Vision Transformers Need Registers
2309.16588
22
0
👀
Abstract
Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm tokens appearing during inference primarily in low-informative background areas of images, that are repurposed for internal computations. We propose a simple yet effective solution based on providing additional tokens to the input sequence of the Vision Transformer to fill that role. We show that this solution fixes that problem entirely for both supervised and self-supervised models, sets a new state of the art for self-supervised visual models on dense visual prediction tasks, enables object discovery methods with larger models, and most importantly leads to smoother feature maps and attention maps for downstream visual processing.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Transformers have emerged as a powerful tool for learning visual representations
- Researchers identified and characterized artifacts in feature maps of both supervised and self-supervised Vision Transformer (ViT) networks
- These artifacts correspond to high-norm tokens appearing in low-informative background areas during inference, which are repurposed for internal computations
- The researchers propose a simple solution to fix this issue by providing additional tokens to the input sequence of the Vision Transformer
Plain English Explanation
Transformers are a type of machine learning model that have proven to be very effective at learning visual representations from images and other visual data. In this research paper, the authors identify and describe certain "artifacts" or issues that they found in the internal feature maps of both supervised and self-supervised Vision Transformer (ViT) networks.
These artifacts appear as high-magnitude tokens (mathematical representations of visual information) that the model seems to be using for internal computations, even though they are coming from low-informative background areas of the images, rather than the main objects or scenes of interest. The researchers propose a simple solution to this problem - by adding additional "filler" tokens to the input sequence of the Vision Transformer, they are able to eliminate these artifacts entirely, for both supervised and self-supervised models.
This solution not only fixes the issue, but also sets a new state-of-the-art for self-supervised visual models on dense visual prediction tasks. It also enables improved object discovery methods with larger models, and leads to smoother, more intuitive feature maps and attention maps for downstream visual processing.
Technical Explanation
The researchers conducted an in-depth analysis of the feature maps and internal representations learned by both supervised and self-supervised Vision Transformer (ViT) models. They identified the presence of high-norm tokens in the feature maps, particularly in low-informative background areas of the input images, which were being repurposed by the models for internal computations.
To address this issue, the researchers proposed a simple yet effective solution - they added extra "filler" tokens to the input sequence of the ViT models, which gave the models additional capacity to handle background information without repurposing the main visual tokens. This approach was shown to fix the artifact problem entirely for both supervised and self-supervised ViT models.
Furthermore, the researchers demonstrated that this solution enables more efficient and effective ViT models, setting a new state-of-the-art for self-supervised visual models on dense visual prediction tasks. It also improved the performance of object discovery methods when using larger ViT models, and led to smoother feature maps and attention maps that are more intuitive for downstream visual processing tasks.
Critical Analysis
The researchers acknowledge that while their solution is simple and effective, it does not address the underlying cause of the artifact issue in ViT models. They suggest that further research is needed to understand the learning dynamics and correlation structures that lead to these artifacts in the first place.
Additionally, while the proposed solution fixes the artifact problem, it does not necessarily guarantee that the internal representations learned by the models will be optimal for all downstream tasks. There may be other limitations or tradeoffs that were not explored in this study, and further investigation into the impact of the solution on a wider range of applications would be valuable.
Overall, this research provides an important contribution to the understanding and improvement of Vision Transformer models, but there is still room for further exploration and refinement of the techniques used to enhance the efficiency and effectiveness of these powerful visual learning models.
Conclusion
This research paper identifies and addresses a significant issue in the internal representations learned by Vision Transformer models, both supervised and self-supervised. By adding additional "filler" tokens to the input sequence, the researchers were able to eliminate the artifacts in the feature maps, leading to improved performance on dense visual prediction tasks and enabling more effective object discovery methods.
