Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
2406.09994
0
0

Abstract
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
Create account to get full access
Overview
- This paper explores a novel approach to visual question answering (VQA) that dynamically infuses knowledge into language models.
- The key idea is to strike a balance between precision and excess when incorporating external knowledge, in order to improve VQA performance.
- The proposed method aims to address the challenges of finding the right amount of relevant knowledge to include, without overwhelming the model with irrelevant information.
Plain English Explanation
Visual question answering (VQA) is a task where an AI system is shown an image and asked a question about it, and the system has to provide the correct answer. This can be a challenging task, as the system needs to understand both the visual information in the image and the meaning of the question in order to generate a relevant response.
To help the AI system perform better at VQA, this paper explores a new approach that dynamically infuses knowledge from external sources into the language model used for the task. The key insight is that adding too much knowledge can actually be detrimental, as it can distract the model and make it harder to focus on the most relevant information. Instead, the goal is to find the right balance, where the model is empowered with just the right amount of precise, targeted knowledge to help it answer the questions accurately.
The researchers propose a novel method to achieve this balance, which involves dynamically selecting and incorporating the most relevant knowledge into the language model as it processes each question and image. By carefully controlling the amount and specificity of the knowledge used, the model is able to maintain its focus and provide more accurate answers.
Technical Explanation
The paper introduces a new VQA approach called DINK (Dynamically Infused Knowledge), which aims to address the challenge of effectively incorporating external knowledge into language models for improved VQA performance.
The key components of DINK are:
-
Knowledge Retrieval: The system dynamically retrieves relevant knowledge from a knowledge base (e.g., Find-Gap, KVQA) based on the current question and image.
-
Knowledge Infusion: The retrieved knowledge is then infused into the language model using techniques such as knowledge-driven attention and bridge-based reasoning.
-
Dynamic Control: The system dynamically controls the amount and specificity of the infused knowledge to strike a balance between precision and excess, in order to prevent the model from being overwhelmed by irrelevant information.
The paper evaluates DINK on several VQA benchmarks and demonstrates significant performance improvements over state-of-the-art VQA models. The results suggest that the dynamic and targeted approach to knowledge infusion can effectively enhance the language model's understanding and reasoning capabilities for visual question answering.
Critical Analysis
The paper presents a well-designed and comprehensive approach to addressing the challenge of incorporating external knowledge into VQA models. The authors have carefully considered the potential pitfalls of excessive knowledge infusion and have developed a dynamic control mechanism to mitigate these issues.
One potential limitation of the approach is the reliance on the quality and coverage of the underlying knowledge base. If the knowledge base does not contain the necessary information to answer a given question, the model may still struggle, despite the dynamic infusion mechanism. The authors acknowledge this and suggest exploring techniques to expand the knowledge base or to dynamically generate relevant knowledge as needed.
Another area for further research could be the exploration of more advanced knowledge infusion strategies, such as incorporating commonsense reasoning or using more sophisticated language models that can better handle and reason with the infused knowledge.
Overall, the paper presents a promising and well-executed approach to enhancing VQA models through the dynamic and targeted incorporation of external knowledge. The findings and insights provided in this work could have significant implications for the broader field of multimodal AI and visual understanding.
Conclusion
This paper introduces a novel approach to visual question answering called DINK, which dynamically infuses relevant knowledge into language models to improve their performance. The key insight is that while external knowledge can be beneficial for VQA, it needs to be carefully controlled to avoid overwhelming the model with irrelevant information.
The DINK approach addresses this challenge by dynamically retrieving and infusing the most relevant knowledge into the language model, using techniques such as knowledge-driven attention and bridge-based reasoning. The dynamic control mechanism ensures that the amount and specificity of the infused knowledge is optimized to strike the right balance between precision and excess.
The results of the experiments conducted in this paper demonstrate the effectiveness of the DINK approach, with significant performance improvements over state-of-the-art VQA models. These findings have important implications for the ongoing development of multimodal AI systems, suggesting that the careful and targeted integration of external knowledge can be a powerful tool for enhancing visual understanding and reasoning capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
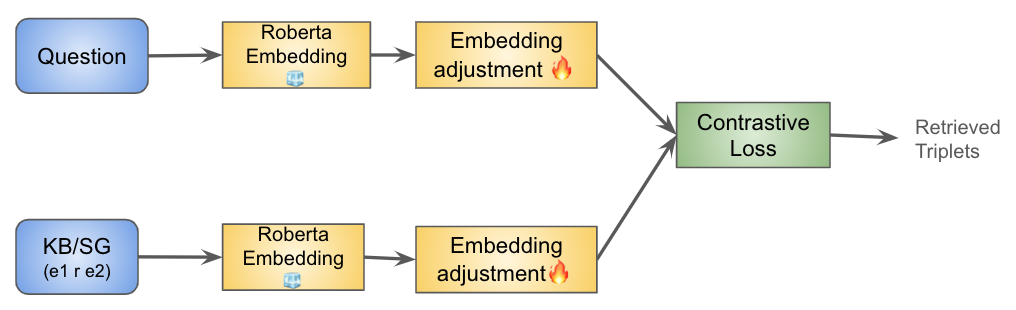
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024

Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
Ovgu Ozdemir, Erdem Akagunduz
0
0
Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at url{https://github.com/ovguyo/captions-in-VQA}.
4/15/2024

Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
Kaavya Rekanar, Martin Hayes, Ganesh Sistu, Ciaran Eising
0
0
Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
6/14/2024

New!Disentangling Knowledge-based and Visual Reasoning by Question Decomposition in KB-VQA
Elham J. Barezi, Parisa Kordjamshidi
0
0
We study the Knowledge-Based visual question-answering problem, for which given a question, the models need to ground it into the visual modality to find the answer. Although many recent works use question-dependent captioners to verbalize the given image and use Large Language Models to solve the VQA problem, the research results show they are not reasonably performing for multi-hop questions. Our study shows that replacing a complex question with several simpler questions helps to extract more relevant information from the image and provide a stronger comprehension of it. Moreover, we analyze the decomposed questions to find out the modality of the information that is required to answer them and use a captioner for the visual questions and LLMs as a general knowledge source for the non-visual KB-based questions. Our results demonstrate the positive impact of using simple questions before retrieving visual or non-visual information. We have provided results and analysis on three well-known VQA datasets including OKVQA, A-OKVQA, and KRVQA, and achieved up to 2% improvement in accuracy.
6/28/2024