FedLPA: One-shot Federated Learning with Layer-Wise Posterior Aggregation

0
🗣️
Sign in to get full access
Overview
- Federated learning is a technique for training machine learning models on distributed data across multiple devices without sharing the raw data.
- One-shot federated learning, where clients only communicate with the server once, has gained popularity to address privacy concerns and reduce communication overhead.
- However, one-shot aggregation performance is sensitive to non-identical training data distributions, which is common in real-world scenarios.
- The paper proposes a novel one-shot aggregation method called FedLPA that uses layer-wise posterior aggregation to improve learning performance.
Plain English Explanation
FedLPA: One-Shot Federated Learning with Layer-wise Posterior Aggregation aims to address the challenge of training a global machine learning model when the data on local devices is not identically distributed.
In a typical federated learning setup, multiple devices or "clients" each have their own training data, and they collaborate to train a shared global model without directly sharing their private data. This is useful for preserving privacy and reducing communication overhead.
One approach, called "one-shot" federated learning, further reduces communication by only allowing a single round of interaction between the clients and the central server. However, this one-shot aggregation method can struggle when the data on the local clients is very different, a common real-world scenario.
To tackle this issue, the FedLPA method proposed in the paper aggregates the local models in a more sophisticated way. It uses a technique called "layer-wise Laplace approximation" to capture the statistical characteristics of the biased local datasets. This allows FedLPA to combine the local models into a more accurate global model, without requiring additional datasets or exposing private label information.
Experiments show that FedLPA significantly outperforms other state-of-the-art one-shot federated learning methods across various performance metrics. This suggests it is a promising approach for federated learning in real-world applications with non-identical data distributions.
Technical Explanation
The key idea behind FedLPA is to efficiently aggregate the local models by inferring the posteriors of each layer using layer-wise Laplace approximation, and then combining these layer-wise posteriors to obtain the global model parameters.
Specifically, the paper makes the following technical contributions:
-
Layer-wise Posterior Aggregation: Instead of simply averaging the local model weights, FedLPA aggregates the layer-wise posteriors to better capture the statistical characteristics of the biased local datasets. This is done using Laplace approximation to efficiently infer the layer-wise posteriors.
-
No Auxiliary Datasets or Label Exposure: FedLPA achieves this improved aggregation without requiring any additional auxiliary datasets or exposing private label information, such as label distributions, from the local clients.
-
Extensive Experiments: The authors conduct extensive experiments on various benchmark datasets and demonstrate that FedLPA significantly outperforms state-of-the-art one-shot federated learning methods, such as FedAvg, FedBayes, and pFedMe, across several performance metrics.
Critical Analysis
The paper presents a compelling solution to the challenge of one-shot federated learning in the presence of non-identical data distributions. By focusing on layer-wise posterior aggregation, FedLPA is able to better capture the statistical characteristics of the local datasets without requiring additional data or exposing private information.
However, the paper does not discuss the computational complexity of the layer-wise Laplace approximation, which could be a potential limitation for large-scale models or resource-constrained devices. Additionally, the authors do not explore the impact of different model architectures or the scalability of FedLPA to a large number of clients.
Furthermore, while the experiments demonstrate the effectiveness of FedLPA, it would be valuable to see real-world case studies or applications to better understand the practical implications and challenges of deploying such a system.
Conclusion
The FedLPA method proposed in this paper offers a promising solution for one-shot federated learning in the presence of non-identical data distributions. By efficiently aggregating layer-wise posteriors, it is able to improve the performance of the global model without requiring additional data or exposing private information.
The extensive experimental results suggest that FedLPA could be a valuable tool for federated learning applications, particularly in scenarios where preserving privacy and reducing communication overhead are critical. As the field of federated learning continues to evolve, techniques like FedLPA will play an important role in enabling more effective and practical deployment of these distributed learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
FedLPA: One-shot Federated Learning with Layer-Wise Posterior Aggregation
Xiang Liu, Liangxi Liu, Feiyang Ye, Yunheng Shen, Xia Li, Linshan Jiang, Jialin Li
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing communication overhead, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with layer-wise posterior aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any private label information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.