The implications of this work extend beyond the specific models and tasks studied, as it highlights the importance of carefully examining the internal workings of complex machine learning models to identify and address potential issues. As the field of computer vision continues to advance, solutions like the one presented in this paper will be crucial for developing more robust and reliable visual AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
0
0
This paper investigates the effectiveness of self-supervised pre-trained transformers compared to supervised pre-trained transformers and conventional neural networks (ConvNets) for detecting various types of deepfakes. We focus on their potential for improved generalization, particularly when training data is limited. Despite the notable success of large vision-language models utilizing transformer architectures in various tasks, including zero-shot and few-shot learning, the deepfake detection community has still shown some reluctance to adopt pre-trained vision transformers (ViTs), especially large ones, as feature extractors. One concern is their perceived excessive capacity, which often demands extensive data, and the resulting suboptimal generalization when training or fine-tuning data is small or less diverse. This contrasts poorly with ConvNets, which have already established themselves as robust feature extractors. Additionally, training and optimizing transformers from scratch requires significant computational resources, making this accessible primarily to large companies and hindering broader investigation within the academic community. Recent advancements in using self-supervised learning (SSL) in transformers, such as DINO and its derivatives, have showcased significant adaptability across diverse vision tasks and possess explicit semantic segmentation capabilities. By leveraging DINO for deepfake detection with modest training