Revealing the Utilized Rank of Subspaces of Learning in Neural Networks

0

Sign in to get full access
Overview
- This paper explores the concept of the "utilized rank" of subspaces in neural networks, which refers to the number of dimensions that the network actually uses to learn a given task.
- The researchers developed a novel method to measure the utilized rank and applied it to various neural network architectures and datasets.
- The findings reveal interesting insights about the underlying structure of neural networks and how they efficiently leverage the available parameter space to learn complex tasks.
Plain English Explanation
Neural networks are powerful machine learning models that can solve a wide range of problems, from image recognition to natural language processing. However, the inner workings of these networks can be quite complex and difficult to understand.
One aspect of neural networks that has been of particular interest to researchers is the "utilized rank" of the subspaces within the network. In simple terms, this refers to the number of dimensions, or directions, that the network actually uses to learn a given task, out of the potentially much larger parameter space available.
The authors of this paper developed a new method to measure the utilized rank of subspaces in neural networks. They applied this technique to various network architectures and datasets, and their findings provide valuable insights into how these models efficiently leverage the available parameter space to learn complex tasks.
For example, the researchers found that neural networks often utilize only a small fraction of the total parameter space, suggesting that there may be opportunities to compress or simplify these models without significantly impacting their performance. Additionally, the authors identified interesting connections between the utilized rank and the low-rank structures that emerge during training, which could inform the development of more efficient and robust neural network architectures.
Technical Explanation
The key idea behind this paper is to analyze the "utilized rank" of the subspaces within neural networks, which refers to the number of dimensions, or directions, that the network actually uses to learn a given task. This is distinct from the total parameter space of the network, which may be much larger.
To measure the utilized rank, the authors developed a novel technique based on the singular value decomposition (SVD) of the network's weight matrices. By analyzing the spectrum of singular values, they were able to determine the effective dimensionality of the subspaces being utilized by the network during training and inference.
The researchers applied this method to various neural network architectures, including fully connected, convolutional, and recurrent networks, trained on different datasets. Their findings revealed several interesting insights:
-
Efficient Utilization of Parameter Space: The utilized rank of the subspaces was often much smaller than the total parameter space of the network, suggesting that neural networks can learn complex tasks by efficiently leveraging only a subset of the available dimensions.
-
Connections to Low-Rank Structures: The authors observed connections between the utilized rank and the emergence of low-rank structures during training, which could have implications for model compression and efficient architecture design.
-
Task-Dependent Utilization: The utilized rank varied depending on the specific task and dataset, indicating that neural networks adapt their internal representations to the requirements of the problem at hand.
These findings contribute to our understanding of the self-organization and representational capabilities of neural networks, and could inform the development of more efficient and robust deep learning models.
Critical Analysis
The paper presents a rigorous and well-designed study, with a clear methodology and a comprehensive set of experiments. The authors' approach to measuring the utilized rank of neural network subspaces is novel and provides valuable insights into the internal representations and efficient utilization of parameter space within these models.
However, it is important to note that the utilized rank is just one aspect of the complex dynamics and structure of neural networks. There may be other important factors, such as the distribution of singular values, the role of skip connections, or the influence of different training regimes, that could further elucidate the underlying mechanisms of neural network learning.
Additionally, the paper focuses primarily on feedforward neural networks, and it would be interesting to see how the utilized rank manifests in more complex architectures, such as transformers or graph neural networks, which have different inductive biases and learning dynamics.
Future research could also explore the potential applications of the utilized rank concept, such as in the development of more efficient and robust neural network architectures, model compression techniques, or interpretability methods.
Conclusion
This paper makes a valuable contribution to our understanding of the internal representations and efficient utilization of parameter space within neural networks. By introducing a novel method to measure the utilized rank of subspaces, the authors have uncovered interesting insights about how these powerful models adapt their internal structures to learn complex tasks.
The findings suggest that there may be opportunities to compress or simplify neural networks without significantly impacting their performance, and could inform the development of more efficient and robust architectures. Additionally, the connections between the utilized rank and the low-rank structures that emerge during training open up new avenues for understanding the self-organization and representational capabilities of neural networks.