Read more5/22/2024

0
Achieving Byzantine-Resilient Federated Learning via Layer-Adaptive Sparsified Model Aggregation
Jiahao Xu, Zikai Zhang, Rui Hu
Federated Learning (FL) enables multiple clients to collaboratively train a model without sharing their local data. Yet the FL system is vulnerable to well-designed Byzantine attacks, which aim to disrupt the model training process by uploading malicious model updates. Existing robust aggregation rule-based defense methods overlook the diversity of magnitude and direction across different layers of the model updates, resulting in limited robustness performance, particularly in non-IID settings. To address these challenges, we propose the Layer-Adaptive Sparsified Model Aggregation (LASA) approach, which combines pre-aggregation sparsification with layer-wise adaptive aggregation to improve robustness. Specifically, LASA includes a pre-aggregation sparsification module that sparsifies updates from each client before aggregation, reducing the impact of malicious parameters and minimizing the interference from less important parameters for the subsequent filtering process. Based on sparsified updates, a layer-wise adaptive filter then adaptively selects benign layers using both magnitude and direction metrics across all clients for aggregation. We provide the detailed theoretical robustness analysis of LASA and the resilience analysis for the FL integrated with LASA. Extensive experiments are conducted on various IID and non-IID datasets. The numerical results demonstrate the effectiveness of LASA. Code is available at url{https://github.com/JiiahaoXU/LASA}.
Read more9/4/2024
📈
0
Is Aggregation the Only Choice? Federated Learning via Layer-wise Model Recombination
Ming Hu, Zhihao Yue, Xiaofei Xie, Cheng Chen, Yihao Huang, Xian Wei, Xiang Lian, Yang Liu, Mingsong Chen
Although Federated Learning (FL) enables global model training across clients without compromising their raw data, due to the unevenly distributed data among clients, existing Federated Averaging (FedAvg)-based methods suffer from the problem of low inference performance. Specifically, different data distributions among clients lead to various optimization directions of local models. Aggregating local models usually results in a low-generalized global model, which performs worse on most of the clients. To address the above issue, inspired by the observation from a geometric perspective that a well-generalized solution is located in a flat area rather than a sharp area, we propose a novel and heuristic FL paradigm named FedMR (Federated Model Recombination). The goal of FedMR is to guide the recombined models to be trained towards a flat area. Unlike conventional FedAvg-based methods, in FedMR, the cloud server recombines collected local models by shuffling each layer of them to generate multiple recombined models for local training on clients rather than an aggregated global model. Since the area of the flat area is larger than the sharp area, when local models are located in different areas, recombined models have a higher probability of locating in a flat area. When all recombined models are located in the same flat area, they are optimized towards the same direction. We theoretically analyze the convergence of model recombination. Experimental results show that, compared with state-of-the-art FL methods, FedMR can significantly improve the inference accuracy without exposing the privacy of each client.
Read more7/8/2024
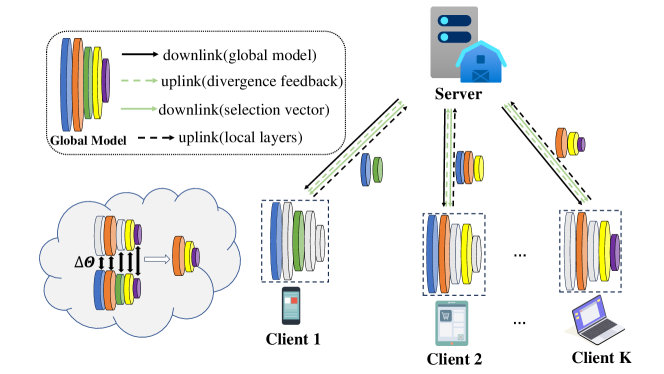
0
Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
Liwei Wang, Jun Li, Wen Chen, Qingqing Wu, Ming Ding
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
Read more4/15/2024