Retrieval-Oriented Knowledge for Click-Through Rate Prediction

0
🔮
Sign in to get full access
Overview
- Click-through rate (CTR) prediction is crucial for personalized recommendations
- Recent retrieval-based models like RIM have shown impressive performance by retrieving and aggregating relevant samples
- However, these models are inefficient during inference, making them impractical for industrial applications
- This paper proposes a Retrieval-Oriented Knowledge (ROK) framework to address this issue
Plain English Explanation
When you browse online, the websites you visit often try to show you personalized recommendations based on your interests and browsing history. Click-through rate (CTR) prediction is the process of estimating how likely you are to click on a recommended item. Getting these predictions right is crucial for providing useful and engaging recommendations.
Recently, a new type of model called retrieval-based models has shown great success in CTR prediction. These models work by finding and combining relevant samples from a large dataset to make their predictions. One example is the RIM model, which has achieved impressive performance.
However, these retrieval-based models have a major drawback - they are very slow and inefficient when actually making predictions. This makes them impractical for real-world applications, where speed and efficiency are important.
To overcome this issue, the researchers in this paper propose a new framework called Retrieval-Oriented Knowledge (ROK). The key idea is to capture the knowledge learned by the retrieval-based models in a more efficient way, so that their accuracy can be maintained without the slow inference speed.
Technical Explanation
The ROK framework consists of a knowledge base that is designed to preserve and imitate the representations learned by retrieval-based CTR models. This knowledge base has two main components:
- A retrieval-oriented embedding layer that encodes the input features in a way that captures the key information needed for CTR prediction.
- A knowledge encoder that takes these embeddings and produces a concise representation, analogous to the aggregated representations in retrieval-based models.
The knowledge base is trained using knowledge distillation and contrastive learning techniques, which allow it to closely match the behavior of the more complex retrieval-based models.
Once trained, the ROK knowledge base can be easily integrated with any CTR prediction model, either by using its representations directly (instance-wise) or by incorporating them as additional features (feature-wise). This allows the benefits of the retrieval-based approach to be enjoyed without the associated efficiency drawbacks.
Extensive experiments on three large-scale datasets show that the ROK framework can achieve performance on par with state-of-the-art retrieval-based CTR models, while maintaining much faster inference speeds.
Critical Analysis
The ROK framework represents a promising approach to addressing the efficiency limitations of retrieval-based CTR models. By distilling the key knowledge into a more compact and generalizable form, it opens up the possibility of deploying these powerful techniques in real-world recommender systems.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the ROK approach. For example, it's unclear how the framework would handle dynamic or evolving datasets, or how it might scale to extremely large-scale industrial applications.
Additionally, the paper does not explore the interpretability or explainability of the ROK model's predictions. In many practical settings, being able to understand why a recommendation was made is just as important as making an accurate prediction.
Further research could investigate these areas, as well as exploring the potential of the ROK framework for other applications beyond CTR prediction, such as event-enhanced retrieval or reasoning-as-retrieval tasks.
Conclusion
The Retrieval-Oriented Knowledge (ROK) framework proposed in this paper represents an important step forward in making retrieval-based CTR prediction models practical for real-world use. By efficiently capturing and distilling the key knowledge learned by these models, ROK can achieve comparable performance without the heavy computational burden.
This work has implications for the broader field of recommender systems, suggesting that the power of retrieval-based techniques can be harnessed without sacrificing efficiency. As the need for personalized and engaging recommendations continues to grow, innovations like ROK will be crucial for bringing these advanced AI capabilities to a wide range of applications and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Retrieval-Oriented Knowledge for Click-Through Rate Prediction
Huanshuo Liu, Bo Chen, Menghui Zhu, Jianghao Lin, Jiarui Qin, Yang Yang, Hao Zhang, Ruiming Tang
Click-through rate (CTR) prediction plays an important role in personalized recommendations. Recently, sample-level retrieval-based models (e.g., RIM) have achieved remarkable performance by retrieving and aggregating relevant samples. However, their inefficiency at the inference stage makes them impractical for industrial applications. To overcome this issue, this paper proposes a universal plug-and-play Retrieval-Oriented Knowledge (ROK) framework. Specifically, a knowledge base, consisting of a retrieval-oriented embedding layer and a knowledge encoder, is designed to preserve and imitate the retrieved & aggregated representations in a decomposition-reconstruction paradigm. Knowledge distillation and contrastive learning methods are utilized to optimize the knowledge base, and the learned retrieval-enhanced representations can be integrated with arbitrary CTR models in both instance-wise and feature-wise manners. Extensive experiments on three large-scale datasets show that ROK achieves competitive performance with the retrieval-based CTR models while reserving superior inference efficiency and model compatibility.
