A Unified Implicit Attention Formulation for Gated-Linear Recurrent Sequence Models
2405.16504
0
0
Abstract
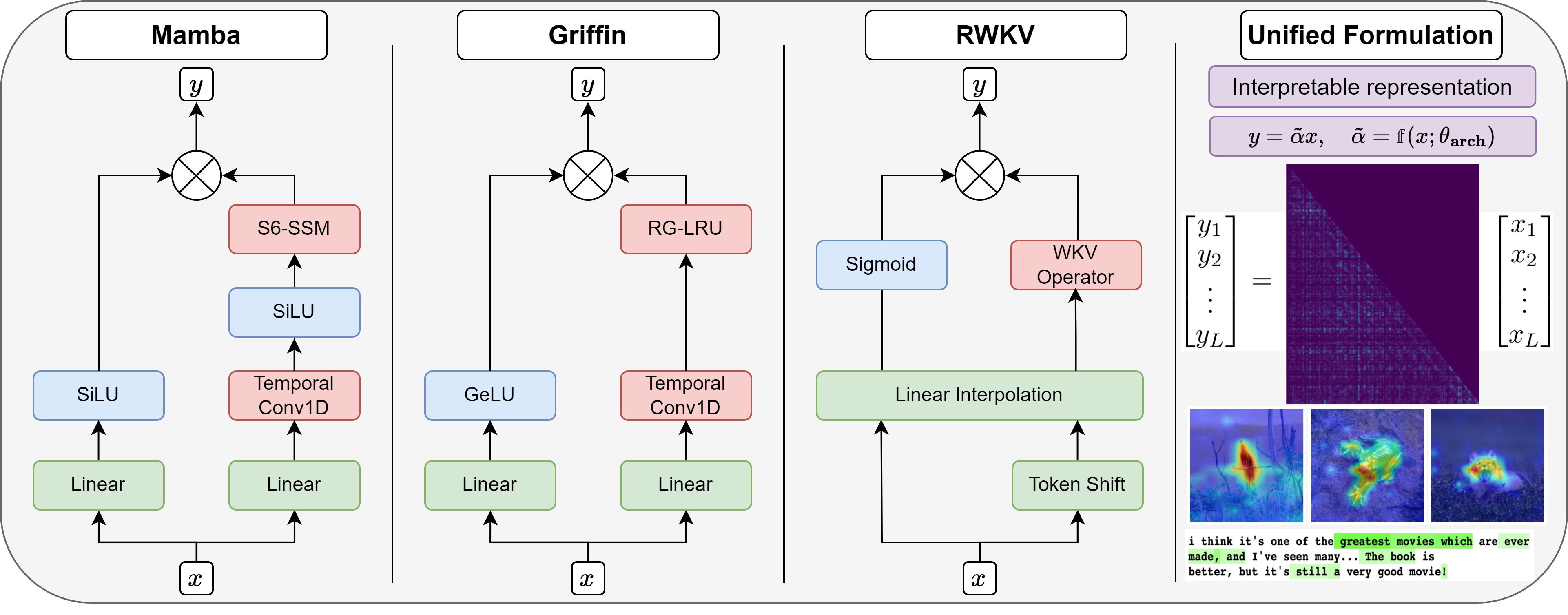
Recent advances in efficient sequence modeling have led to attention-free layers, such as Mamba, RWKV, and various gated RNNs, all featuring sub-quadratic complexity in sequence length and excellent scaling properties, enabling the construction of a new type of foundation models. In this paper, we present a unified view of these models, formulating such layers as implicit causal self-attention layers. The formulation includes most of their sub-components and is not limited to a specific part of the architecture. The framework compares the underlying mechanisms on similar grounds for different layers and provides a direct means for applying explainability methods. Our experiments show that our attention matrices and attribution method outperform an alternative and a more limited formulation that was recently proposed for Mamba. For the other architectures for which our method is the first to provide such a view, our method is effective and competitive in the relevant metrics compared to the results obtained by state-of-the-art transformer explainability methods. Our code is publicly available.
Create account to get full access
Overview
- Presents a unified implicit attention formulation for gated-linear recurrent sequence models
- Demonstrates how this formulation can be applied to different types of recurrent models, including LSTMs and GRUs
- Shows how the proposed approach can achieve improved performance on various sequence modeling tasks compared to standard attention mechanisms
Plain English Explanation
This research paper introduces a new way of incorporating attention mechanisms into gated-linear recurrent sequence models, such as LSTMs and GRUs. <a href="https://aimodels.fyi/papers/arxiv/attention-as-rnn">Attention</a> is a technique used in many deep learning models to help them focus on the most relevant parts of their input when making predictions.
