Revolutionizing Traffic Sign Recognition: Unveiling the Potential of Vision Transformers

0
Sign in to get full access
Overview
- Proposes a novel approach to traffic sign recognition using Vision Transformers
- Demonstrates the potential of Vision Transformers to outperform traditional convolutional neural networks in this task
- Explores the benefits of Vision Transformers for autonomous driving applications
Plain English Explanation
This paper explores the use of Vision Transformers for traffic sign recognition, which is an important task for autonomous driving systems. Traditionally, convolutional neural networks (CNNs) have been the dominant approach for this problem, but the researchers believe that Vision Transformers can offer some advantages.
Vision Transformers are a type of deep learning model that uses a transformer architecture, which is based on attention mechanisms, rather than the convolutional layers used in CNNs. The researchers hypothesize that this approach can better capture the global context and long-range dependencies in traffic sign images, leading to improved recognition performance.
To test this, the researchers conducted experiments comparing Vision Transformers to CNNs on standard traffic sign recognition benchmarks. They found that the Vision Transformer models were able to outperform the CNN-based models, demonstrating the potential of this approach for autonomous driving applications.
The key benefits of using Vision Transformers for traffic sign recognition include their ability to better understand the overall context of the image, rather than just local features, and their scalability to larger and more complex datasets. This could enable more robust and reliable traffic sign recognition, which is crucial for the safe operation of self-driving cars.
Technical Explanation
The researchers propose a Vision Transformer-based approach for traffic sign recognition. Vision Transformers are a type of deep learning model that uses a transformer architecture, which is based on attention mechanisms, rather than the convolutional layers used in traditional convolutional neural networks (CNNs).
The key components of the Vision Transformer model include:
- Image Tokenization: The input image is split into a grid of patches, which are then linearly projected into a sequence of embedded tokens.
- Transformer Encoder: The sequence of tokens is then processed by a stack of transformer encoder layers, which use self-attention mechanisms to capture long-range dependencies in the image.
- Classification Head: The final representation from the transformer encoder is passed through a classification head to predict the traffic sign class.
The researchers conducted experiments on standard traffic sign recognition benchmarks, such as the German Traffic Sign Recognition Benchmark (GTSRB) and the Belgium Traffic Sign Classification (BTSC) dataset. They compared the performance of their Vision Transformer-based model to various CNN-based architectures, including state-of-the-art models like EfficientNet and ResNet.
The results showed that the Vision Transformer-based model outperformed the CNN-based models on both datasets, demonstrating the potential of this approach for traffic sign recognition. The researchers attribute the improved performance to the Vision Transformer's ability to better capture the global context and long-range dependencies in the traffic sign images, which are crucial for accurate recognition.
Critical Analysis
The researchers present a compelling case for the use of Vision Transformers in traffic sign recognition, and their experimental results are promising. However, there are a few potential limitations and areas for further research that could be considered:
-
Dataset Size: The experiments were conducted on relatively small, curated datasets, such as GTSRB and BTSC. It would be valuable to evaluate the performance of the Vision Transformer-based model on larger, more diverse datasets that better reflect real-world driving conditions.
-
Real-time Performance: For autonomous driving applications, real-time performance is crucial. The researchers did not provide detailed information on the inference speed and computational requirements of their Vision Transformer-based model, which would be an important consideration for practical deployment.
-
Robustness to Occlusions and Variations: While the Vision Transformer-based model demonstrated improved performance, its robustness to common challenges in traffic sign recognition, such as occlusions, varying lighting conditions, and low-quality images, should be further investigated.
-
Interpretability: Transformer-based models can be more challenging to interpret compared to traditional CNN-based architectures. Exploring techniques to improve the interpretability of the Vision Transformer-based model could enhance trust and transparency in its decision-making process.
Overall, the researchers have presented an innovative approach to traffic sign recognition that shows promise, but additional research and development would be needed to fully realize the potential of Vision Transformers for autonomous driving applications.
Conclusion
This paper proposes a novel approach to traffic sign recognition using Vision Transformers, a type of deep learning model that uses a transformer architecture rather than traditional convolutional neural networks. The researchers' experiments demonstrate that the Vision Transformer-based model can outperform CNN-based models on standard traffic sign recognition benchmarks, highlighting the potential of this approach for autonomous driving applications.
