The Unreliability of Acoustic Systems in Alzheimer's Speech Datasets with Heterogeneous Recording Conditions

0
Sign in to get full access
Overview
- Examines the unreliability of acoustic systems in Alzheimer's speech datasets with heterogeneous recording conditions
- Investigates the impact of different recording environments and equipment on the performance of speech-based Alzheimer's detection systems
- Highlights the need for more robust and reliable speech processing techniques to handle the variability in real-world data
Plain English Explanation
The paper focuses on a crucial issue in the field of using speech analysis to detect Alzheimer's disease: the unreliability of acoustic systems when dealing with datasets that have been recorded in diverse conditions.
When collecting speech samples from people with Alzheimer's, the researchers often have to record the data in various settings, such as homes, clinics, or even over the phone. This can lead to significant variability in the audio quality, background noise, and other factors that can affect the performance of the speech processing algorithms used to detect Alzheimer's.
The authors of this paper wanted to investigate how these differences in recording conditions impact the accuracy and reliability of Alzheimer's detection systems. They analyzed several Alzheimer's speech datasets and found that the performance of these systems can vary dramatically depending on the specific characteristics of the recordings.
This is an important finding because it highlights the need for more robust and flexible speech processing techniques that can handle the real-world variability in Alzheimer's speech data. The current approaches, which may work well in controlled laboratory settings, may not be reliable when deployed in the messy, uncontrolled environments where Alzheimer's patients live and communicate.
By addressing this challenge, researchers can develop more accurate and clinically useful Alzheimer's detection tools that can be deployed in a wide range of real-world settings, ultimately improving the quality of care and early intervention for people with this devastating disease.
Technical Explanation
The paper examines the impact of heterogeneous recording conditions on the reliability of acoustic systems for Alzheimer's disease detection. The authors analyzed several Alzheimer's speech datasets, including the ADReSS challenge dataset, the FoG dataset, and the Dementia Bank dataset, which were recorded in diverse environments using different equipment.
The researchers found that the performance of speech-based Alzheimer's detection systems can vary significantly depending on the specific characteristics of the audio recordings. Factors such as background noise, microphone quality, and recording distance all had a substantial impact on the accuracy of the models.
To further investigate this issue, the authors conducted experiments where they trained and tested Alzheimer's detection models on data from the same dataset, but with different recording conditions. They found that the models performed much worse when evaluated on data from a different recording environment than the one they were trained on.
These findings highlight the need for more robust and flexible speech processing techniques that can handle the real-world variability in Alzheimer's speech data. The current approaches, which may work well in controlled laboratory settings, may not be reliable when deployed in the messy, uncontrolled environments where Alzheimer's patients live and communicate.
Critical Analysis
The paper provides valuable insights into a crucial challenge in the field of speech-based Alzheimer's detection: the unreliability of acoustic systems when dealing with heterogeneous recording conditions.
One of the key strengths of the study is the breadth of datasets analyzed, which allowed the authors to uncover the widespread impact of recording variability on Alzheimer's detection performance. The authors also conducted well-designed experiments to isolate the specific effects of different recording factors, which lend credibility to their findings.
However, the paper does not provide detailed information on the specific characteristics of the recording environments and equipment used in each dataset. This makes it difficult to fully understand the nature and extent of the variability encountered. Additionally, the paper does not offer specific recommendations or guidelines for how to address this challenge, beyond the general call for more robust speech processing techniques.
Further research is needed to develop practical solutions that can enable speech-based Alzheimer's detection systems to reliably operate in the real-world environments where patients live and communicate. This may involve exploring techniques such as data augmentation, transfer learning, or domain adaptation to make the models more resilient to recording variability.
Conclusion
This paper highlights a critical issue in the field of speech-based Alzheimer's detection: the unreliability of acoustic systems when dealing with heterogeneous recording conditions. The authors' analysis of multiple Alzheimer's speech datasets reveals that the performance of these systems can vary dramatically depending on the specific characteristics of the audio recordings.
