Retrieval-Augmented Audio Deepfake Detection

0

Sign in to get full access
Overview
- This paper proposes a novel approach to audio deepfake detection called Retrieval-Augmented Audio Deepfake Detection (RADD).
- The key idea is to leverage large language models (LLMs) and retrieval systems to enhance the performance of deepfake detection models.
- The authors conduct extensive experiments on various datasets to evaluate the effectiveness of their RADD approach compared to traditional deepfake detection methods.
Plain English Explanation
The paper discusses a new way to detect audio deepfakes, which are fake audio recordings created using advanced AI and machine learning techniques. Traditional deepfake detection methods often struggle to keep up with the rapidly evolving deepfake technology.
The researchers propose a solution called Retrieval-Augmented Audio Deepfake Detection (RADD). The core idea is to use large language models (LLMs) and information retrieval systems to enhance the performance of deepfake detection models. LLMs are powerful AI models trained on vast amounts of text data, which can provide valuable contextual information to aid in detecting deepfakes.
The RADD approach works by first using the LLM to generate relevant text based on the input audio. This text is then used to retrieve similar audio samples from a reference database. The detection model can then compare the input audio to the retrieved samples to identify potential deepfakes.
The authors evaluate RADD on various datasets and show that it outperforms traditional deepfake detection methods. By combining the strengths of LLMs, retrieval systems, and detection models, RADD demonstrates a more robust and effective way to combat the growing threat of audio deepfakes.
Technical Explanation
The paper proposes a Retrieval-Augmented Audio Deepfake Detection (RADD) framework that leverages large language models (LLMs) and retrieval systems to enhance the performance of deepfake detection models.
The traditional deepfake detection approach typically relies on training a standalone detection model using labeled deepfake and real audio samples. However, as deepfake technology rapidly evolves, these models can struggle to generalize to new types of deepfakes.
The RADD framework aims to address this issue by incorporating additional contextual information from LLMs and retrieval systems. First, the input audio is passed through an LLM to generate relevant text. This text is then used to retrieve similar audio samples from a reference database using an information retrieval system.
The retrieved audio samples are then used in combination with the input audio to train a deepfake detection model. By learning to compare the input audio to the retrieved samples, the detection model can better distinguish real from fake audio.
The authors conduct extensive experiments on various datasets, including the VCTK and LibriSpeech datasets, to evaluate the effectiveness of RADD. They compare the performance of RADD to traditional deepfake detection methods and demonstrate significant improvements in detection accuracy.
Critical Analysis
The paper presents a compelling approach to audio deepfake detection, but it also acknowledges several limitations and areas for further research.
One potential concern is the reliance on a reference database of audio samples. The performance of the retrieval system and the quality of the reference data can significantly impact the overall effectiveness of RADD. The authors suggest exploring techniques to automatically expand and curate the reference database, but this remains an open challenge.
Additionally, the paper focuses on audio-only deepfakes and does not address the detection of more complex, multimodal deepfakes that combine audio and visual elements. Extending the RADD framework to handle such cases could be an important area for future research.
The authors also note that the computational overhead of the RADD approach, particularly due to the LLM and retrieval components, may limit its practical deployment in real-time scenarios. Optimizing the system's efficiency or exploring more lightweight alternatives could help address this limitation.
Conclusion
The Retrieval-Augmented Audio Deepfake Detection (RADD) framework proposed in this paper represents a promising advance in the ongoing battle against audio deepfakes. By leveraging the strengths of large language models and retrieval systems, the authors have demonstrated a more robust and effective approach to deepfake detection compared to traditional methods.
While the paper identifies several areas for further research and optimization, the core RADD concept holds significant potential to help safeguard against the growing threat of AI-generated fake audio content. As deepfake technology continues to evolve, innovative solutions like RADD will be crucial in maintaining trust and integrity in our digital communications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Retrieval-Augmented Audio Deepfake Detection
Zuheng Kang, Yayun He, Botao Zhao, Xiaoyang Qu, Junqing Peng, Jing Xiao, Jianzong Wang
With recent advances in speech synthesis including text-to-speech (TTS) and voice conversion (VC) systems enabling the generation of ultra-realistic audio deepfakes, there is growing concern about their potential misuse. However, most deepfake (DF) detection methods rely solely on the fuzzy knowledge learned by a single model, resulting in performance bottlenecks and transparency issues. Inspired by retrieval-augmented generation (RAG), we propose a retrieval-augmented detection (RAD) framework that augments test samples with similar retrieved samples for enhanced detection. We also extend the multi-fusion attentive classifier to integrate it with our proposed RAD framework. Extensive experiments show the superior performance of the proposed RAD framework over baseline methods, achieving state-of-the-art results on the ASVspoof 2021 DF set and competitive results on the 2019 and 2021 LA sets. Further sample analysis indicates that the retriever consistently retrieves samples mostly from the same speaker with acoustic characteristics highly consistent with the query audio, thereby improving detection performance.
Read more4/24/2024