The key advantages of using Vision Transformers for traffic sign recognition include their ability to better capture the global context and long-range dependencies in the images, which are crucial for accurate recognition. This could lead to more robust and reliable traffic sign detection and classification, a critical component for the safe operation of self-driving cars.
While the results are promising, further research is needed to address potential limitations, such as the need for larger and more diverse datasets, real-time performance requirements, and the interpretability of the Vision Transformer-based models. Nonetheless, this work represents an important step forward in the development of advanced computer vision techniques for autonomous driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revolutionizing Traffic Sign Recognition: Unveiling the Potential of Vision Transformers
Susano Mingwin, Yulong Shisu, Yongshuai Wanwag, Sunshin Huing
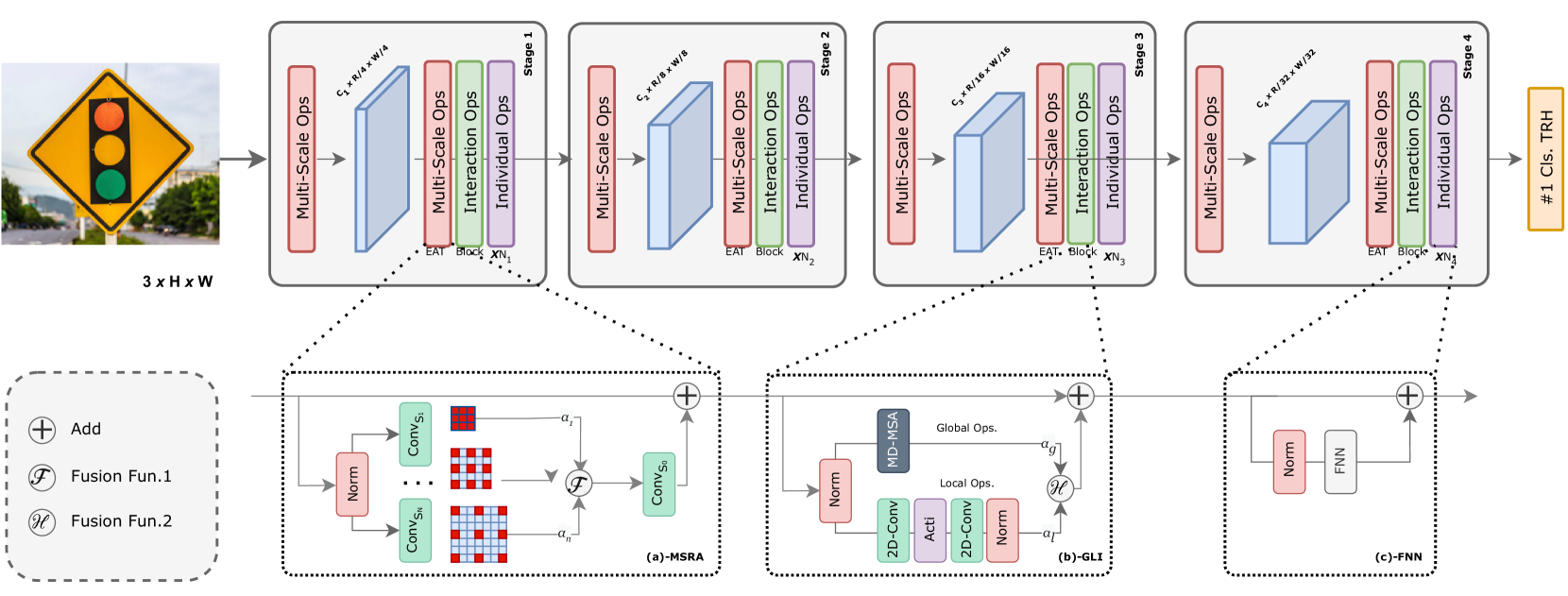
This research introduces an innovative method for Traffic Sign Recognition (TSR) by leveraging deep learning techniques, with a particular emphasis on Vision Transformers. TSR holds a vital role in advancing driver assistance systems and autonomous vehicles. Traditional TSR approaches, reliant on manual feature extraction, have proven to be labor-intensive and costly. Moreover, methods based on shape and color have inherent limitations, including susceptibility to various factors and changes in lighting conditions. This study explores three variants of Vision Transformers (PVT, TNT, LNL) and six convolutional neural networks (AlexNet, ResNet, VGG16, MobileNet, EfficientNet, GoogleNet) as baseline models. To address the shortcomings of traditional methods, a novel pyramid EATFormer backbone is proposed, amalgamating Evolutionary Algorithms (EAs) with the Transformer architecture. The introduced EA-based Transformer block captures multi-scale, interactive, and individual information through its components: Feed-Forward Network, Global and Local Interaction, and Multi-Scale Region Aggregation modules. Furthermore, a Modulated Deformable MSA module is introduced to dynamically model irregular locations. Experimental evaluations on the GTSRB and BelgiumTS datasets demonstrate the efficacy of the proposed approach in enhancing both prediction speed and accuracy. This study concludes that Vision Transformers hold significant promise in traffic sign classification and contributes a fresh algorithmic framework for TSR. These findings set the stage for the development of precise and dependable TSR algorithms, benefiting driver assistance systems and autonomous vehicles.