data and implementing partial fine-tuning, we observe comparable adaptability to the task and the natural explainability of the detection result via the attention mechanism. Moreover, partial fine-tuning of transformers for deepfake detection offers a more resource-efficient alternative, requiring significantly fewer computational resources.
5/2/2024
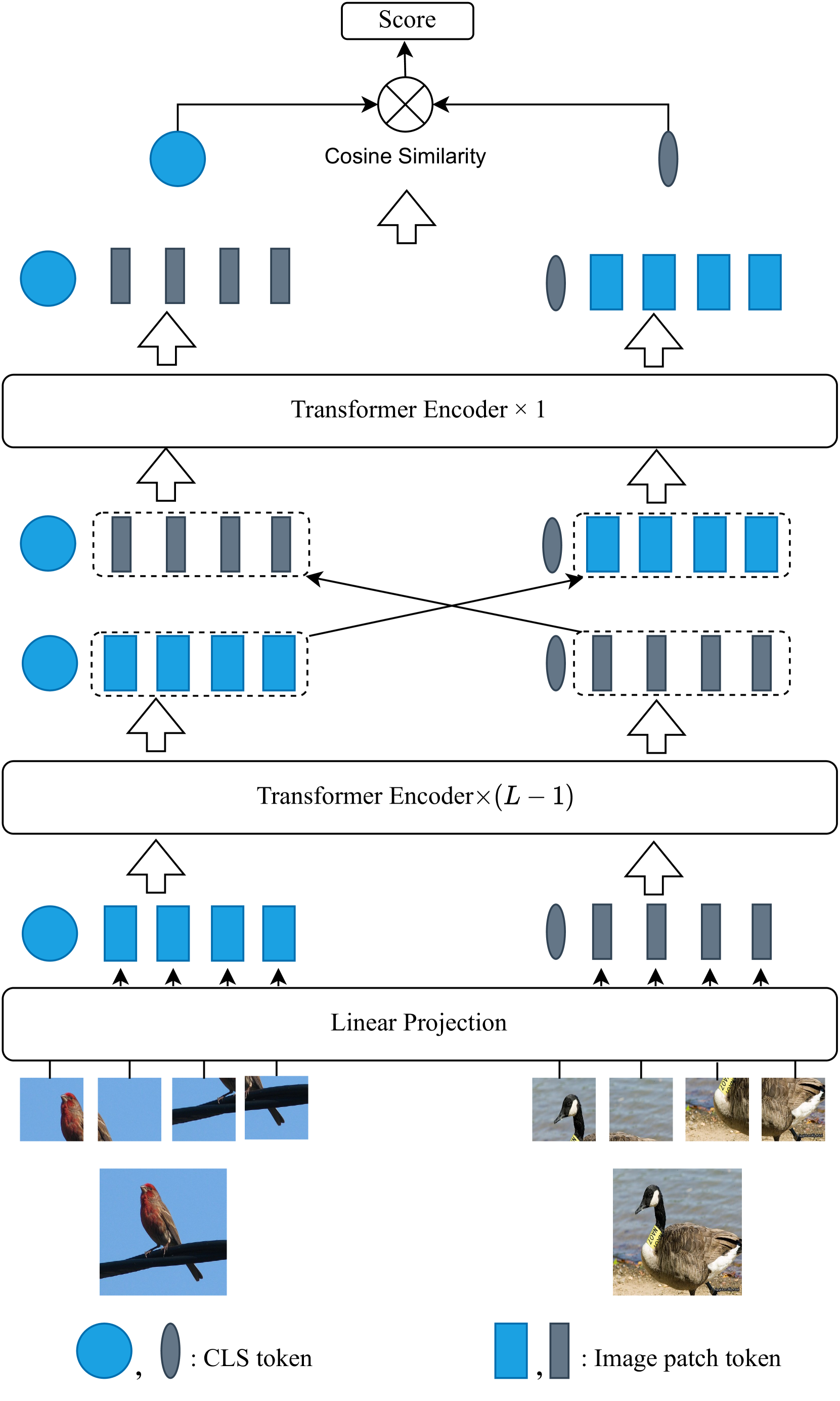
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024
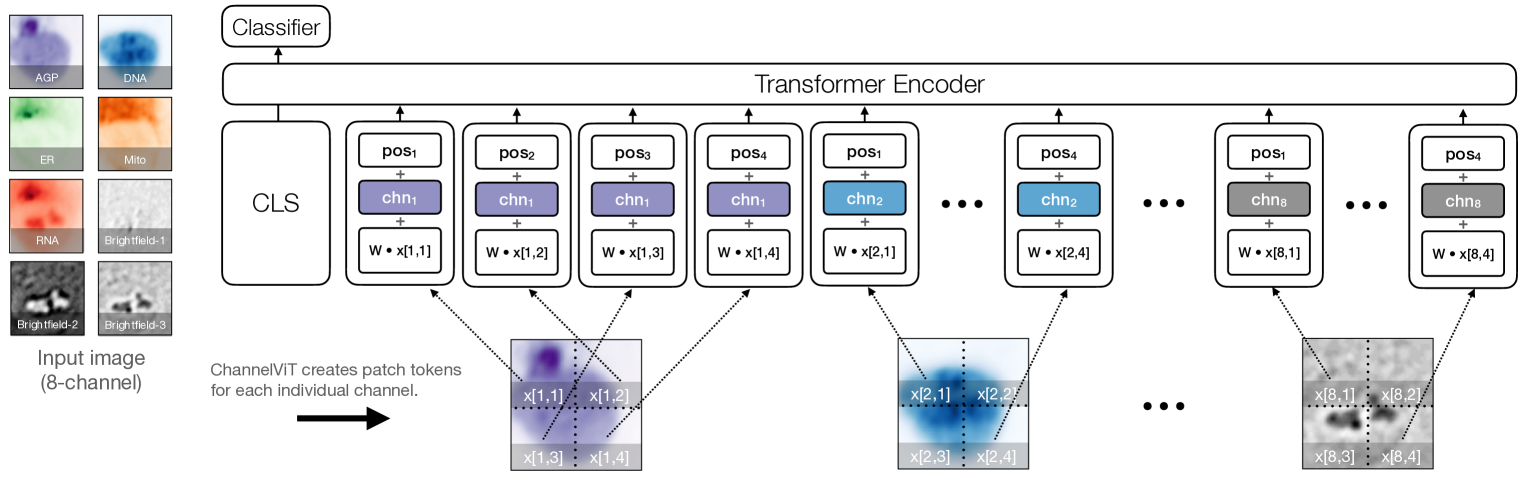
Channel Vision Transformers: An Image Is Worth 1 x 16 x 16 Words
Yujia Bao, Srinivasan Sivanandan, Theofanis Karaletsos
0
0
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
4/22/2024

Sub-token ViT Embedding via Stochastic Resonance Transformers
Dong Lao, Yangchao Wu, Tian Yu Liu, Alex Wong, Stefano Soatto
0
0
Vision Transformer (ViT) architectures represent images as collections of high-dimensional vectorized tokens, each corresponding to a rectangular non-overlapping patch. This representation trades spatial granularity for embedding dimensionality, and results in semantically rich but spatially coarsely quantized feature maps. In order to retrieve spatial details beneficial to fine-grained inference tasks we propose a training-free method inspired by stochastic resonance. Specifically, we perform sub-token spatial transformations to the input data, and aggregate the resulting ViT features after applying the inverse transformation. The resulting Stochastic Resonance Transformer (SRT) retains the rich semantic information of the original representation, but grounds it on a finer-scale spatial domain, partly mitigating the coarse effect of spatial tokenization. SRT is applicable across any layer of any ViT architecture, consistently boosting performance on several tasks including segmentation, classification, depth estimation, and others by up to 14.9% without the need for any fine-tuning.
5/8/2024