Read more4/30/2024
0
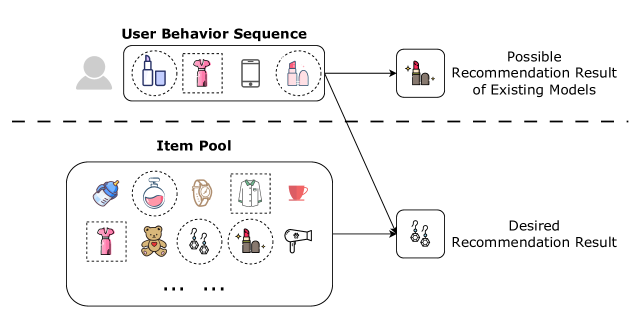
Recall-Augmented Ranking: Enhancing Click-Through Rate Prediction Accuracy with Cross-Stage Data
Junjie Huang, Guohao Cai, Jieming Zhu, Zhenhua Dong, Ruiming Tang, Weinan Zhang, Yong Yu
Click-through rate (CTR) prediction plays an indispensable role in online platforms. Numerous models have been proposed to capture users' shifting preferences by leveraging user behavior sequences. However, these historical sequences often suffer from severe homogeneity and scarcity compared to the extensive item pool. Relying solely on such sequences for user representations is inherently restrictive, as user interests extend beyond the scope of items they have previously engaged with. To address this challenge, we propose a data-driven approach to enrich user representations. We recognize user profiling and recall items as two ideal data sources within the cross-stage framework, encompassing the u2u (user-to-user) and i2i (item-to-item) aspects respectively. In this paper, we propose a novel architecture named Recall-Augmented Ranking (RAR). RAR consists of two key sub-modules, which synergistically gather information from a vast pool of look-alike users and recall items, resulting in enriched user representations. Notably, RAR is orthogonal to many existing CTR models, allowing for consistent performance improvements in a plug-and-play manner. Extensive experiments are conducted, which verify the efficacy and compatibility of RAR against the SOTA methods.
Read more4/16/2024

0
Mutual Learning for Finetuning Click-Through Rate Prediction Models
Ibrahim Can Yilmaz, Said Aldemir
Click-Through Rate (CTR) prediction has become an essential task in digital industries, such as digital advertising or online shopping. Many deep learning-based methods have been implemented and have become state-of-the-art models in the domain. To further improve the performance of CTR models, Knowledge Distillation based approaches have been widely used. However, most of the current CTR prediction models do not have much complex architectures, so it's hard to call one of them 'cumbersome' and the other one 'tiny'. On the other hand, the performance gap is also not very large between complex and simple models. So, distilling knowledge from one model to the other could not be worth the effort. Under these considerations, Mutual Learning could be a better approach, since all the models could be improved mutually. In this paper, we showed how useful the mutual learning algorithm could be when it is between equals. In our experiments on the Criteo and Avazu datasets, the mutual learning algorithm improved the performance of the model by up to 0.66% relative improvement.
Read more6/19/2024
💬
0
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
Jianghao Lin, Bo Chen, Hangyu Wang, Yunjia Xi, Yanru Qu, Xinyi Dai, Kangning Zhang, Ruiming Tang, Yong Yu, Weinan Zhang
Click-through rate (CTR) prediction has become increasingly indispensable for various Internet applications. Traditional CTR models convert the multi-field categorical data into ID features via one-hot encoding, and extract the collaborative signals among features. Such a paradigm suffers from the problem of semantic information loss. Another line of research explores the potential of pretrained language models (PLMs) for CTR prediction by converting input data into textual sentences through hard prompt templates. Although semantic signals are preserved, they generally fail to capture the collaborative information (e.g., feature interactions, pure ID features), not to mention the unacceptable inference overhead brought by the huge model size. In this paper, we aim to model both the semantic knowledge and collaborative knowledge for accurate CTR estimation, and meanwhile address the inference inefficiency issue. To benefit from both worlds and close their gaps, we propose a novel model-agnostic framework (i.e., ClickPrompt), where we incorporate CTR models to generate interaction-aware soft prompts for PLMs. We design a prompt-augmented masked language modeling (PA-MLM) pretraining task, where PLM has to recover the masked tokens based on the language context, as well as the soft prompts generated by CTR model. The collaborative and semantic knowledge from ID and textual features would be explicitly aligned and interacted via the prompt interface. Then, we can either tune the CTR model with PLM for superior performance, or solely tune the CTR model without PLM for inference efficiency. Experiments on four real-world datasets validate the effectiveness of ClickPrompt compared with existing baselines.
Read more6/27/2024