Retrieval-augmented generation in multilingual settings
2407.01463
0
0
🛸
Abstract
Retrieval-augmented generation (RAG) has recently emerged as a promising solution for incorporating up-to-date or domain-specific knowledge into large language models (LLMs) and improving LLM factuality, but is predominantly studied in English-only settings. In this work, we consider RAG in the multilingual setting (mRAG), i.e. with user queries and the datastore in 13 languages, and investigate which components and with which adjustments are needed to build a well-performing mRAG pipeline, that can be used as a strong baseline in future works. Our findings highlight that despite the availability of high-quality off-the-shelf multilingual retrievers and generators, task-specific prompt engineering is needed to enable generation in user languages. Moreover, current evaluation metrics need adjustments for multilingual setting, to account for variations in spelling named entities. The main limitations to be addressed in future works include frequent code-switching in non-Latin alphabet languages, occasional fluency errors, wrong reading of the provided documents, or irrelevant retrieval. We release the code for the resulting mRAG baseline pipeline at https://github.com/naver/bergen.
Create account to get full access
Overview
- This paper introduces a Retrieval-Augmented Generation (RAG) pipeline for multilingual text generation tasks.
- The approach combines a large language model with a retrieval system to enhance performance on multilingual tasks.
- The authors evaluate their method on several multilingual benchmarks, including translation, summarization, and question answering.
Plain English Explanation
The paper presents a new approach for text generation in multiple languages, called Retrieval-Augmented Generation (RAG). This method combines a powerful language model, which is trained on a large amount of text data, with a retrieval system that can find relevant information from a database.
The key idea is that by retrieving and incorporating relevant information from the database, the language model can produce better quality text in different languages. For example, when generating a summary in French, the system can retrieve related information in French to help guide the summary writing process.
The authors evaluate their RAG approach on several benchmarks that test multilingual abilities, such as translating text between languages, summarizing articles, and answering questions. The results show that the RAG model outperforms language models that don't use retrieval, demonstrating the benefits of this retrieval-augmented generation approach for multilingual language tasks.
Technical Explanation
The paper introduces a multilingual RAG pipeline that combines a large pre-trained language model with a retrieval system. The language model is used to generate the output text, while the retrieval system provides relevant information to guide the generation process.
The retrieval system consists of an index of text passages from a multilingual corpus. During generation, the model retrieves the most relevant passages from the index based on the input text. These retrieved passages are then encoded and concatenated with the language model's input, allowing the model to condition its generation on the retrieved information.
The authors evaluate their RAG approach on three multilingual benchmarks: translation, summarization, and question answering. The results show that the multilingual RAG model outperforms strong baselines, including monolingual RAG models and large language models without retrieval.
Critical Analysis
The paper presents a compelling approach for enhancing large language models with retrieval capabilities, particularly in the context of multilingual tasks. The authors provide a thorough evaluation of their RAG pipeline on several benchmarks, demonstrating the benefits of this technique.
However, the paper does not delve deeply into the limitations of the approach. For example, the retrieval system's performance and coverage of the multilingual corpus could be potential bottlenecks, especially for less-resourced languages. Additionally, the computational overhead of the retrieval process may impact the overall efficiency of the system.
Further research could explore ways to improve the retrieval-augmented generation process, such as by developing more efficient retrieval mechanisms or investigating how to better integrate the retrieved information with the language model's generation. Exploring the multi-source retrieval and collaborative retrieval-augmented generation approaches could also yield interesting insights.
Conclusion
This paper presents a novel Retrieval-Augmented Generation (RAG) pipeline for multilingual text generation tasks. By combining a large language model with a retrieval system, the authors demonstrate significant improvements over language models alone on translation, summarization, and question answering benchmarks.