Overall, this paper provides a valuable contribution to the ongoing effort to uncover the underlying principles and mechanisms that govern the success of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revealing the Utilized Rank of Subspaces of Learning in Neural Networks
Isha Garg, Christian Koguchi, Eshan Verma, Daniel Ulbricht
In this work, we study how well the learned weights of a neural network utilize the space available to them. This notion is related to capacity, but additionally incorporates the interaction of the network architecture with the dataset. Most learned weights appear to be full rank, and are therefore not amenable to low rank decomposition. This deceptively implies that the weights are utilizing the entire space available to them. We propose a simple data-driven transformation that projects the weights onto the subspace where the data and the weight interact. This preserves the functional mapping of the layer and reveals its low rank structure. In our findings, we conclude that most models utilize a fraction of the available space. For instance, for ViTB-16 and ViTL-16 trained on ImageNet, the mean layer utilization is 35% and 20% respectively. Our transformation results in reducing the parameters to 50% and 25% respectively, while resulting in less than 0.2% accuracy drop after fine-tuning. We also show that self-supervised pre-training drives this utilization up to 70%, justifying its suitability for downstream tasks.
Read more7/9/2024

0
On Learnable Parameters of Optimal and Suboptimal Deep Learning Models
Ziwei Zheng, Huizhi Liang, Vaclav Snasel, Vito Latora, Panos Pardalos, Giuseppe Nicosia, Varun Ojha
We scrutinize the structural and operational aspects of deep learning models, particularly focusing on the nuances of learnable parameters (weight) statistics, distribution, node interaction, and visualization. By establishing correlations between variance in weight patterns and overall network performance, we investigate the varying (optimal and suboptimal) performances of various deep-learning models. Our empirical analysis extends across widely recognized datasets such as MNIST, Fashion-MNIST, and CIFAR-10, and various deep learning models such as deep neural networks (DNNs), convolutional neural networks (CNNs), and vision transformer (ViT), enabling us to pinpoint characteristics of learnable parameters that correlate with successful networks. Through extensive experiments on the diverse architectures of deep learning models, we shed light on the critical factors that influence the functionality and efficiency of DNNs. Our findings reveal that successful networks, irrespective of datasets or models, are invariably similar to other successful networks in their converged weights statistics and distribution, while poor-performing networks vary in their weights. In addition, our research shows that the learnable parameters of widely varied deep learning models such as DNN, CNN, and ViT exhibit similar learning characteristics.
Read more8/22/2024
🧠
0
Variation Spaces for Multi-Output Neural Networks: Insights on Multi-Task Learning and Network Compression
Joseph Shenouda, Rahul Parhi, Kangwook Lee, Robert D. Nowak
This paper introduces a novel theoretical framework for the analysis of vector-valued neural networks through the development of vector-valued variation spaces, a new class of reproducing kernel Banach spaces. These spaces emerge from studying the regularization effect of weight decay in training networks with activations like the rectified linear unit (ReLU). This framework offers a deeper understanding of multi-output networks and their function-space characteristics. A key contribution of this work is the development of a representer theorem for the vector-valued variation spaces. This representer theorem establishes that shallow vector-valued neural networks are the solutions to data-fitting problems over these infinite-dimensional spaces, where the network widths are bounded by the square of the number of training data. This observation reveals that the norm associated with these vector-valued variation spaces encourages the learning of features that are useful for multiple tasks, shedding new light on multi-task learning with neural networks. Finally, this paper develops a connection between weight-decay regularization and the multi-task lasso problem. This connection leads to novel bounds for layer widths in deep networks that depend on the intrinsic dimensions of the training data representations. This insight not only deepens the understanding of the deep network architectural requirements, but also yields a simple convex optimization method for deep neural network compression. The performance of this compression procedure is evaluated on various architectures.
