Revisiting Acoustic Features for Robust ASR

0
Sign in to get full access
Overview
- This paper revisits the use of acoustic features for robust automatic speech recognition (ASR).
- The researchers investigate the performance of various acoustic features, including traditional features and more recent biologically-inspired features, under different noise conditions.
- The goal is to identify acoustic features that can improve the robustness of ASR systems in the face of environmental noise and other adversarial attacks.
Plain English Explanation
The paper focuses on improving the performance of automatic speech recognition (ASR) systems, which are used in a variety of applications like voice assistants and transcription services. One of the key challenges for ASR systems is dealing with background noise or other disturbances that can interfere with the audio signal.
The researchers in this paper looked at different types of acoustic features that can be used as inputs to ASR systems.
They compared traditional acoustic features, like
By understanding which acoustic features work best in noisy environments, the researchers hope to help develop ASR systems that are more reliable and can function well even in challenging real-world conditions, like a loud office or a noisy street. This could improve the performance of voice assistants, speech-to-text transcription, and other applications that rely on accurate speech recognition.
Technical Explanation
The paper explores the performance of various acoustic features for robust automatic speech recognition (ASR) in the presence of noise and adversarial attacks. The researchers investigate the use of traditional acoustic features, such as
The authors conduct experiments on the Aurora-4 and CHiME-5 datasets, which include speech recordings with various types of background noise. They assess the performance of ASR models trained on clean speech and then evaluated on noisy test sets. The researchers also investigate the robustness of the ASR models to
The results show that the biologically-inspired features, particularly Cortical Features, demonstrate superior performance compared to traditional MFCCs under both noisy and adversarial conditions. The authors attribute this to the ability of Cortical Features to better capture the temporal and spectral characteristics of speech, which are crucial for robust ASR.
Additionally, the researchers explore the impact of data augmentation techniques, such as
Critical Analysis
The paper provides a comprehensive evaluation of acoustic features for robust ASR, considering both traditional and biologically-inspired approaches. The authors acknowledge that the performance of the ASR models is heavily dependent on the choice of acoustic features, and their findings highlight the potential advantages of using biologically-inspired features, such as Cortical Features, over traditional MFCCs.
However, the paper does not delve into the computational complexity or real-world implementation challenges associated with the different feature extraction methods. The use of biologically-inspired features may come with increased computational requirements, which could be a concern for deploying ASR systems in resource-constrained environments.
Additionally, the paper focuses on evaluating the robustness of ASR systems to specific types of noise and adversarial attacks, but it does not address the potential for generalization to a wider range of real-world noise conditions. Further research may be needed to assess the resilience of the proposed approaches in more diverse and unpredictable environments.
Another area for potential improvement is the exploration of ensemble or hybrid approaches that combine multiple feature extraction methods, as this could leverage the strengths of different acoustic representations to enhance the overall robustness of the ASR system.
Conclusion