This finding underscores the need for more robust and flexible speech processing techniques that can handle the real-world variability in Alzheimer's speech data. By addressing this challenge, researchers can develop more accurate and clinically useful Alzheimer's detection tools that can be deployed in a wide range of settings, ultimately improving the quality of care and early intervention for people with this devastating disease.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Unreliability of Acoustic Systems in Alzheimer's Speech Datasets with Heterogeneous Recording Conditions
Lara Gauder, Pablo Riera, Andrea Slachevsky, Gonzalo Forno, Adolfo M. Garcia, Luciana Ferrer
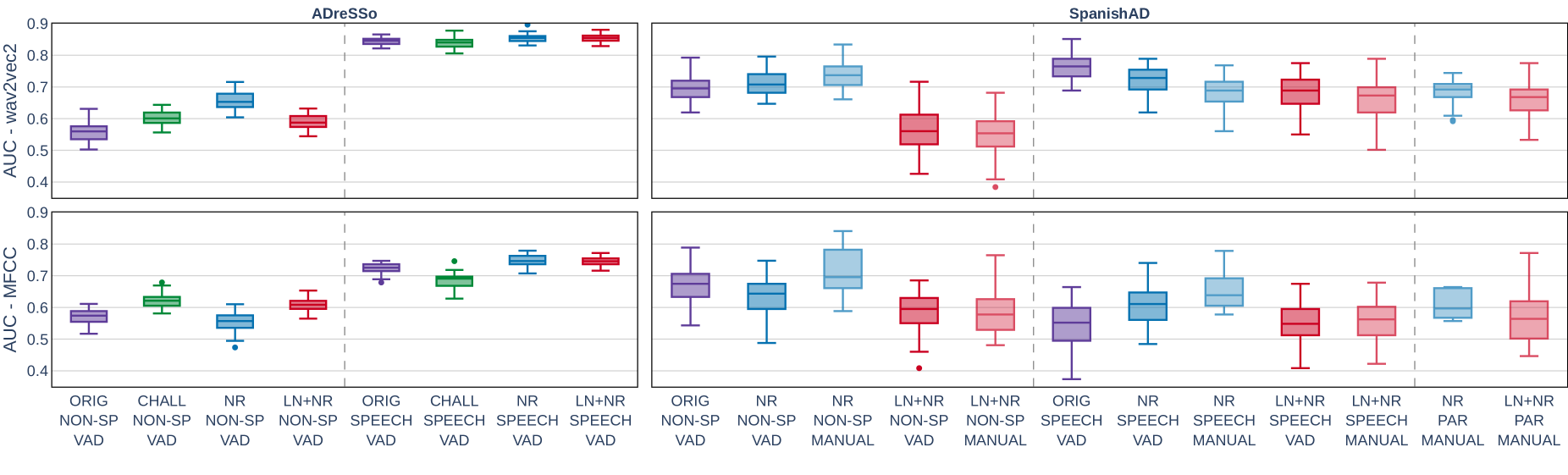
Automated speech analysis is a thriving approach to detect early markers of Alzheimer's disease (AD). Yet, recording conditions in most AD datasets are heterogeneous, with patients and controls often evaluated in different acoustic settings. While this is not a problem for analyses based on speech transcription or features obtained from manual alignment, it does cast serious doubts on the validity of acoustic features, which are strongly influenced by acquisition conditions. We examined this issue in the ADreSSo dataset, derived from the widely used Pitt corpus. We show that systems based on two acoustic features, MFCCs and Wav2vec 2.0 embeddings, can discriminate AD patients from controls with above-chance performance when using only the non-speech part of the audio signals. We replicated this finding in a separate dataset of Spanish speakers. Thus, in these datasets, the class can be partly predicted by recording conditions. Our results are a warning against the use of acoustic systems for identifying patients based on non-standardized recordings. We propose that acoustically heterogeneous datasets for dementia studies should be either (a) analyzed using only transcripts or other features derived from manual annotations, or (b) replaced by datasets collected with strictly controlled acoustic conditions.