Read more7/25/2024
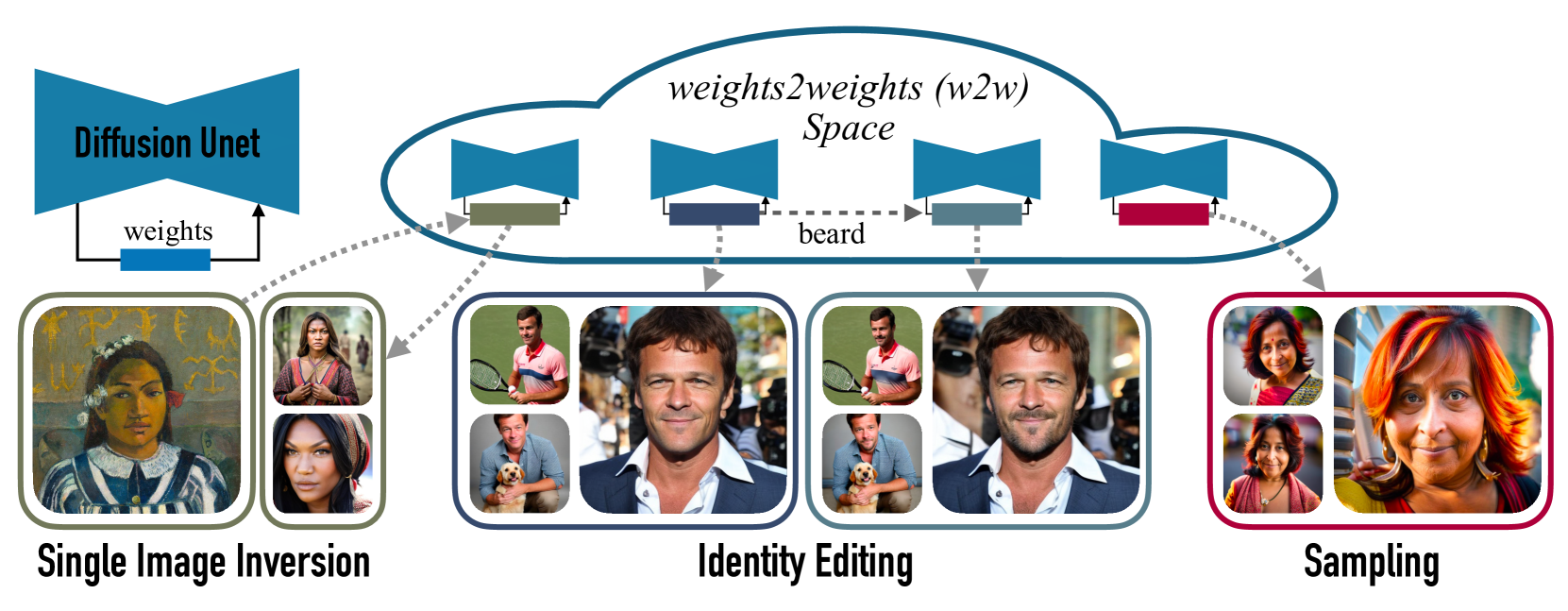
0
Interpreting the Weight Space of Customized Diffusion Models
Amil Dravid, Yossi Gandelsman, Kuan-Chieh Wang, Rameen Abdal, Gordon Wetzstein, Alexei A. Efros, Kfir Aberman
We investigate the space of weights spanned by a large collection of customized diffusion models. We populate this space by creating a dataset of over 60,000 models, each of which is a base model fine-tuned to insert a different person's visual identity. We model the underlying manifold of these weights as a subspace, which we term weights2weights. We demonstrate three immediate applications of this space -- sampling, editing, and inversion. First, as each point in the space corresponds to an identity, sampling a set of weights from it results in a model encoding a novel identity. Next, we find linear directions in this space corresponding to semantic edits of the identity (e.g., adding a beard). These edits persist in appearance across generated samples. Finally, we show that inverting a single image into this space reconstructs a realistic identity, even if the input image is out of distribution (e.g., a painting). Our results indicate that the weight space of fine-tuned diffusion models behaves as an interpretable latent space of identities.
Read more7/19/2024