This paper presents a thorough investigation of acoustic features for robust automatic speech recognition, highlighting the potential advantages of biologically-inspired features, particularly Cortical Features, over traditional MFCCs. The findings suggest that the choice of acoustic features is a crucial factor in developing resilient ASR systems that can perform well in the presence of noise and adversarial attacks.
The insights from this research could have significant implications for the development of more reliable and accurate voice-based interfaces, with applications in areas like virtual assistants, speech-to-text transcription, and other voice-controlled systems. By understanding the strengths and limitations of different acoustic features, researchers and engineers can work towards creating ASR systems that are better equipped to handle the challenges of real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revisiting Acoustic Features for Robust ASR
Muhammad A. Shah, Bhiksha Raj
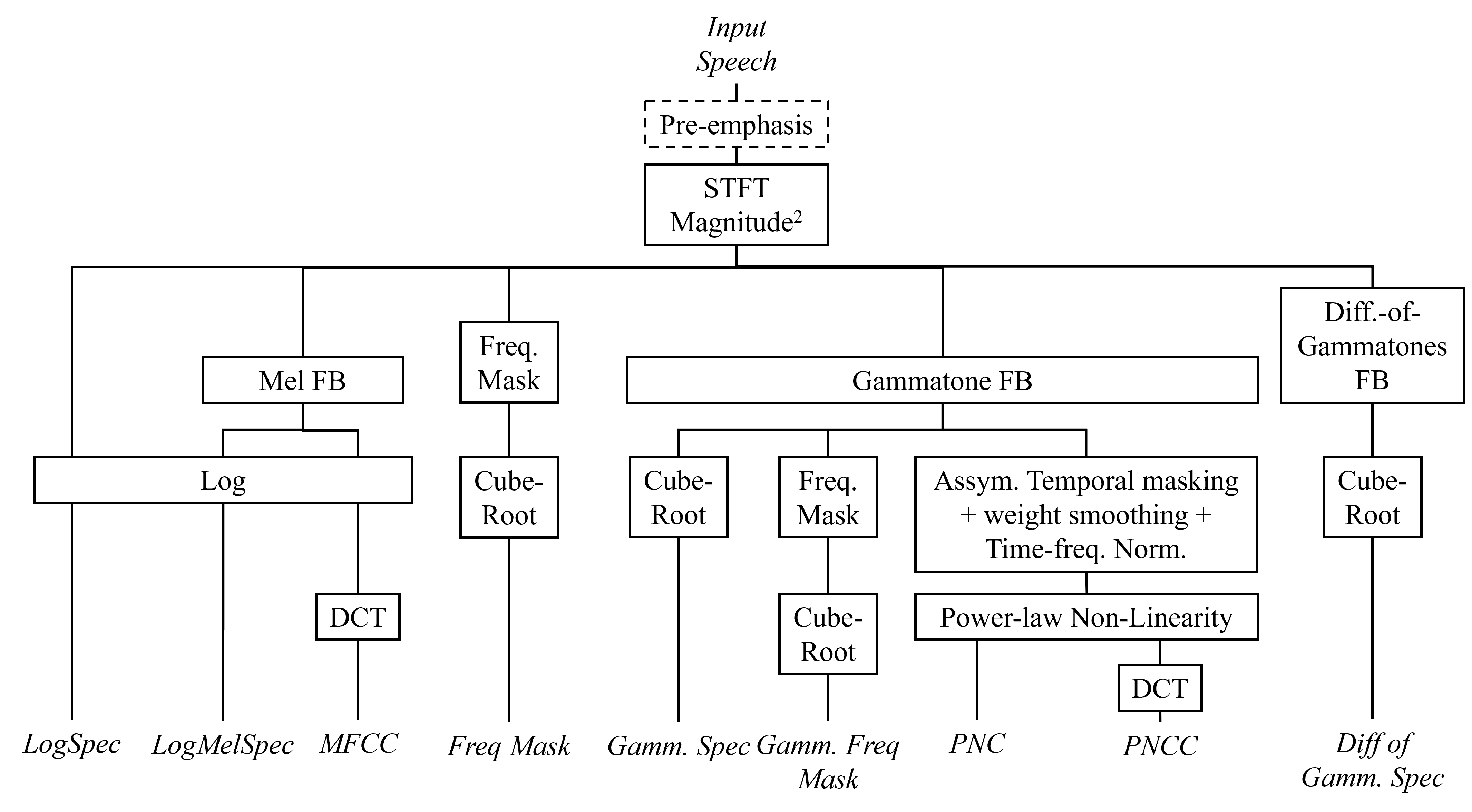
Automatic Speech Recognition (ASR) systems must be robust to the myriad types of noises present in real-world environments including environmental noise, room impulse response, special effects as well as attacks by malicious actors (adversarial attacks). Recent works seek to improve accuracy and robustness by developing novel Deep Neural Networks (DNNs) and curating diverse training datasets for them, while using relatively simple acoustic features. While this approach improves robustness to the types of noise present in the training data, it confers limited robustness against unseen noises and negligible robustness to adversarial attacks. In this paper, we revisit the approach of earlier works that developed acoustic features inspired by biological auditory perception that could be used to perform accurate and robust ASR. In contrast, Specifically, we evaluate the ASR accuracy and robustness of several biologically inspired acoustic features. In addition to several features from prior works, such as gammatone filterbank features (GammSpec), we also propose two new acoustic features called frequency masked spectrogram (FreqMask) and difference of gammatones spectrogram (DoGSpec) to simulate the neuro-psychological phenomena of frequency masking and lateral suppression. Experiments on diverse models and datasets show that (1) DoGSpec achieves significantly better robustness than the highly popular log mel spectrogram (LogMelSpec) with minimal accuracy degradation, and (2) GammSpec achieves better accuracy and robustness to non-adversarial noises from the Speech Robust Bench benchmark, but it is outperformed by DoGSpec against adversarial attacks.
Read more9/26/2024

0
Advanced Framework for Animal Sound Classification With Features Optimization
Qiang Yang, Xiuying Chen, Changsheng Ma, Carlos M. Duarte, Xiangliang Zhang
The automatic classification of animal sounds presents an enduring challenge in bioacoustics, owing to the diverse statistical properties of sound signals, variations in recording equipment, and prevalent low Signal-to-Noise Ratio (SNR) conditions. Deep learning models like Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) have excelled in human speech recognition but have not been effectively tailored to the intricate nature of animal sounds, which exhibit substantial diversity even within the same domain. We propose an automated classification framework applicable to general animal sound classification. Our approach first optimizes audio features from Mel-frequency cepstral coefficients (MFCC) including feature rearrangement and feature reduction. It then uses the optimized features for the deep learning model, i.e., an attention-based Bidirectional LSTM (Bi-LSTM), to extract deep semantic features for sound classification. We also contribute an animal sound benchmark dataset encompassing oceanic animals and birds1. Extensive experimentation with real-world datasets demonstrates that our approach consistently outperforms baseline methods by over 25% in precision, recall, and accuracy, promising advancements in animal sound classification.