Read more9/19/2024

0
Automatic detection of Mild Cognitive Impairment using high-dimensional acoustic features in spontaneous speech
Cong Zhang, Wenxing Guo, Hongsheng Dai
This study addresses the TAUKADIAL challenge, focusing on the classification of speech from people with Mild Cognitive Impairment (MCI) and neurotypical controls. We conducted three experiments comparing five machine-learning methods: Random Forests, Sparse Logistic Regression, k-Nearest Neighbors, Sparse Support Vector Machine, and Decision Tree, utilizing 1076 acoustic features automatically extracted using openSMILE. In Experiment 1, the entire dataset was used to train a language-agnostic model. Experiment 2 introduced a language detection step, leading to separate model training for each language. Experiment 3 further enhanced the language-agnostic model from Experiment 1, with a specific focus on evaluating the robustness of the models using out-of-sample test data. Across all three experiments, results consistently favored models capable of handling high-dimensional data, such as Random Forest and Sparse Logistic Regression, in classifying speech from MCI and controls.
Read more8/30/2024

0
Homogeneous Speaker Features for On-the-Fly Dysarthric and Elderly Speaker Adaptation
Mengzhe Geng, Xurong Xie, Jiajun Deng, Zengrui Jin, Guinan Li, Tianzi Wang, Shujie Hu, Zhaoqing Li, Helen Meng, Xunying Liu
The application of data-intensive automatic speech recognition (ASR) technologies to dysarthric and elderly adult speech is confronted by their mismatch against healthy and nonaged voices, data scarcity and large speaker-level variability. To this end, this paper proposes two novel data-efficient methods to learn homogeneous dysarthric and elderly speaker-level features for rapid, on-the-fly test-time adaptation of DNN/TDNN and Conformer ASR models. These include: 1) speaker-level variance-regularized spectral basis embedding (VR-SBE) features that exploit a special regularization term to enforce homogeneity of speaker features in adaptation; and 2) feature-based learning hidden unit contributions (f-LHUC) transforms that are conditioned on VR-SBE features. Experiments are conducted on four tasks across two languages: the English UASpeech and TORGO dysarthric speech datasets, the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora. The proposed on-the-fly speaker adaptation techniques consistently outperform baseline iVector and xVector adaptation by statistically significant word or character error rate reductions up to 5.32% absolute (18.57% relative) and batch-mode LHUC speaker adaptation by 2.24% absolute (9.20% relative), while operating with real-time factors speeding up to 33.6 times against xVectors during adaptation. The efficacy of the proposed adaptation techniques is demonstrated in a comparison against current ASR technologies including SSL pre-trained systems on UASpeech, where our best system produces a state-of-the-art WER of 23.33%. Analyses show VR-SBE features and f-LHUC transforms are insensitive to speaker-level data quantity in testtime adaptation. T-SNE visualization reveals they have stronger speaker-level homogeneity than baseline iVectors, xVectors and batch-mode LHUC transforms.
Read more7/10/2024

0
Clever Hans Effect Found in Automatic Detection of Alzheimer's Disease through Speech
Yin-Long Liu, Rui Feng, Jia-Hong Yuan, Zhen-Hua Ling
We uncover an underlying bias present in the audio recordings produced from the picture description task of the Pitt corpus, the largest publicly accessible database for Alzheimer's Disease (AD) detection research. Even by solely utilizing the silent segments of these audio recordings, we achieve nearly 100% accuracy in AD detection. However, employing the same methods to other datasets and preprocessed Pitt recordings results in typical levels (approximately 80%) of AD detection accuracy. These results demonstrate a Clever Hans effect in AD detection on the Pitt corpus. Our findings emphasize the crucial importance of maintaining vigilance regarding inherent biases in datasets utilized for training deep learning models, and highlight the necessity for a better understanding of the models' performance.
Read more6/12/2024