Revisiting Attention Weights as Interpretations of Message-Passing Neural Networks

0

Sign in to get full access
Overview
- This paper revisits the interpretation of attention weights in message-passing neural networks (MPNNs), which are a class of graph neural networks.
- The authors argue that attention weights in MPNNs do not always provide a reliable interpretation of the relative importance of messages passed between nodes.
- They propose a new method to better understand the learned attention weights and their relationship to the underlying message-passing mechanism.
Plain English Explanation
The paper is about a type of artificial intelligence model called a message-passing neural network (MPNN). These models are used to analyze data that can be represented as a graph, with different objects (nodes) connected to each other in various ways.
The key idea behind MPNNs is that each node in the graph can send "messages" to its neighboring nodes, and the model learns to pay attention to the most important messages when making predictions. This "attention" mechanism is meant to help the model focus on the most relevant information.
However, the authors of this paper argue that the attention weights learned by MPNNs don't always accurately reflect the true importance of the messages being passed around. They propose a new method to better understand how the attention mechanism is actually working under the hood.
By taking a closer look at the attention weights, the researchers hope to shed light on how MPNNs are making their decisions, which could lead to more interpretable and trustworthy AI systems in the future.
Technical Explanation
The paper focuses on message-passing neural networks (MPNNs), a class of graph neural networks that learn to represent and reason about data structured as graphs. In MPNNs, each node in the graph iteratively updates its representation by aggregating messages from its neighboring nodes, weighted by an attention mechanism.
The authors argue that the attention weights in MPNNs do not always provide a reliable interpretation of the relative importance of the messages passed between nodes. They propose a new method, called Revisiting Attention Weights as Interpretations of Message-Passing Neural Networks, to better understand the learned attention weights and their relationship to the underlying message-passing mechanism.
The key insights from their analysis include:
- Attention weights can be dominated by the scale of the messages, rather than their semantic importance.
- Attention weights can be highly sensitive to small changes in the input, leading to unreliable interpretations.
- Attention weights may not accurately reflect the long-term influence of a message on the final node representations.
To address these issues, the authors propose an alternative method for interpreting attention weights in MPNNs, which involves analyzing the gradient of the output with respect to the messages. This provides a more reliable way to understand the influence of each message on the final predictions made by the model.
Critical Analysis
The paper raises important concerns about the reliability of using attention weights as a way to interpret the inner workings of message-passing neural networks (MPNNs). The authors provide convincing evidence that attention weights can be misleading, as they may be more reflective of the scale of messages rather than their semantic importance.
This is a significant finding, as attention mechanisms are often touted as a way to make deep learning models more interpretable. The authors' proposed method of analyzing gradient information instead of attention weights seems like a promising alternative, but it remains to be seen how well it will generalize to different MPNN architectures and applications.
One potential limitation of the paper is that it focuses solely on MPNNs, and it's unclear how well the insights would extend to other types of graph neural networks or deep learning models that use attention. Additionally, the authors do not explore the potential impact of their findings on downstream tasks or real-world applications of MPNNs.
Nevertheless, this work is an important contribution to the ongoing discussion around the interpretability of deep learning models. By challenging the common assumption that attention weights are a reliable interpretive tool, the authors encourage researchers and practitioners to think more critically about how they interpret the inner workings of their models. This is crucial as AI systems become increasingly powerful and influential in our lives.
Conclusion
This paper presents a critical analysis of the use of attention weights as a way to interpret message-passing neural networks (MPNNs). The authors demonstrate that attention weights do not always provide a reliable indication of the relative importance of the messages being passed between nodes in the graph.
By proposing an alternative method for interpreting attention weights, the researchers hope to improve the transparency and trustworthiness of MPNN models. This is an important step towards developing more interpretable and accountable AI systems, which will be crucial as these technologies become increasingly ubiquitous in our lives.