Read more5/1/2024

0
Cross-domain Few-shot In-context Learning for Enhancing Traffic Sign Recognition
Yaozong Gan, Guang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
Recent multimodal large language models (MLLM) such as GPT-4o and GPT-4v have shown great potential in autonomous driving. In this paper, we propose a cross-domain few-shot in-context learning method based on the MLLM for enhancing traffic sign recognition (TSR). We first construct a traffic sign detection network based on Vision Transformer Adapter and an extraction module to extract traffic signs from the original road images. To reduce the dependence on training data and improve the performance stability of cross-country TSR, we introduce a cross-domain few-shot in-context learning method based on the MLLM. To enhance MLLM's fine-grained recognition ability of traffic signs, the proposed method generates corresponding description texts using template traffic signs. These description texts contain key information about the shape, color, and composition of traffic signs, which can stimulate the ability of MLLM to perceive fine-grained traffic sign categories. By using the description texts, our method reduces the cross-domain differences between template and real traffic signs. Our approach requires only simple and uniform textual indications, without the need for large-scale traffic sign images and labels. We perform comprehensive evaluations on the German traffic sign recognition benchmark dataset, the Belgium traffic sign dataset, and two real-world datasets taken from Japan. The experimental results show that our method significantly enhances the TSR performance.
Read more7/9/2024
👁️
0
Enhancing Traffic Sign Recognition with Tailored Data Augmentation: Addressing Class Imbalance and Instance Scarcity
Ulan Alsiyeu, Zhasdauren Duisebekov
This paper tackles critical challenges in traffic sign recognition (TSR), which is essential for road safety -- specifically, class imbalance and instance scarcity in datasets. We introduce tailored data augmentation techniques, including synthetic image generation, geometric transformations, and a novel obstacle-based augmentation method to enhance dataset quality for improved model robustness and accuracy. Our methodology incorporates diverse augmentation processes to accurately simulate real-world conditions, thereby expanding the training data's variety and representativeness. Our findings demonstrate substantial improvements in TSR models performance, offering significant implications for traffic sign recognition systems. This research not only addresses dataset limitations in TSR but also proposes a model for similar challenges across different regions and applications, marking a step forward in the field of computer vision and traffic sign recognition systems.
