RFLPA: A Robust Federated Learning Framework against Poisoning Attacks with Secure Aggregation

0
Sign in to get full access
Overview
- Presents a robust federated learning framework called RFLPA that is resistant to poisoning attacks and uses secure aggregation
- Introduces a novel layer-wise gradient clipping and aggregation scheme to mitigate data poisoning attacks
- Incorporates secure aggregation to protect the privacy of participants' local updates during the federated learning process
Plain English Explanation
RFLPA is a new approach to federated learning, which is a way for machine learning models to be trained across multiple devices or organizations without each party having to share their private data. The key innovation in RFLPA is that it includes mechanisms to make the federated learning process more secure and robust against certain attacks.
One type of attack that can happen in federated learning is called a "poisoning attack," where malicious participants try to corrupt the shared model by submitting bad data or model updates. RFLPA tackles this by using a layer-wise gradient clipping and aggregation scheme to identify and remove potentially malicious updates before they can impact the final model.
The framework also incorporates secure aggregation to protect the privacy of the participants' local model updates, so that their private data is not exposed during the federated learning process. This helps encourage more organizations and individuals to participate in federated learning projects without worrying about their data being accessed by others.
Overall, RFLPA aims to make federated learning a more efficient, private, and attack-resistant way for machine learning models to be trained across distributed data sources.
Technical Explanation
The core of RFLPA is a novel layer-wise gradient clipping and aggregation scheme to mitigate the impact of data poisoning attacks. In each federated learning round, each client computes their local gradient updates and applies a layer-wise L2 norm clipping to them. This helps identify and remove potentially malicious gradients that deviate significantly from the expected range.
The clipped gradients are then securely aggregated using a secure aggregation protocol to protect the privacy of the individual updates. The aggregated gradients are used to update the global model, which is then redistributed to the clients for the next round of training.
The authors demonstrate through extensive experiments on benchmark datasets that RFLPA is effective at defending against a range of poisoning attacks, while maintaining comparable model performance to standard federated learning approaches in the absence of attacks. The precision-guided approach to gradient clipping is a key factor in RFLPA's ability to selectively remove malicious updates without significantly impacting the useful gradients.
Critical Analysis
The authors provide a thorough evaluation of RFLPA's performance against different types of poisoning attacks, including label-flipping, model-replacement, and model-averaging attacks. The results show that RFLPA is effective at mitigating these attacks while maintaining good model performance in the absence of attacks.
However, the paper does not address potential limitations or edge cases of the proposed approach. For example, it's unclear how RFLPA would handle situations where a large proportion of clients are malicious and try to coordinate their attacks. The authors also don't discuss the computational and communication overhead introduced by the secure aggregation and gradient clipping mechanisms.
