical forms, rather than generating these, for handling schema-related unanswerability, and (b) sketch-filling-based construction of candidate logical forms for handling data-related unaswerability. Our results show that RetinaQA significantly outperforms adaptations of state-of-the-art KBQA models in handling both answerable and unanswerable questions and demonstrates robustness across all categories of unanswerability. Notably, RetinaQA also sets a new state-of-the-art for answerable KBQA, surpassing existing models.
Read more6/18/2024
0
Robust Few-shot Transfer Learning for Knowledge Base Question Answering with Unanswerable Questions
Riya Sawhney, Indrajit Bhattacharya, Mausam
Real-world KBQA applications require models that are (1) robust -- e.g., can differentiate between answerable and unanswerable questions, and (2) low-resource -- do not require large training data. Towards this goal, we propose the novel task of few-shot transfer for KBQA with unanswerable questions. We present FUn-FuSIC that extends the state-of-the-art (SoTA) few-shot transfer model for answerable-only KBQA to handle unanswerability. It iteratively prompts an LLM to generate logical forms for the question by providing feedback using a diverse suite of syntactic, semantic and execution guided checks, and adapts self-consistency to assess confidence of the LLM to decide answerability. Experiments over newly constructed datasets show that FUn-FuSIC outperforms suitable adaptations of the SoTA model for KBQA with unanswerability, and the SoTA model for answerable-only few-shot-transfer KBQA.
Read more6/21/2024

0
UNK-VQA: A Dataset and a Probe into the Abstention Ability of Multi-modal Large Models
Yangyang Guo, Fangkai Jiao, Zhiqi Shen, Liqiang Nie, Mohan Kankanhalli
Teaching Visual Question Answering (VQA) models to refrain from answering unanswerable questions is necessary for building a trustworthy AI system. Existing studies, though have explored various aspects of VQA but somewhat ignored this particular attribute. This paper aims to bridge the research gap by contributing a comprehensive dataset, called UNK-VQA. The dataset is specifically designed to address the challenge of questions that models do not know. To this end, we first augment the existing data via deliberate perturbations on either the image or question. In specific, we carefully ensure that the question-image semantics remain close to the original unperturbed distribution. By this means, the identification of unanswerable questions becomes challenging, setting our dataset apart from others that involve mere image replacement. We then extensively evaluate the zero- and few-shot performance of several emerging multi-modal large models and discover their significant limitations when applied to our dataset. Additionally, we also propose a straightforward method to tackle these unanswerable questions. This dataset, we believe, will serve as a valuable benchmark for enhancing the abstention capability of VQA models, thereby leading to increased trustworthiness of AI systems. We have made the dataset (https://github.com/guoyang9/UNK-VQA) available to facilitate further exploration in this area.
Read more8/13/2024

0
Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
Read more6/17/2024