Read more6/7/2024
0
Think Twice Before Recognizing: Large Multimodal Models for General Fine-grained Traffic Sign Recognition
Yaozong Gan, Guang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
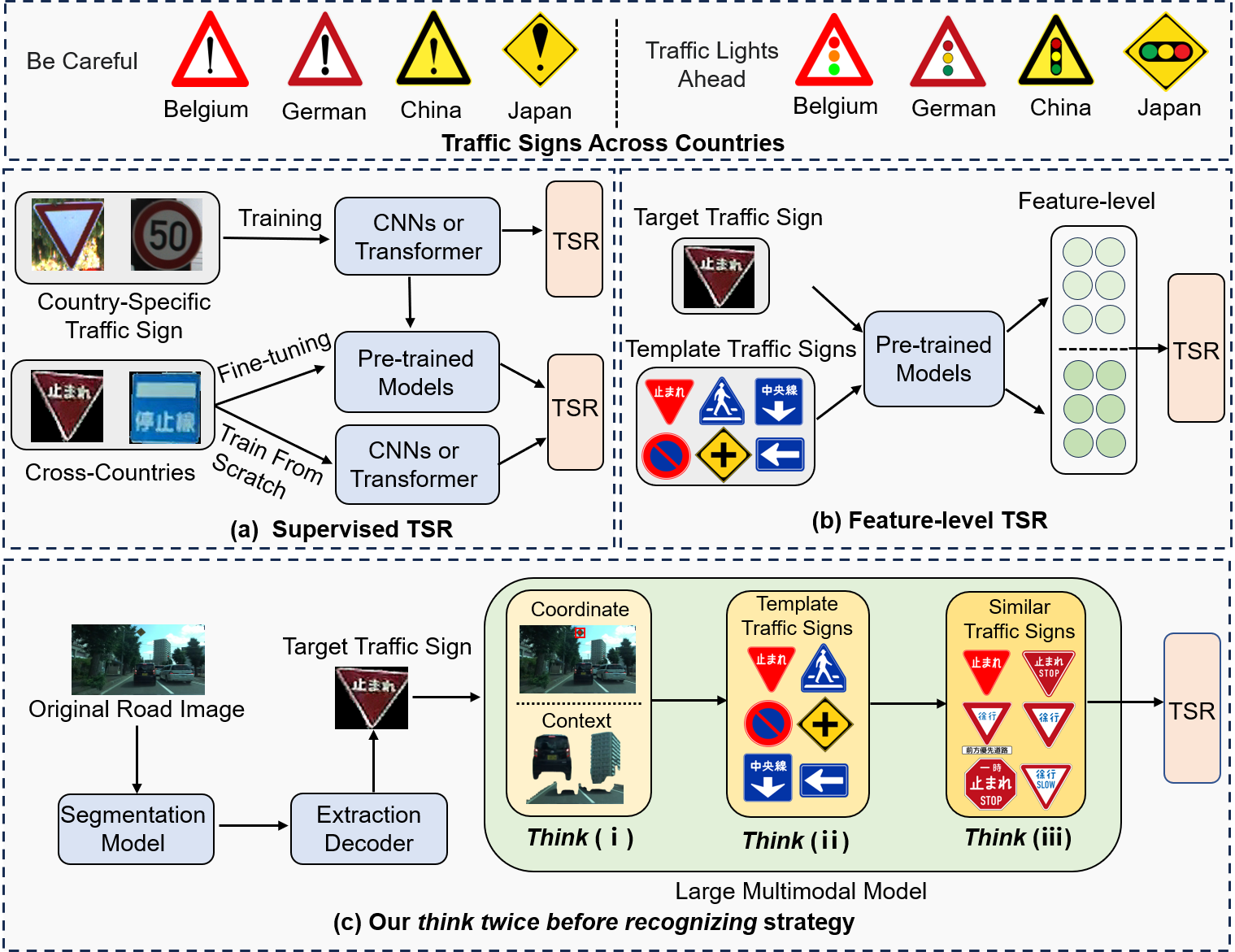
We propose a new strategy called think twice before recognizing to improve fine-grained traffic sign recognition (TSR). Fine-grained TSR in the wild is difficult due to the complex road conditions, and existing approaches particularly struggle with cross-country TSR when data is lacking. Our strategy achieves effective fine-grained TSR by stimulating the multiple-thinking capability of large multimodal models (LMM). We introduce context, characteristic, and differential descriptions to design multiple thinking processes for the LMM. The context descriptions with center coordinate prompt optimization help the LMM to locate the target traffic sign in the original road images containing multiple traffic signs and filter irrelevant answers through the proposed prior traffic sign hypothesis. The characteristic description is based on few-shot in-context learning of template traffic signs, which decreases the cross-domain difference and enhances the fine-grained recognition capability of the LMM. The differential descriptions of similar traffic signs optimize the multimodal thinking capability of the LMM. The proposed method is independent of training data and requires only simple and uniform instructions. We conducted extensive experiments on three benchmark datasets and two real-world datasets from different countries, and the proposed method achieves state-of-the-art TSR results on all five datasets.
Read more9/4/2024