Additionally, while the secure aggregation protocol helps protect the privacy of individual updates, it's not clear how this would scale to large-scale federated learning systems with thousands or millions of participants. The computational and bandwidth requirements of the secure aggregation protocol may become prohibitive in such scenarios.
Overall, RFLPA represents a promising step towards more robust and private federated learning systems. But further research is needed to address the potential limitations and explore the real-world applicability of the approach at scale.
Conclusion
The RFLPA framework introduces an effective way to defend federated learning systems against poisoning attacks while preserving the privacy of participants. By combining layer-wise gradient clipping and secure aggregation, RFLPA can selectively remove malicious updates without significantly impacting the useful gradients contributed by honest participants.
This approach helps make federated learning a more efficient, private, and attack-resistant solution for training machine learning models across distributed data sources. As federated learning continues to gain traction in real-world applications, techniques like RFLPA will be increasingly important to ensure the security and trustworthiness of the federated learning process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RFLPA: A Robust Federated Learning Framework against Poisoning Attacks with Secure Aggregation
Peihua Mai, Ran Yan, Yan Pang
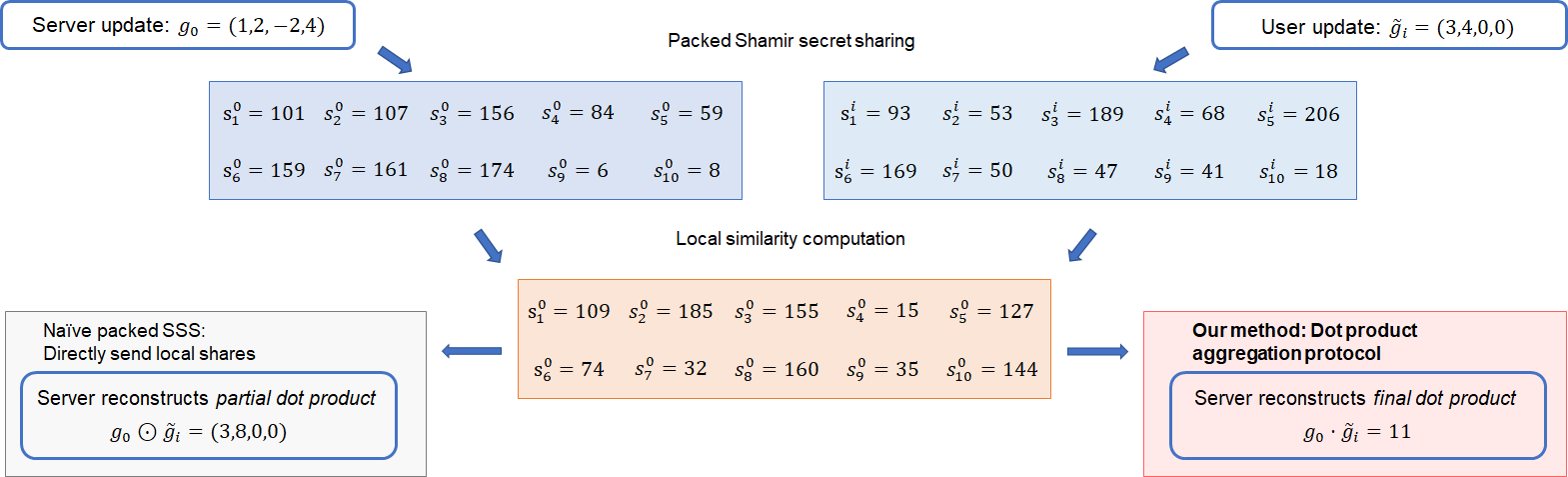
Federated learning (FL) allows multiple devices to train a model collaboratively without sharing their data. Despite its benefits, FL is vulnerable to privacy leakage and poisoning attacks. To address the privacy concern, secure aggregation (SecAgg) is often used to obtain the aggregation of gradients on sever without inspecting individual user updates. Unfortunately, existing defense strategies against poisoning attacks rely on the analysis of local updates in plaintext, making them incompatible with SecAgg. To reconcile the conflicts, we propose a robust federated learning framework against poisoning attacks (RFLPA) based on SecAgg protocol. Our framework computes the cosine similarity between local updates and server updates to conduct robust aggregation. Furthermore, we leverage verifiable packed Shamir secret sharing to achieve reduced communication cost of $O(M+N)$ per user, and design a novel dot-product aggregation algorithm to resolve the issue of increased information leakage. Our experimental results show that RFLPA significantly reduces communication and computation overhead by over $75%$ compared to the state-of-the-art method, BREA, while maintaining competitive accuracy.
Read more5/27/2024
0
Defending Against Sophisticated Poisoning Attacks with RL-based Aggregation in Federated Learning
Yujing Wang, Hainan Zhang, Sijia Wen, Wangjie Qiu, Binghui Guo
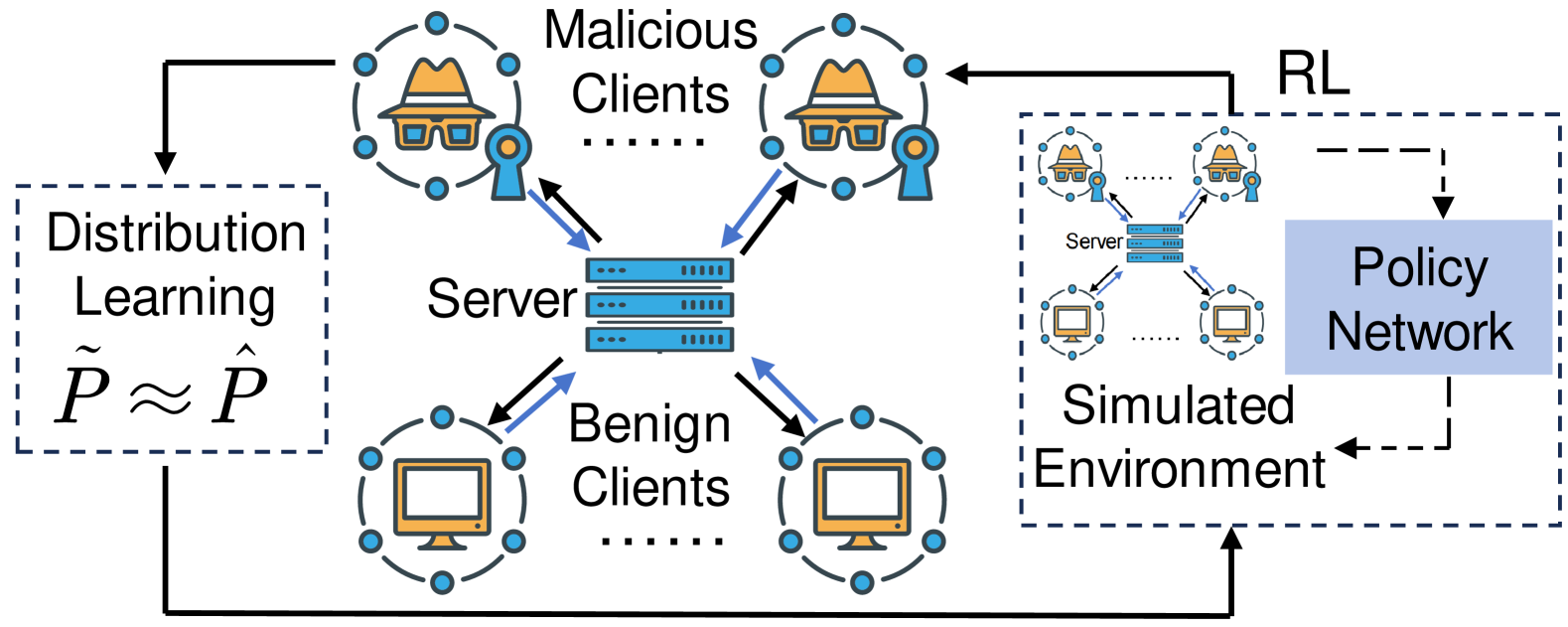
Federated learning is highly susceptible to model poisoning attacks, especially those meticulously crafted for servers. Traditional defense methods mainly focus on updating assessments or robust aggregation against manually crafted myopic attacks. When facing advanced attacks, their defense stability is notably insufficient. Therefore, it is imperative to develop adaptive defenses against such advanced poisoning attacks. We find that benign clients exhibit significantly higher data distribution stability than malicious clients in federated learning in both CV and NLP tasks. Therefore, the malicious clients can be recognized by observing the stability of their data distribution. In this paper, we propose AdaAggRL, an RL-based Adaptive Aggregation method, to defend against sophisticated poisoning attacks. Specifically, we first utilize distribution learning to simulate the clients' data distributions. Then, we use the maximum mean discrepancy (MMD) to calculate the pairwise similarity of the current local model data distribution, its historical data distribution, and global model data distribution. Finally, we use policy learning to adaptively determine the aggregation weights based on the above similarities. Experiments on four real-world datasets demonstrate that the proposed defense model significantly outperforms widely adopted defense models for sophisticated attacks.