While the insights are currently limited to the MPNN domain, the broader implications of this work could extend to other deep learning models that rely on attention mechanisms. As such, this paper serves as a valuable contribution to the ongoing efforts to make AI systems more interpretable and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revisiting Attention Weights as Interpretations of Message-Passing Neural Networks
Yong-Min Shin, Siqing Li, Xin Cao, Won-Yong Shin
The self-attention mechanism has been adopted in several widely-used message-passing neural networks (MPNNs) (e.g., GATs), which adaptively controls the amount of information that flows along the edges of the underlying graph. This usage of attention has made such models a baseline for studies on explainable AI (XAI) since interpretations via attention have been popularized in various domains (e.g., natural language processing and computer vision). However, existing studies often use naive calculations to derive attribution scores from attention, and do not take the precise and careful calculation of edge attribution into consideration. In our study, we aim to fill the gap between the widespread usage of attention-enabled MPNNs and their potential in largely under-explored explainability, a topic that has been actively investigated in other areas. To this end, as the first attempt, we formalize the problem of edge attribution from attention weights in GNNs. Then, we propose GATT, an edge attribution calculation method built upon the computation tree. Through comprehensive experiments, we demonstrate the effectiveness of our proposed method when evaluating attributions from GATs. Conversely, we empirically validate that simply averaging attention weights over graph attention layers is insufficient to interpret the GAT model's behavior. Code is publicly available at https://github.com/jordan7186/GAtt/tree/main.
Read more6/10/2024
🌐
0
Neighbor Overlay-Induced Graph Attention Network
Tiqiao Wei, Ye Yuan
Graph neural networks (GNNs) have garnered significant attention due to their ability to represent graph data. Among various GNN variants, graph attention network (GAT) stands out since it is able to dynamically learn the importance of different nodes. However, present GATs heavily rely on the smoothed node features to obtain the attention coefficients rather than graph structural information, which fails to provide crucial contextual cues for node representations. To address this issue, this study proposes a neighbor overlay-induced graph attention network (NO-GAT) with the following two-fold ideas: a) learning favorable structural information, i.e., overlaid neighbors, outside the node feature propagation process from an adjacency matrix; b) injecting the information of overlaid neighbors into the node feature propagation process to compute the attention coefficient jointly. Empirical studies on graph benchmark datasets indicate that the proposed NO-GAT consistently outperforms state-of-the-art models.
Read more8/19/2024

0
Characterizing Massive Activations of Attention Mechanism in Graph Neural Networks
Lorenzo Bini, Marco Sorbi, Stephane Marchand-Maillet
Graph Neural Networks (GNNs) have become increasingly popular for effectively modeling data with graph structures. Recently, attention mechanisms have been integrated into GNNs to improve their ability to capture complex patterns. This paper presents the first comprehensive study revealing a critical, unexplored consequence of this integration: the emergence of Massive Activations (MAs) within attention layers. We introduce a novel method for detecting and analyzing MAs, focusing on edge features in different graph transformer architectures. Our study assesses various GNN models using benchmark datasets, including ZINC, TOX21, and PROTEINS. Key contributions include (1) establishing the direct link between attention mechanisms and MAs generation in GNNs, (2) developing a robust definition and detection method for MAs based on activation ratio distributions, (3) introducing the Explicit Bias Term (EBT) as a potential countermeasure and exploring it as an adversarial framework to assess models robustness based on the presence or absence of MAs. Our findings highlight the prevalence and impact of attention-induced MAs across different architectures, such as GraphTransformer, GraphiT, and SAN. The study reveals the complex interplay between attention mechanisms, model architecture, dataset characteristics, and MAs emergence, providing crucial insights for developing more robust and reliable graph models.