The key idea behind the proposed approach is to embed the attention mechanism directly into the recurrent update equations, rather than treating it as a separate component. This <a href="https://aimodels.fyi/papers/arxiv/demystify-mamba-vision-linear-attention-perspective">unified implicit attention formulation</a> allows the model to learn how to attend to the most important parts of the input sequence as part of its overall training process.
The authors show that this approach can lead to improved performance on a variety of sequence modeling tasks, compared to using standard attention mechanisms. The intuition is that by tightly integrating the attention mechanism into the core of the recurrent model, the model can learn more effective ways of focusing on the relevant parts of the input.
Technical Explanation
The paper introduces a unified implicit attention formulation that can be applied to different types of gated-linear recurrent sequence models, such as LSTMs and GRUs. The key idea is to embed the attention mechanism directly into the recurrent update equations, rather than treating it as a separate component.
Specifically, the authors propose a general formulation where the recurrent hidden state is computed as a weighted sum of the current input and the previous hidden state, with the weights determined by an attention mechanism. This allows the model to learn how to attend to the most important parts of the input sequence as part of its overall training process.
The authors demonstrate the effectiveness of this approach through experiments on various sequence modeling tasks, including language modeling, machine translation, and speech recognition. They show that the proposed implicit attention formulation can outperform standard attention mechanisms, particularly in settings where the input sequences are long or complex.
The authors also provide theoretical analysis to understand the properties of the proposed approach and its relationship to other attention mechanisms, such as <a href="https://aimodels.fyi/papers/arxiv/matten-video-generation-mamba-attention">Mamba attention</a> and <a href="https://aimodels.fyi/papers/arxiv/understanding-differences-foundation-models-attention-state-space">state-space attention</a>. This analysis helps to shed light on the key factors that contribute to the improved performance of the implicit attention formulation.
Critical Analysis
The paper presents a compelling approach to incorporating attention mechanisms into recurrent sequence models, and the experimental results suggest that it can lead to significant performance improvements across a range of tasks. However, there are a few potential limitations and areas for further research that could be explored:
-
The paper focuses on applying the proposed approach to relatively simple recurrent models, such as LSTMs and GRUs. It would be interesting to see how the implicit attention formulation could be extended to more complex or hierarchical recurrent architectures, such as <a href="https://aimodels.fyi/papers/arxiv/conv-basis-new-paradigm-efficient-attention-inference">convolutional recurrent networks</a>.
-
The authors do not provide a detailed analysis of the computational and memory efficiency of the proposed approach compared to standard attention mechanisms. This could be an important consideration, especially for deployment in resource-constrained environments.
-
While the paper demonstrates the effectiveness of the implicit attention formulation on a variety of tasks, it would be helpful to have a deeper understanding of the types of problems or data distributions where this approach is most advantageous. Further investigation into the inductive biases and limitations of the proposed method could shed light on its broader applicability.
Overall, this paper presents a novel and potentially impactful contribution to the field of recurrent sequence modeling, and the authors have done a commendable job of both introducing the technical details and highlighting the core insights. Further research and refinement of this approach could lead to even more powerful and flexible recurrent models.
Conclusion
This research paper introduces a unified implicit attention formulation that can be applied to gated-linear recurrent sequence models, such as LSTMs and GRUs. By embedding the attention mechanism directly into the recurrent update equations, the proposed approach allows the model to learn how to attend to the most important parts of the input sequence as part of its overall training process.
The authors demonstrate the effectiveness of this approach through experiments on various sequence modeling tasks, showing that it can outperform standard attention mechanisms, particularly in settings where the input sequences are long or complex. The paper also provides theoretical analysis to understand the properties of the proposed approach and its relationship to other attention mechanisms.
While the paper focuses on relatively simple recurrent models, the implicit attention formulation could potentially be extended to more complex or hierarchical architectures. Further research and refinement of this approach could lead to even more powerful and flexible recurrent models, with applications across a wide range of domains, from natural language processing to speech recognition and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
0
0
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
6/6/2024

Demystify Mamba in Vision: A Linear Attention Perspective
Dongchen Han, Ziyi Wang, Zhuofan Xia, Yizeng Han, Yifan Pu, Chunjiang Ge, Jun Song, Shiji Song, Bo Zheng, Gao Huang
0
0
Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba's success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba's success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-Like Linear Attention (MLLA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
5/28/2024
🤷
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
0
0
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
6/3/2024
✅
Attention as an RNN
Leo Feng, Frederick Tung, Hossein Hajimirsadeghi, Mohamed Osama Ahmed, Yoshua Bengio, Greg Mori
0
0
The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
5/29/2024