Read more6/21/2024

0
ACCESS-FL: Agile Communication and Computation for Efficient Secure Aggregation in Stable Federated Learning Networks
Niousha Nazemi, Omid Tavallaie, Shuaijun Chen, Anna Maria Mandalari, Kanchana Thilakarathna, Ralph Holz, Hamed Haddadi, Albert Y. Zomaya
Federated Learning (FL) is a promising distributed learning framework designed for privacy-aware applications. FL trains models on client devices without sharing the client's data and generates a global model on a server by aggregating model updates. Traditional FL approaches risk exposing sensitive client data when plain model updates are transmitted to the server, making them vulnerable to security threats such as model inversion attacks where the server can infer the client's original training data from monitoring the changes of the trained model in different rounds. Google's Secure Aggregation (SecAgg) protocol addresses this threat by employing a double-masking technique, secret sharing, and cryptography computations in honest-but-curious and adversarial scenarios with client dropouts. However, in scenarios without the presence of an active adversary, the computational and communication cost of SecAgg significantly increases by growing the number of clients. To address this issue, in this paper, we propose ACCESS-FL, a communication-and-computation-efficient secure aggregation method designed for honest-but-curious scenarios in stable FL networks with a limited rate of client dropout. ACCESS-FL reduces the computation/communication cost to a constant level (independent of the network size) by generating shared secrets between only two clients and eliminating the need for double masking, secret sharing, and cryptography computations. To evaluate the performance of ACCESS-FL, we conduct experiments using the MNIST, FMNIST, and CIFAR datasets to verify the performance of our proposed method. The evaluation results demonstrate that our proposed method significantly reduces computation and communication overhead compared to state-of-the-art methods, SecAgg and SecAgg+.
Read more9/6/2024

0
On the Efficiency of Privacy Attacks in Federated Learning
Nawrin Tabassum, Ka-Ho Chow, Xuyu Wang, Wenbin Zhang, Yanzhao Wu
Recent studies have revealed severe privacy risks in federated learning, represented by Gradient Leakage Attacks. However, existing studies mainly aim at increasing the privacy attack success rate and overlook the high computation costs for recovering private data, making the privacy attack impractical in real applications. In this study, we examine privacy attacks from the perspective of efficiency and propose a framework for improving the Efficiency of Privacy Attacks in Federated Learning (EPAFL). We make three novel contributions. First, we systematically evaluate the computational costs for representative privacy attacks in federated learning, which exhibits a high potential to optimize efficiency. Second, we propose three early-stopping techniques to effectively reduce the computational costs of these privacy attacks. Third, we perform experiments on benchmark datasets and show that our proposed method can significantly reduce computational costs and maintain comparable attack success rates for state-of-the-art privacy attacks in federated learning. We provide the codes on GitHub at https://github.com/mlsysx/EPAFL.
Read more4/16/2024