Read more9/25/2024
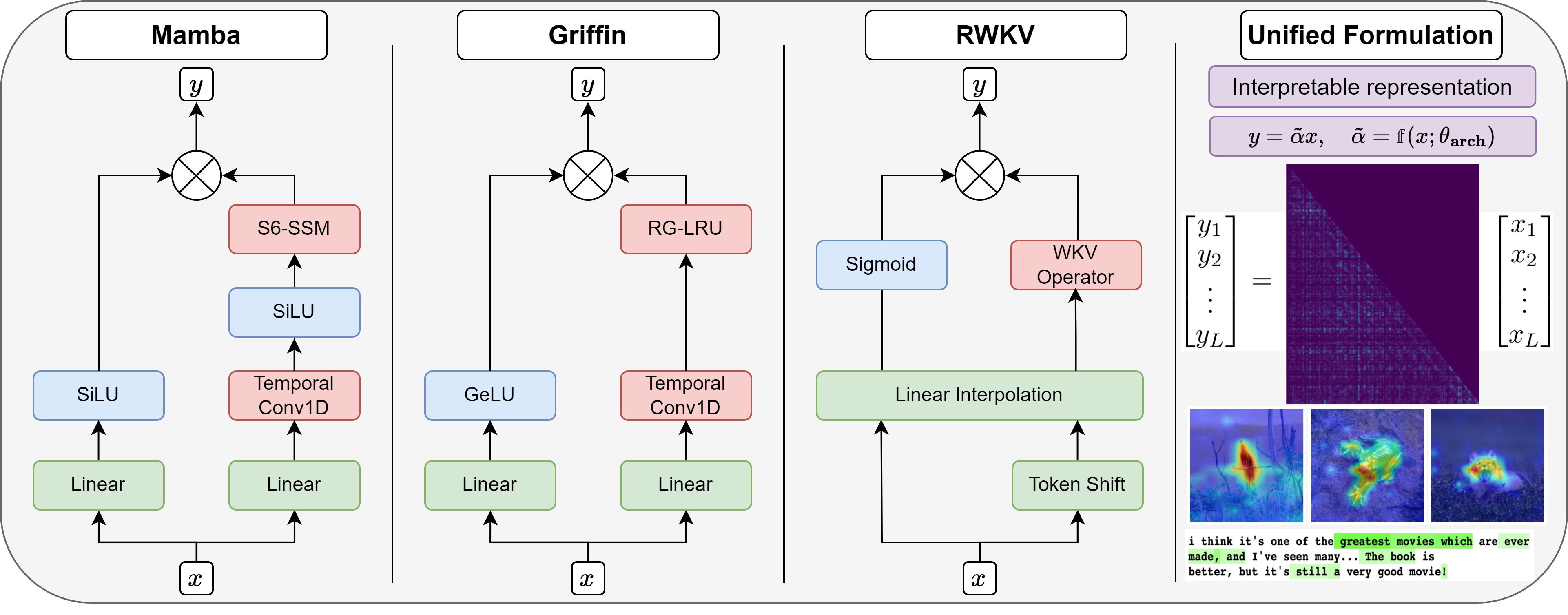
0
A Unified Implicit Attention Formulation for Gated-Linear Recurrent Sequence Models
Itamar Zimerman, Ameen Ali, Lior Wolf
Recent advances in efficient sequence modeling have led to attention-free layers, such as Mamba, RWKV, and various gated RNNs, all featuring sub-quadratic complexity in sequence length and excellent scaling properties, enabling the construction of a new type of foundation models. In this paper, we present a unified view of these models, formulating such layers as implicit causal self-attention layers. The formulation includes most of their sub-components and is not limited to a specific part of the architecture. The framework compares the underlying mechanisms on similar grounds for different layers and provides a direct means for applying explainability methods. Our experiments show that our attention matrices and attribution method outperform an alternative and a more limited formulation that was recently proposed for Mamba. For the other architectures for which our method is the first to provide such a view, our method is effective and competitive in the relevant metrics compared to the results obtained by state-of-the-art transformer explainability methods. Our code is publicly available.
Read more5/28/2024