Read more7/8/2024
0
Reassessing Noise Augmentation Methods in the Context of Adversarial Speech
Karla Pizzi, Mat'ias P. Pizarro B, Asja Fischer
In this study, we investigate if noise-augmented training can concurrently improve adversarial robustness in automatic speech recognition (ASR) systems. We conduct a comparative analysis of the adversarial robustness of four different state-of-the-art ASR architectures, where each of the ASR architectures is trained under three different augmentation conditions: one subject to background noise, speed variations, and reverberations, another subject to speed variations only, and a third without any form of data augmentation. The results demonstrate that noise augmentation not only improves model performance on noisy speech but also the model's robustness to adversarial attacks.
Read more9/4/2024
0
The Unreliability of Acoustic Systems in Alzheimer's Speech Datasets with Heterogeneous Recording Conditions
Lara Gauder, Pablo Riera, Andrea Slachevsky, Gonzalo Forno, Adolfo M. Garcia, Luciana Ferrer
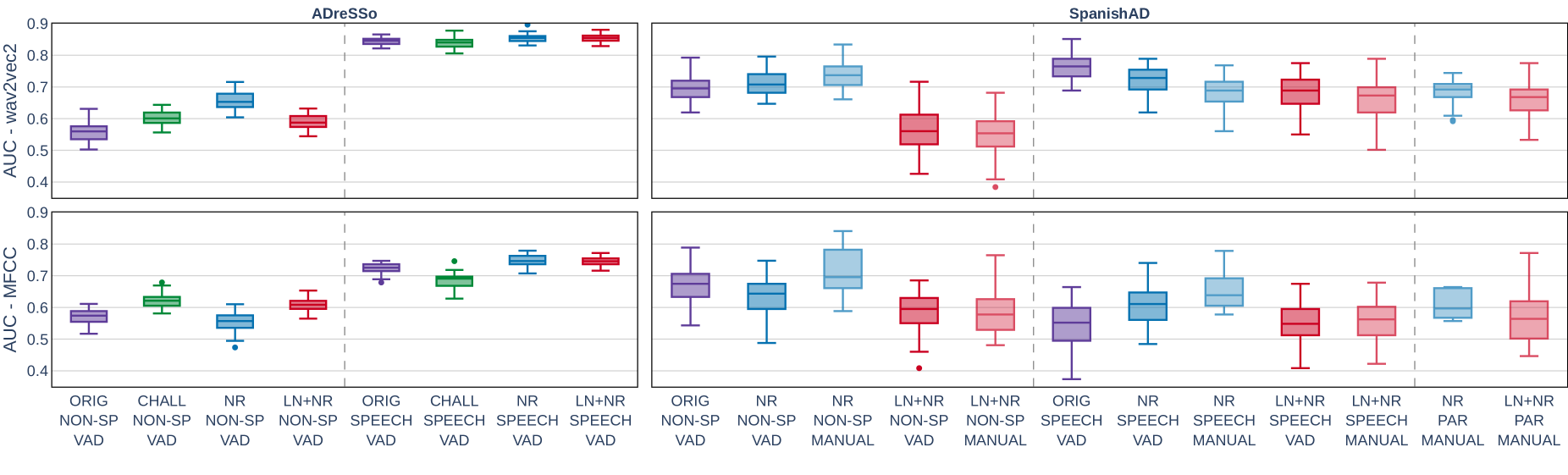
Automated speech analysis is a thriving approach to detect early markers of Alzheimer's disease (AD). Yet, recording conditions in most AD datasets are heterogeneous, with patients and controls often evaluated in different acoustic settings. While this is not a problem for analyses based on speech transcription or features obtained from manual alignment, it does cast serious doubts on the validity of acoustic features, which are strongly influenced by acquisition conditions. We examined this issue in the ADreSSo dataset, derived from the widely used Pitt corpus. We show that systems based on two acoustic features, MFCCs and Wav2vec 2.0 embeddings, can discriminate AD patients from controls with above-chance performance when using only the non-speech part of the audio signals. We replicated this finding in a separate dataset of Spanish speakers. Thus, in these datasets, the class can be partly predicted by recording conditions. Our results are a warning against the use of acoustic systems for identifying patients based on non-standardized recordings. We propose that acoustically heterogeneous datasets for dementia studies should be either (a) analyzed using only transcripts or other features derived from manual annotations, or (b) replaced by datasets collected with strictly controlled acoustic conditions.
Read more9/19/2024