0
Targeted Augmented Data for Audio Deepfake Detection
Marcella Astrid, Enjie Ghorbel, Djamila Aouada
The availability of highly convincing audio deepfake generators highlights the need for designing robust audio deepfake detectors. Existing works often rely solely on real and fake data available in the training set, which may lead to overfitting, thereby reducing the robustness to unseen manipulations. To enhance the generalization capabilities of audio deepfake detectors, we propose a novel augmentation method for generating audio pseudo-fakes targeting the decision boundary of the model. Inspired by adversarial attacks, we perturb original real data to synthesize pseudo-fakes with ambiguous prediction probabilities. Comprehensive experiments on two well-known architectures demonstrate that the proposed augmentation contributes to improving the generalization capabilities of these architectures.
Read more7/11/2024

0
FakeSound: Deepfake General Audio Detection
Zeyu Xie, Baihan Li, Xuenan Xu, Zheng Liang, Kai Yu, Mengyue Wu
With the advancement of audio generation, generative models can produce highly realistic audios. However, the proliferation of deepfake general audio can pose negative consequences. Therefore, we propose a new task, deepfake general audio detection, which aims to identify whether audio content is manipulated and to locate deepfake regions. Leveraging an automated manipulation pipeline, a dataset named FakeSound for deepfake general audio detection is proposed, and samples can be viewed on website https://FakeSoundData.github.io. The average binary accuracy of humans on all test sets is consistently below 0.6, which indicates the difficulty humans face in discerning deepfake audio and affirms the efficacy of the FakeSound dataset. A deepfake detection model utilizing a general audio pre-trained model is proposed as a benchmark system. Experimental results demonstrate that the performance of the proposed model surpasses the state-of-the-art in deepfake speech detection and human testers.
Read more6/13/2024
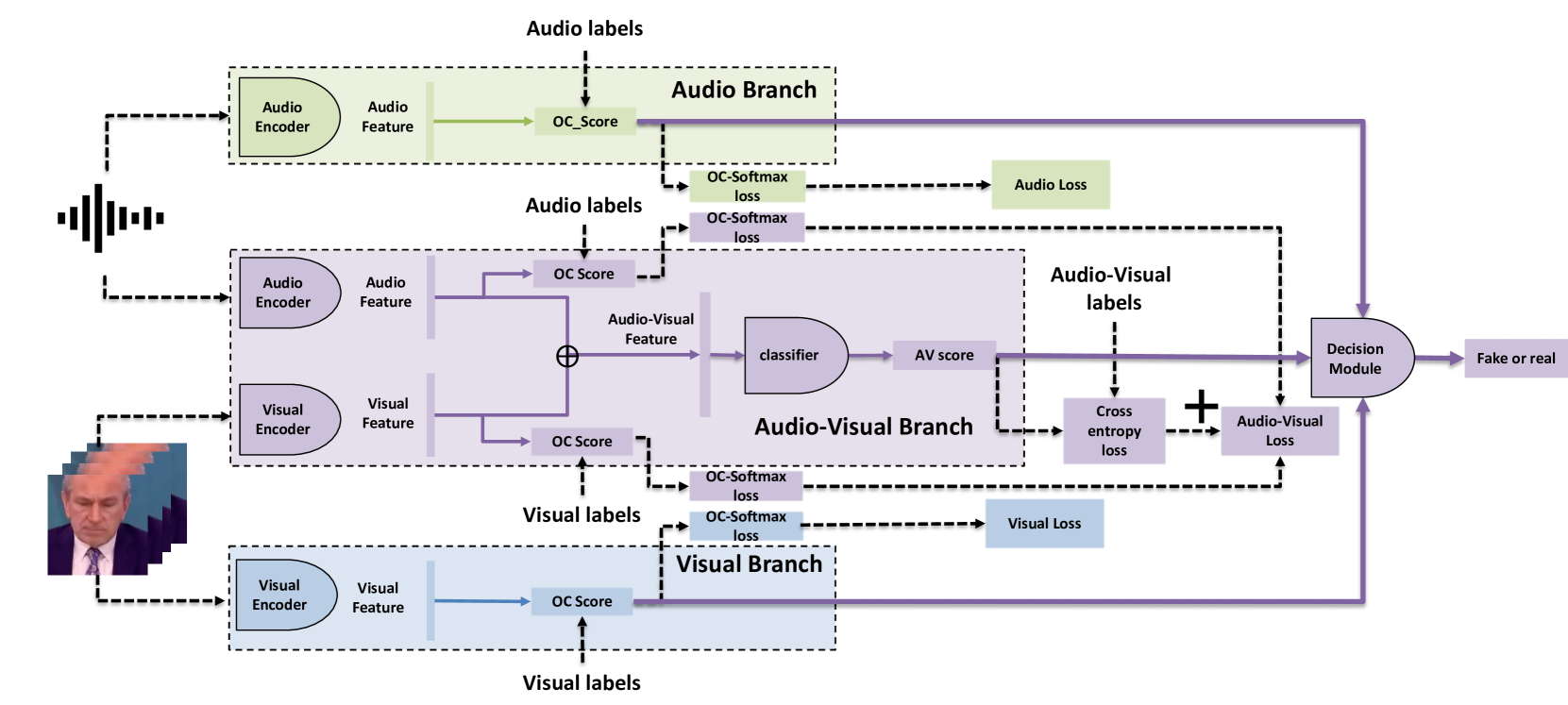
0
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024