The RAG approach highlights the potential of empowering large language models with external knowledge sources to enhance their performance, especially in multilingual settings. While the paper identifies some areas for further research, it serves as an important step towards developing more robust and capable multilingual language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
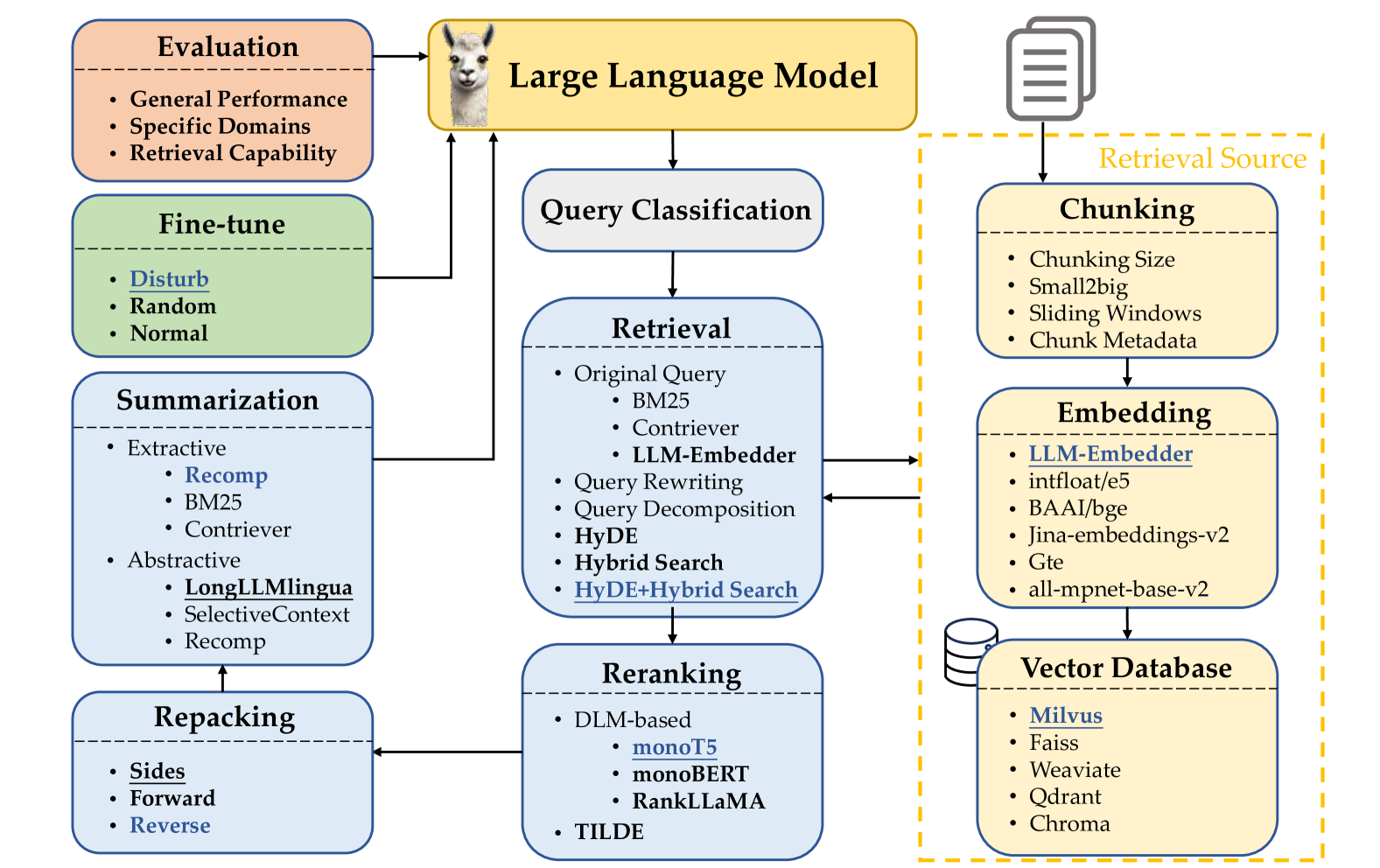
Searching for Best Practices in Retrieval-Augmented Generation
Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang, Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li, Qi Qian, Ruicheng Yin, Changze Lv, Xiaoqing Zheng, Xuanjing Huang
0
0
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a retrieval as generation strategy.
7/2/2024

M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions
Zheng Wang, Shu Xian Teo, Jieer Ouyang, Yongjun Xu, Wei Shi
0
0
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant memories from an external database. However, existing RAG methods typically organize all memories in a whole database, potentially limiting focus on crucial memories and introducing noise. In this paper, we introduce a multiple partition paradigm for RAG (called M-RAG), where each database partition serves as a basic unit for RAG execution. Based on this paradigm, we propose a novel framework that leverages LLMs with Multi-Agent Reinforcement Learning to optimize different language generation tasks explicitly. Through comprehensive experiments conducted on seven datasets, spanning three language generation tasks and involving three distinct language model architectures, we confirm that M-RAG consistently outperforms various baseline methods, achieving improvements of 11%, 8%, and 12% for text summarization, machine translation, and dialogue generation, respectively.
5/28/2024
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024